Permutation in String Solution In C++/Java/Python/JS
Problem Description
Given two strings s1 and s2, return true if s2 contains a permutation of s1, or false otherwise.
In other words, return true if one of s1's permutations is the substring of s2.
What is a Permutation?
A permutation of a string is a rearrangement of its characters in every possible order, without adding or removing any character.
You can think of it like shuffling the letters in every possible way, without adding or removing any letter.
Example:
Let's take a very simple string: s = "abc"
All the permutations of "abc" are:
- "abc"
- "acb"
- "bac"
- "bca"
- "cab"
- "cba"
Notice:
- All have the same length as "abc"
- All use the same characters: one 'a', one 'b', and one 'c'
Only the order is different.
What is a Substring?
A substring is a continuous sequence of characters taken from a string, without changing their order.
For example, if the string is "abcde", then "abc", "bcd", and "de" are all valid substrings.
It must be contiguous, meaning we cannot skip characters (e.g., "ace" is not a substring).

Example
Input: s1 = "ab", s2 = "eidbaooo"
Output: true
Explanation: The permutations of "ab" are "ab" and "ba".
If we scan through s2, we find "ba" starting at index 3:
"eid[ba]ooo" → this matches one permutation of "ab", so we return true.
Input: s1 = "ab", s2 = "eidboaoo"
Output: false
Explanation: Permutations of "ab" are "ab" and "ba".
If we scan s2, no 2-letter substring matches either "ab" or "ba". As, no permutation of s1 is found in s2, hence return false.
Input: s1 = "abc", s2 = "ccccbbcaaaa"
Output: true
Explanation: Permutations of "abc" include "abc", "acb", "bac", "bca", "cab", "cba"
If we scan the string "ccccbbcaaaa", we can find "bca" starting at index 5:
"ccccb[bca]aaa" → this is one of the permutations of "abc", so return true.
Constraints
- 1 <= s1.length, s2.length <= 10^4
- s1 and s2 consist of lowercase English letters.
The very first question that comes to our mind after reading the problem is: How can we identify permutations of the string s1 within the main string s2? Most of us already know that one straightforward way is to examine every possible substring of s2 and check if it forms a permutation of s1. To build a solid understanding, let's start by exploring this brute-force approach in detail. This will help us grasp the core concept clearly before moving on to more optimized solutions.
Brute-Force Approach
Intuition
Since we want to check if s2 contains any permutation of s1, the first idea that comes to our mind is to generate all substrings of s2 that are the same length as s1. For example, if s1 has length 3, then we go through s2 and take out all possible substrings of length 3 starting from each index.
Why Exactly Substrings of the Same Length as s1?
A permutation contains exactly the same characters as the original string, with the same frequency, just possibly in a different order. So, if the original string s1 has 3 letters, then any permutation must also have exactly 3 letters — not more, not less. If we check substrings of different lengths, they can't possibly match the character counts of s1. For example, a permutation of "abc" must be exactly 3 characters long and include only one 'a', one 'b', and one 'c', just shuffled.
For this, we can use a nested loop. The outer loop will fix the starting index of the substring, and the inner loop will help us build substrings of the same length as s1 from that starting point in s2.
Generating Substrings of Length s1 Using Nested Loops
To implement this, we first fix the starting index i of the substring in s2 using an outer loop. This loop runs from i = 0 up to i = s2.length() - s1.length(), ensuring that only valid substrings of length equal to s1 are considered.
For each fixed starting index i, we use an inner loop with index j to manually build the substring. This inner loop runs from j = i to j < i + s1.length(). We start with an empty string sub and append characters from s2[j] one by one. This manual construction of substrings helps beginners understand how substrings can be formed using indices, without relying on built-in substring functions.
Note: We can also replace the inner loop with built-in substring methods instead.
Example to Clarify
Suppose s2 = "cbaebabacd" and s1 = "abc", where s1.length() = 3. Using the loops:
- At i = 0, the inner loop collects s2[0], s2[1], s2[2] resulting in substring "cba"
- At i = 1, the inner loop collects s2[1], s2[2], s2[3] resulting in substring "bae"
- At i = 2, the inner loop collects s2[2], s2[3], s2[4] resulting in substring "aeb"
- At i = 3, the inner loop collects s2[3], s2[4], s2[5] resulting in substring "eba"
- At i = 4, the inner loop collects s2[4], s2[5], s2[6] resulting in substring "bab"
- At i = 5, the inner loop collects s2[5], s2[6], s2[7] resulting in substring "aba"
- At i = 6, the inner loop collects s2[6], s2[7], s2[8] resulting in substring "bac"
- At i = 7, the inner loop collects s2[7], s2[8], s2[9] resulting in substring "acd"
Each substring is exactly 3 characters long, matching the length of s1. After extracting these substrings, we can proceed to check if any of them are permutations of s1.
Now, here’s a clever observation: since permutations have the exact same characters with the same frequency, if we sort both the substring and s1, the sorted versions should be exactly the same. For example, "abc", "bca", and "cab" are permutations. When sorted, all become "abc".
- "abc" → sorted → "abc"
- "bca" → sorted → "abc"
- "cab" → sorted → "abc"
So, to check whether a substring is a permutation of s1, we sort both and compare them. If they are equal, then this substring is indeed a permutation of s1.
Approach
Step 1: Sort the Pattern String s1
Before we begin scanning through string s2, we first sort the string s1 and store it in a new string called sortedS1. This sorted version becomes our reference pattern.
Each time we construct a substring from s2, we will sort it and compare it against sortedS1. If they match, that substring is a permutation of s1.
Sorting s1 once in the beginning avoids redundant work and gives us a constant target to compare with during the loop.
Edge Case
If the length of s1 is greater than s2, it is impossible for any permutation of s1 to exist in s2 — because s2 doesn't even have enough characters to form s1.
Checking this upfront helps us exit early, saving time and preventing unneeded comparisons.
It ensures our logic only runs when a valid substring of size s1 can fit inside s2.
Note: Check for this edge case before Step 1
Step 2: Loop Through String s2 to Fix the Starting Index i
We use an outer loop to fix the starting index i for potential substrings in s2 that are the same length as s1.
This loop runs from i = 0 to i <= s2.length() - s1.length(), ensuring that only valid substrings are considered.
At each index i, we will build a substring of length equal to s1 and then check whether it’s a permutation.
Step 3: Use Inner Loop to Manually Construct the Substring
For each starting index i, we initialize an empty string called sub and use another loop with index j to build the substring character by character.
This inner loop runs from j = i to j < i + s1.length(), and we keep appending s2[j] into sub.
This approach avoids built-in substring functions and helps in understanding how substrings can be manually formed using loops and indices.
Step 4: Sort the Constructed Substring and Compare with Sorted s1
Once the substring sub is created, we sort it.
Then we compare it with sortedS1.
If both are equal, it means the substring is a valid permutation of s1 because they contain the exact same characters with the same frequencies.
Step 5: If Match is Found, Return true Immediately
If the sorted substring sub matches sortedS1, we immediately return true.
Since the question only asks whether at least one permutation of s1 exists in s2, we can stop our process as soon as we find the first match.
Step 6: After All Checks, Return false if No Match Found
If we go through all valid substrings in s2 and none of them match sortedS1, we return false.
This means that no permutation of s1 is present in s2.
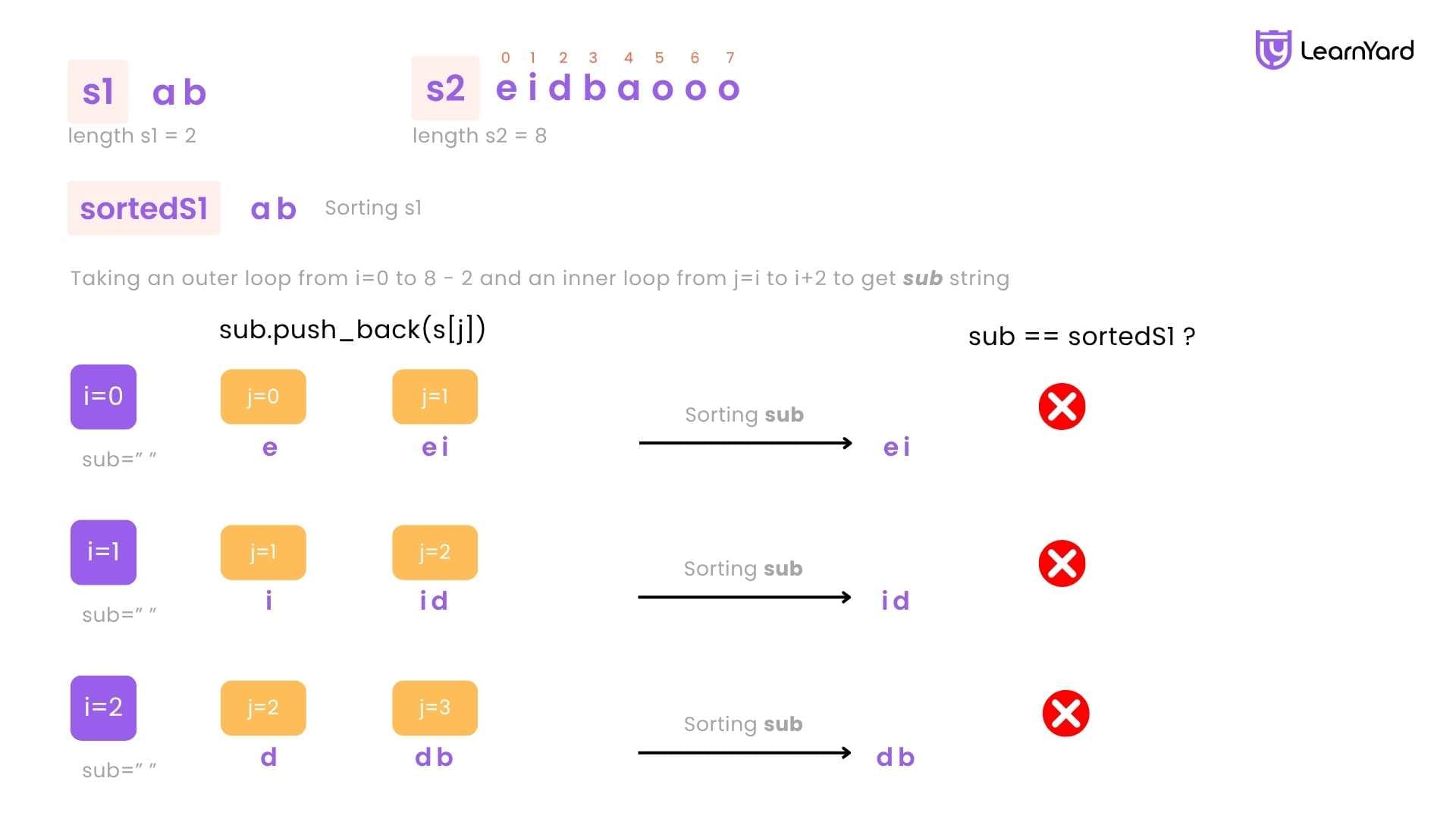
Dry Run
Let's do a detailed dry run of the brute-force approach using nested loops and sorting for the input:
s1 = "ab", s2 = "eidbaooo"
We want to check whether any substring of s2 is a permutation of s1.
Step 1: Preprocessing
We begin by sorting the string s1.
Original s1 = ab
Sorted s1 = ab
This sorted string will act as our reference to check against each substring of s2.
Step 2: Loop Over s2 to Check All Substrings of Length s1.length()
The length of s1 is 2, so we want to extract every substring of s2 that is exactly 2 characters long.
The outer loop will go from: i = 0 to i = s2.length() - s1.length() = 8 - 2 = 6
At each index i, we will:
- Use a nested loop from j = i to j < i + 2 to build the substring manually
- Sort the built substring
- Compare it with the sorted version of s1
Iteration-Wise Dry Run
i = 0
Build substring:
j = 0 → sub = "e"
j = 1 → sub = "ei"
Sorted substring = "ei"
Compare with sorted s1 = "ab" → Not a match → Do not return
i = 1
Build substring:
j = 1 → sub = "i"
j = 2 → sub = "id"
Sorted substring = "di"
Compare with "ab" → Not a match → Do not return
i = 2
Build substring:
j = 2 → sub = "d"
j = 3 → sub = "db"
Sorted substring = "bd"
Compare with "ab" → Not a match → Do not return
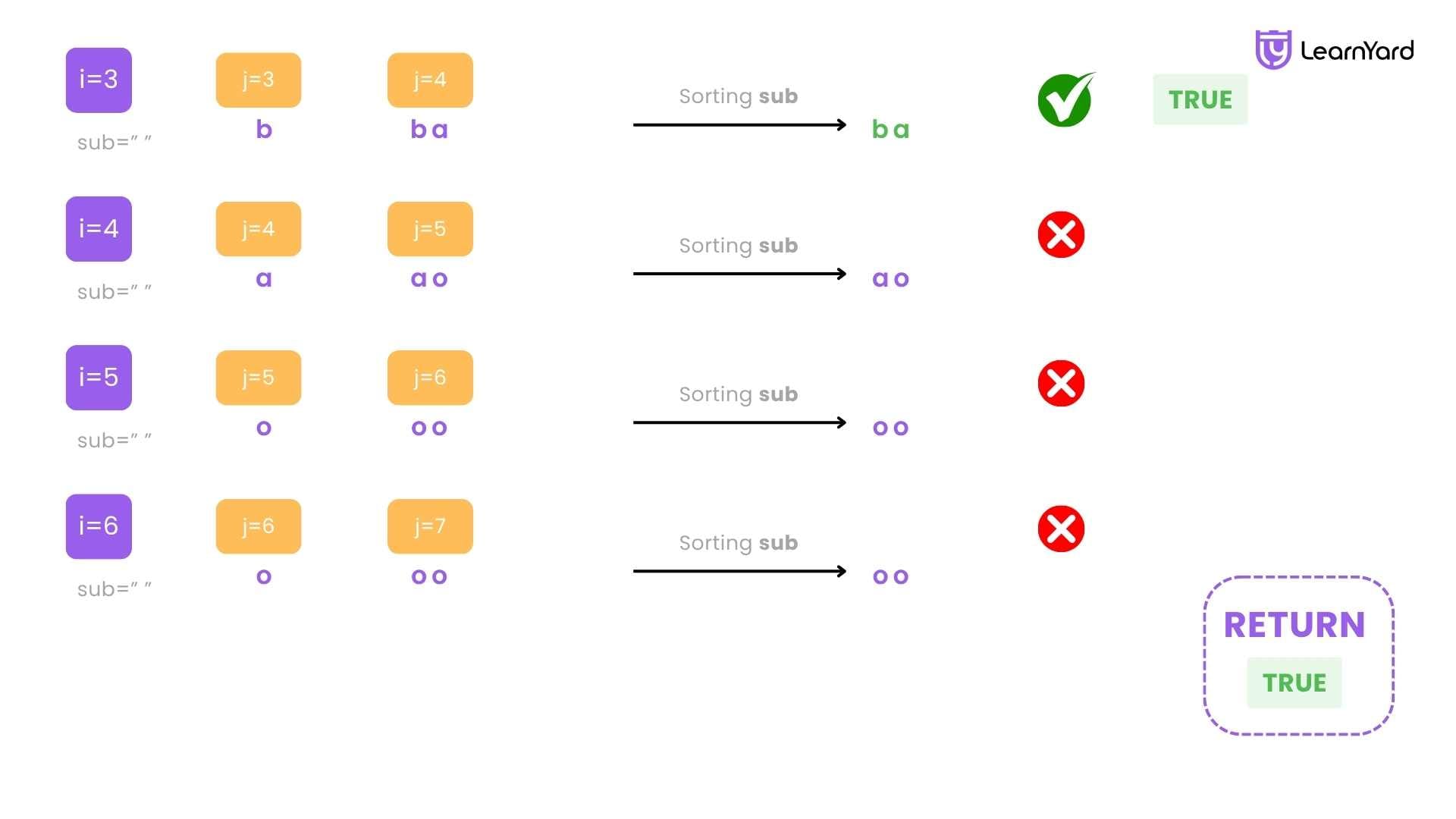
i = 3
Build substring:
j = 3 → sub = "b"
j = 4 → sub = "ba"
Sorted substring = "ab"
Compare with "ab" → Match → Return true
Since we found a match at index 3 (substring "ba" is a permutation of "ab"), we return true immediately without checking further.
Final Result
The substring starting at index 3 in s2 is "ba", which is a valid permutation of s1 = "ab".
So the answer is: true
Explanation: The permutations of "ab" are "ab" and "ba". In s2 = "eidbaooo", we find "ba" starting at index 3: "eid[ba]ooo" → this is a valid match, so we return true
Code for All Languages
C++
#include <iostream> // for cin and cout
#include <string> // for using string
#include <algorithm> // for sort()
using namespace std;
class Solution {
public:
bool checkInclusion(string s1, string s2) {
int len1 = s1.length();
int len2 = s2.length();
// Edge case: if s1 is longer than s2, no permutation is possible
if (len1 > len2) return false;
// Step 1: Sort s1 once since we will compare against it repeatedly
string sortedS1 = s1;
sort(sortedS1.begin(), sortedS1.end());
// Step 2: Iterate over all substrings of s2 of length equal to s1
for (int i = 0; i <= len2 - len1; i++) {
string sub = "";
// Step 3: Manually construct a substring of length s1 starting at index i
for (int j = i; j < i + len1; j++) {
sub.push_back(s2[j]);
}
// Step 4: Sort the constructed substring
sort(sub.begin(), sub.end());
// Step 5: Compare with sorted s1 to check for a permutation match
if (sub == sortedS1) {
return true;
}
}
// Step 6: If no permutation match found in any substring, return false
return false;
}
};
// Driver code
int main() {
string s1, s2;
// Input strings
cin >> s1 >> s2;
Solution sol;
bool result = sol.checkInclusion(s1, s2);
// Output result: true or false
cout << (result ? "true" : "false") << endl;
return 0;
}
Java
import java.util.Scanner; // for input
import java.util.Arrays; // for Arrays.sort()
class Solution {
public boolean checkInclusion(String s1, String s2) {
int len1 = s1.length();
int len2 = s2.length();
// Edge case: if s1 is longer than s2, no permutation is possible
if (len1 > len2) return false;
// Step 1: Sort s1 once since we will compare against it repeatedly
char[] sortedS1 = s1.toCharArray();
Arrays.sort(sortedS1);
String sortedStr1 = new String(sortedS1);
// Step 2: Iterate over all substrings of s2 of length equal to s1
for (int i = 0; i <= len2 - len1; i++) {
String sub = "";
// Step 3: Manually construct a substring of length s1 starting at index i
for (int j = i; j < i + len1; j++) {
sub += s2.charAt(j);
}
// Step 4: Sort the constructed substring
char[] subChars = sub.toCharArray();
Arrays.sort(subChars);
String sortedSub = new String(subChars);
// Step 5: Compare with sorted s1 to check for a permutation match
if (sortedSub.equals(sortedStr1)) {
return true;
}
}
// Step 6: If no permutation match found in any substring, return false
return false;
}
}
// Driver code
public class Main {
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
// Input strings
String s1 = sc.next();
String s2 = sc.next();
Solution sol = new Solution();
boolean result = sol.checkInclusion(s1, s2);
// Output result: true or false
System.out.println(result ? "true" : "false");
}
}
Python
import sys
# Solution class containing the main logic
class Solution:
def checkInclusion(self, s1: str, s2: str) -> bool:
len1 = len(s1)
len2 = len(s2)
# Edge case: if s1 is longer than s2, no permutation is possible
if len1 > len2:
return False
# Step 1: Sort s1 once since we will compare against it repeatedly
sorted_s1 = ''.join(sorted(s1))
# Step 2: Iterate over all substrings of s2 of length equal to s1
for i in range(len2 - len1 + 1):
sub = ""
# Step 3: Manually construct a substring of length s1 starting at index i
for j in range(i, i + len1):
sub += s2[j]
# Step 4: Sort the constructed substring
sorted_sub = ''.join(sorted(sub))
# Step 5: Compare with sorted s1 to check for a permutation match
if sorted_sub == sorted_s1:
return True
# Step 6: If no permutation match found in any substring, return False
return False
# Driver code
if __name__ == "__main__":
# Input strings
s1 = input()
s2 = input()
sol = Solution()
result = sol.checkInclusion(s1, s2)
# Output result: true or false
print("true" if result else "false")
Javascript
/**
* @param {string} s1
* @param {string} s2
* @return {boolean}
*/
var checkInclusion = function(s1, s2) {
let len1 = s1.length;
let len2 = s2.length;
// Edge case: if s1 is longer than s2, no permutation is possible
if (len1 > len2) return false;
// Step 1: Sort s1 once since we will compare against it repeatedly
let sortedS1 = s1.split('').sort().join('');
// Step 2: Iterate over all substrings of s2 of length equal to s1
for (let i = 0; i <= len2 - len1; i++) {
let sub = "";
// Step 3: Manually construct a substring of length s1 starting at index i
for (let j = i; j < i + len1; j++) {
sub += s2[j];
}
// Step 4: Sort the constructed substring
let sortedSub = sub.split('').sort().join('');
// Step 5: Compare with sorted s1 to check for a permutation match
if (sortedSub === sortedS1) {
return true;
}
}
// Step 6: If no permutation match found in any substring, return false
return false;
};
// Driver code
const readline = require("readline");
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout
});
let inputs = [];
rl.on("line", function (line) {
inputs.push(line.trim());
if (inputs.length === 2) {
const s1 = inputs[0];
const s2 = inputs[1];
const result = checkInclusion(s1, s2);
console.log(result ? "true" : "false");
rl.close();
}
});
Time Complexity: O(n * m log m)
Outer Loop: O(n - m + 1)
The outer loop runs from i = 0 to i = s2.length() - s1.length().
Let’s denote:
n = length of the string s2
m = length of the string s1
So, the loop executes approximately (n - m + 1) times, which is O(n) in the worst case.
Inner Loop: O(m)
For each iteration of the outer loop, we manually build a substring of length m using an inner loop that runs from j = i to j < i + m.
This takes O(m) time for each outer loop iteration.
Sorting the Substring: O(m log m)
After building the substring, we sort it using the sort() function.
Sorting a string of length m takes O(m log m) time in the average and worst case.
Comparing with Sorted s1: O(m)
After sorting, we compare the resulting substring with the pre-sorted version of s1.
Since both strings are of length m, this comparison takes O(m) time.
Total Time per Outer Loop Iteration: O(m log m)
Each outer iteration involves:
- Building the substring: O(m)
- Sorting the substring: O(m log m)
- Comparing with sorted s1: O(m)
Total cost per iteration: O(m + m log m + m) = O(m log m)
Final Time Complexity: O(n * m log m)
Since we do O(m log m) work for each of the O(n) starting positions in s2,
the total time complexity becomes: O(n * m log m)
Where:
n = length of the string s2
m = length of the string s1
Space Complexity: O(n + m)
Auxiliary Space Complexity: O(m)
This refers to the extra space used by the algorithm that is independent of the input and output storage.
In our brute-force approach, we create:
- A temporary substring of length m (where m is the length of s1) during each iteration
- A sorted version of this substring
- A sorted version of s1, which is computed once and reused
Since the temporary substring and its sorted version are recreated in each iteration and only exist during that iteration, the auxiliary space remains proportional to m.
No additional data structures are maintained across all iterations.
Therefore, the auxiliary space complexity is O(m).
Total Space Complexity: O(n + m)
This includes the space required for:
- Input space: The two input strings s1 and s2 have lengths m and n, respectively. So, input space is O(n + m).
- Output space: Since we only return a boolean value (true or false), output space is O(1).
- Extra space used by the algorithm: As analyzed above, it is O(m) per iteration, but not accumulated.
Combining all space requirements:
Total Space Complexity = O(n + m) + O(1) + O(m) = O(n + m)
Why this Approach will give TLE?
The main reason this approach is slow and can time out is because of its high time complexity combined with the input size constraints.
According to the constraints:
1 <= s1.length, s2.length <= 10⁴, which means both strings can be as long as 10,000 characters.
Let’s break down why this becomes a problem:
- The outer loop runs from i = 0 to i <= s2.length() - s1.length(), which can be up to n - m + 1 ≈ 10,000 in the worst case.
- Inside each iteration, we:
- Manually construct a substring of length m
- Sort that substring → O(m log m)
- Compare with the sorted version of s1 → O(m)
The dominant cost here is sorting the substring every time.
If m = 10,000, then sorting takes roughly 10,000 log(10,000) ≈ 10,000 * 14 ≈ 140,000 operations
Now multiplying by the number of starting points (≈ n = 10,000) gives:
10,000 * 140,000 = 1,400,000,000 operations
That’s over 1.4 billion operations, which is far too many for a program to run within the time limits of most online judges.
Most competitive programming platforms (like LeetCode, Codeforces, etc.) allow around 1 to 2 seconds per test case, with an average of 10⁷ (10 million) operations per second.
When the number of operations exceeds this range, it results in a Time Limit Exceeded (TLE) error.
We have seen the brute-force solution, which taught us how to check for permutations by sorting. However, sorting each substring costs us O(m log m), which can be quite expensive. Can we do better by leveraging the properties of permutations? Is it possible to eliminate the nested loops and improve the time complexity? Let’s find out as we move on to the optimal approach.
Optimal Approach
Intuition
Let’s pause and reflect on what an permutation really is. A permutation of a string contains exactly the same characters, in exactly the same quantity, just possibly in a different order. For example, "abc", "bca", and "cab" are all permutations of each other. Now think carefully — if order doesn't matter, then comparing sorted strings is just a clever hack to check whether two strings have the same characters. But there’s an even better way: use frequency counting.
Since we’re only dealing with lowercase English letters (a–z), we know there are only 26 characters possible. We can create an array of size 26 to store the frequency of each character also called as a frequency Array.
What is a Frequency Array?
A frequency array is just a way to count how many times each element appears — usually characters in a string or numbers in a specific range.
Think of it as a table or list that keeps track of how often each item shows up.
Why Do We Need It?
In many string or array problems, we often need to know:
- How many times a character appears?
- Are two strings made of the same letters with the same counts? (Anagram check)
- Is a character missing or extra?
A frequency array helps us answer these questions quickly — and more efficiently than using repeated loops or searches.
How Does It Work?
Let’s take a common example: counting the number of times each lowercase letter appears in a string.
There are 26 lowercase letters (a to z), so we prepare an array of size 26.
Each index of this array represents a letter:
- Index 0 for 'a'
- Index 1 for 'b'
… - Index 25 for 'z'
Every time we see a letter, we just increase the count at that index.
Similarly, if we’re working with numbers from 0 to 9, we could use an array of size 10 — each index representing a number.
Example
Suppose we’re given the word: "aabbc"
We create a frequency array of size 26 (for letters ‘a’ to ‘z’), all initialized to 0.
Now we go through the word:
- See 'a' → increase count at index 0 → becomes 1
- See 'a' again → increase count at index 0 → becomes 2
- See 'b' → index 1 → becomes 1
- See 'b' again → index 1 → becomes 2
- See 'c' → index 2 → becomes 1
Final frequency array:
- Index: 0 1 2 3 4 ...
- Letter: a b c d e ...
- Value: 2 2 1 0 0 ...
This tells us:
- 'a' appears 2 times
- 'b' appears 2 times
- 'c' appears 1 time
- Others are not present (0)
What Makes it Powerful?
- Instant access: We can access or update any letter’s count in O(1) time.
- No hash maps needed: For simple problems (especially limited to lowercase letters), we don’t need hash maps or dictionaries.
- Very space-efficient: Just 26 slots to cover all lowercase letters.
So here’s the idea:
First, we count the frequency of characters in s1 and store it as our reference.
Next, we use a sliding window of the same length as s1 to move through s2. For each window (substring), we count its character frequencies.
If the frequency array of the current window matches the frequency array of s1, it means we found a valid permutation of s1 inside s2.
What is Sliding Window Technique?
Imagine you’re looking at a long line of items — like numbers in an array or letters in a string — and you want to examine small parts (subarrays or substrings) of it one at a time.
The Sliding Window Technique helps us do this efficiently, without starting over every time.
Instead of recalculating everything from scratch for each part, we slide a “window” over the data, reusing most of the previous work.
What is a “Window”?
A window is just a small segment or a range within the array or string.
For example:
Let’s say we have this array: arr = [1, 2, 3, 4, 5, 6]
If we want to look at subarrays of size 3:
- First window: [1, 2, 3]
- Next window: [2, 3, 4]
- Then: [3, 4, 5], and so on...
Each time, we just move the window one step forward, dropping the first element and including the next.
Why Do We Use It?
Because it's efficient!
Let’s say we wanted the sum of each window of size 3:
Naive Way (Brute Force):
- For every window, loop through the 3 elements and sum them → O(n * k), where n = length of array, k = window size.
Sliding Window Way:
Sum the first window once. For the next window:
- Subtract the element going out of the window.
- Add the element coming in.
This makes each new window sum in O(1) time → total O(n).
Types of Sliding Windows
There are mainly two types:
1. Fixed-size Sliding Window - Window size stays the same.
2. Variable-size Sliding Window - The window grows or shrinks based on conditions.
In this problem, we are using fixed size Sliding Window as the window size if fixed, i.e. length of p.
Now let’s talk about how to make this process efficient. Build the frequency array for the first window in s2 (first s1.length() characters). After that, instead of recalculating the frequency array from scratch for every new window, we slide the window by just one character at a time. That means:
- We subtract the frequency of the character that is moving out of the window.
- We add the frequency of the character that is coming into the window.
This is extremely efficient because we’re only doing constant time updates to the frequency array — no full rebuilds, no sorting. We’re making O(1) changes as we move from one window to the next.
And comparing the two frequency arrays — the one for p and the current window in s — is also quick. Since the arrays are always of length 26, comparing them takes constant time too.
Approach
Step 1: Initialize Frequency Arrays for s1 and First Window of s2
We create two frequency arrays of size 26 (for all lowercase English letters):
- s1Freq → stores the frequency of characters in s1
- windowFreq → stores the frequency of the current window (substring) in s2
We loop through the first len1 characters (where len1 = s1.length()) and update both arrays:
- For each character in s1, increment its count in s1Freq
- For each character in the first window of s2, increment its count in windowFreq
This sets up the comparison base: we’ll compare each window in s2 with s1Freq.
Edge Case
If the length of s1 is greater than s2, it is impossible for any permutation of s1 to exist in s2 — because s2 doesn't even have enough characters to form s1.
Checking this upfront helps us exit early, saving time and preventing invalid window comparisons.
It ensures our sliding window logic only runs when a valid window of size s1 can fit inside s2.
Note: Check for this edge case before Step 1
Step 2: Compare the First Window
After preparing both frequency arrays, we compare them directly:
- If s1Freq == windowFreq, it means the first window is a permutation of s1
- In this case, return true
This comparison avoids sorting and simply uses direct element-wise matching of frequencies.
Step 3: Slide the Window Across s2
We now slide the window across s2 from index len1 to len2 - 1.
For each step:
- Remove the frequency of the character that goes out of the window (i.e., at index i - len1)
- Add the frequency of the character that comes into the window (i.e., at index i)
- After updating the frequencies, compare windowFreq with s1Freq
If at any point they match, return true, because it means the current window is a permutation of s1.
Step 4: After Sliding, Return false if No Match Found
If we finish sliding through all windows and no match was found:
- It means that no substring of s2 is a permutation of s1
- So, return false
This step confirms that we only return true if at least one valid permutation match is found.
Let us understand this with a video,
Dry Run
Let's do a detailed dry run of the optimized sliding window + frequency array approach for the input:
s1 = "ab", s2 = "eidbaooo"
We want to check whether any substring of s2 is a permutation of s1.
Step 1: Preprocessing - Frequency Arrays
We initialize two frequency arrays of size 26:
- s1Freq → Frequency of characters in s1
- windowFreq → Frequency of characters in current window of s2
We process the first len1 = 2 characters from both strings.
s1 = "ab"
s2 = "eidbaooo"
For s1:
- s1[0] = 'a' → s1Freq[0]++
- s1[1] = 'b' → s1Freq[1]++
→ s1Freq = [1, 1, 0, 0, ..., 0]
For s2 window = "ei":
- s2[0] = 'e' → windowFreq[4]++
- s2[1] = 'i' → windowFreq[8]++
→ windowFreq = [0, 0, 0, 0, 1, 0, ..., 1, ..., 0]
Now, compare s1Freq and windowFreq → Not equal → No match
Step 2: Slide the Window and Compare Frequencies
We start sliding the window from index i = 2 to i = 7
i = 2
- Remove character going out → s2[0] = 'e' → windowFreq[4]--
- Add character coming in → s2[2] = 'd' → windowFreq[3]++
- Updated window = "id"
- windowFreq now reflects "id"
- Compare with s1Freq → Not equal → No match
i = 3
- Remove character going out → s2[1] = 'i' → windowFreq[8]--
- Add character coming in → s2[3] = 'b' → windowFreq[1]++
- Updated window = "db"
- windowFreq now reflects "db"
- Compare with s1Freq → Not equal → No match
i = 4
- Remove character going out → s2[2] = 'd' → windowFreq[3]--
- Add character coming in → s2[4] = 'a' → windowFreq[0]++
- Updated window = "ba"
- windowFreq = [1, 1, 0, 0, ..., 0]
- Compare with s1Freq = [1, 1, 0, 0, ..., 0] → Match found
Return true
Final Result
We found a valid permutation of s1 = "ab" inside s2 = "eidbaooo" starting at index 4 → substring "ba"
So the output is: true
Explanation:
The permutations of "ab" are "ab" and "ba".
In s2 = "eidbaooo", we found "ba" starting at index 3:
"eid[ba]ooo" → this is a valid match, so we return true.
Code for All Languages
C++
#include <iostream> // for cin and cout
#include <string> // for using string
#include <vector> // for frequency arrays
using namespace std;
class Solution {
public:
bool checkInclusion(string s1, string s2) {
int len1 = s1.length();
int len2 = s2.length();
// Edge case: if s1 is longer than s2, no permutation is possible
if (len1 > len2) return false;
// Step 1: Prepare Frequency Arrays for s1 and the first window in s2
vector<int> s1Freq(26, 0);
vector<int> windowFreq(26, 0);
// Initialize frequency arrays with first len1 characters
for (int i = 0; i < len1; i++) {
s1Freq[s1[i] - 'a']++;
windowFreq[s2[i] - 'a']++;
}
// Step 2: Compare first window
if (s1Freq == windowFreq) return true;
// Step 3: Slide the window over s2
for (int i = len1; i < len2; i++) {
// Remove the character going out of the window
windowFreq[s2[i - len1] - 'a']--;
// Add the character coming into the window
windowFreq[s2[i] - 'a']++;
// Compare the current window with s1
if (s1Freq == windowFreq) return true;
}
// If no matching window found
return false;
}
};
// Driver code
int main() {
string s1, s2;
// Input strings
cin >> s1 >> s2;
Solution sol;
bool result = sol.checkInclusion(s1, s2);
// Output result: true or false
cout << (result ? "true" : "false") << endl;
return 0;
}
Java
import java.util.Scanner; // for input
class Solution {
public boolean checkInclusion(String s1, String s2) {
int len1 = s1.length();
int len2 = s2.length();
// Edge case: if s1 is longer than s2, no permutation is possible
if (len1 > len2) return false;
// Step 1: Prepare Frequency Arrays for s1 and the first window in s2
int[] s1Freq = new int[26];
int[] windowFreq = new int[26];
// Initialize frequency arrays with first len1 characters
for (int i = 0; i < len1; i++) {
s1Freq[s1.charAt(i) - 'a']++;
windowFreq[s2.charAt(i) - 'a']++;
}
// Step 2: Compare first window
if (areEqual(s1Freq, windowFreq)) return true;
// Step 3: Slide the window over s2
for (int i = len1; i < len2; i++) {
// Remove the character going out of the window
windowFreq[s2.charAt(i - len1) - 'a']--;
// Add the character coming into the window
windowFreq[s2.charAt(i) - 'a']++;
// Compare the current window with s1
if (areEqual(s1Freq, windowFreq)) return true;
}
// If no matching window found
return false;
}
// Helper function to compare two frequency arrays
private boolean areEqual(int[] a, int[] b) {
for (int i = 0; i < 26; i++) {
if (a[i] != b[i]) return false;
}
return true;
}
// Main method (Driver code)
public static void main(String[] args) {
Scanner sc = new Scanner(System.in);
String s1 = sc.next();
String s2 = sc.next();
Solution sol = new Solution();
boolean result = sol.checkInclusion(s1, s2);
System.out.println(result ? "true" : "false");
}
}Python
import sys
class Solution:
def checkInclusion(self, s1: str, s2: str) -> bool:
len1 = len(s1)
len2 = len(s2)
# Edge case: if s1 is longer than s2, no permutation is possible
if len1 > len2:
return False
# Step 1: Prepare Frequency Arrays for s1 and the first window in s2
s1Freq = [0] * 26
windowFreq = [0] * 26
# Initialize frequency arrays with first len1 characters
for i in range(len1):
s1Freq[ord(s1[i]) - ord('a')] += 1
windowFreq[ord(s2[i]) - ord('a')] += 1
# Step 2: Compare first window
if s1Freq == windowFreq:
return True
# Step 3: Slide the window over s2
for i in range(len1, len2):
# Remove the character going out of the window
windowFreq[ord(s2[i - len1]) - ord('a')] -= 1
# Add the character coming into the window
windowFreq[ord(s2[i]) - ord('a')] += 1
# Compare the current window with s1
if s1Freq == windowFreq:
return True
# If no matching window found
return False
# Driver code
if __name__ == "__main__":
s1 = input()
s2 = input()
sol = Solution()
result = sol.checkInclusion(s1, s2)
print("true" if result else "false")
Javascript
/**
* @param {string} s1
* @param {string} s2
* @return {boolean}
*/
var checkInclusion = function(s1, s2) {
const len1 = s1.length;
const len2 = s2.length;
// Edge case: if s1 is longer than s2, no permutation is possible
if (len1 > len2) return false;
// Step 1: Prepare Frequency Arrays for s1 and the first window in s2
const s1Freq = new Array(26).fill(0);
const windowFreq = new Array(26).fill(0);
for (let i = 0; i < len1; i++) {
s1Freq[s1.charCodeAt(i) - 97]++;
windowFreq[s2.charCodeAt(i) - 97]++;
}
// Step 2: Compare first window
if (areEqual(s1Freq, windowFreq)) return true;
// Step 3: Slide the window over s2
for (let i = len1; i < len2; i++) {
// Remove the character going out of the window
windowFreq[s2.charCodeAt(i - len1) - 97]--;
// Add the character coming into the window
windowFreq[s2.charCodeAt(i) - 97]++;
// Compare the current window with s1
if (areEqual(s1Freq, windowFreq)) return true;
}
// If no matching window found
return false;
};
// Helper function to compare two frequency arrays
function areEqual(a, b) {
for (let i = 0; i < 26; i++) {
if (a[i] !== b[i]) return false;
}
return true;
}
// Driver code (Node.js only)
const readline = require('readline');
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout
});
let inputLines = [];
rl.on('line', function (line) {
inputLines.push(line.trim());
if (inputLines.length === 2) {
const s1 = inputLines[0];
const s2 = inputLines[1];
const result = checkInclusion(s1, s2);
console.log(result ? "true" : "false");
rl.close();
}
});
Time Complexity: O(n)
Initial Setup: O(m)
We initialize two frequency arrays of size 26:
- s1Freq for the pattern string s1
- windowFreq for the first window in s2
We loop through the first m characters of s1 and s2 to fill the frequency arrays.
This takes O(m) time.
First Comparison of Frequency Arrays: O(26)
Before the loop begins, we compare s1Freq and windowFreq once.
Since both are of fixed size 26 (for lowercase letters), the comparison takes O(1) time in practice (O(26)).
Sliding Window Loop: O(n - m)
We slide the window from index i = m to i < n (where n is the length of s2).
In each iteration:
- We remove one character from the window (decrement frequency)
- We add one new character to the window (increment frequency)
- We compare windowFreq with s1Freq
All of these steps are performed on arrays of size 26, so each step costs constant time O(1), including the comparison.
Therefore, the sliding window loop runs for (n - m) iterations and each takes O(1) time.
So the total time for this part is O(n - m).
Final Time Complexity: O(n)
Putting everything together:
- Frequency array initialization: O(m)
- First comparison: O(1)
- Sliding window processing: O(n - m)
So the total time complexity becomes:
O(m + (n - m)) = O(n)
Where:
- n is the length of string s2
- m is the length of string s1
Space Complexity: O(1)
Auxiliary Space Complexity: O(1)
This refers to the extra space used by the algorithm during execution, not including the input and output.
In this approach:
1) We maintain two frequency arrays of size 26
- s1Freq for string s1
- windowFreq for the current window in s2
2) These arrays are fixed in size, regardless of the input length.
Since the frequency arrays have a constant size (26 for lowercase English letters), the auxiliary space used is O(26), which is treated as O(1) in Big-O notation.
Total Space Complexity: O(n + m)
This accounts for:
Input Space: O(n + m)
- The input strings s1 and s2 have lengths m and n respectively
- So the input space required is O(n + m)
Output Space: O(1)
- We return a boolean (true or false) — constant space
Auxiliary Space: O(1)
- As explained above, the two frequency arrays use constant space
Final Total Space = O(n + m) + O(1) + O(1) = O(n + m)
This makes the optimized approach not just time-efficient but also very space-efficient, ideal for large input sizes.
Learning Tip
Now we have successfully tackled this problem, let's try these similar problems.
Given two strings s and p, return an array of all the start indices of p's anagrams in s. You may return the answer in any order.
Given a string s and an integer k, return the maximum number of vowel letters in any substring of s with length k. Vowel letters in English are 'a', 'e', 'i', 'o', and 'u'.