Longest Substring Without Repeating Characters
Problem Description
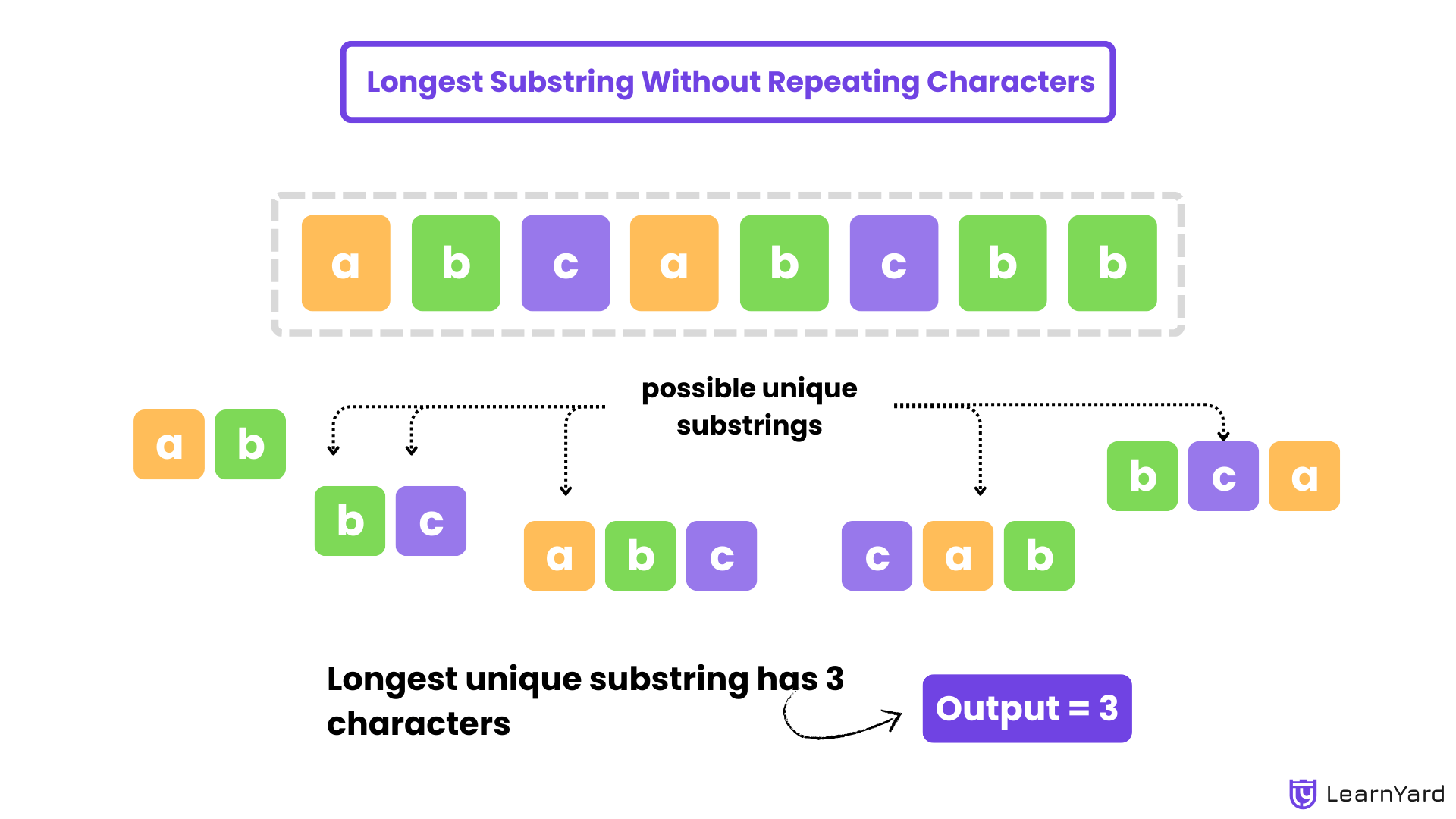
You will be given a string. Find the longest substring of the string s such that each character in that particular substring is unique.
What is a Substring?
A substring is a contiguous sequence of characters within a string. For a string s = "abcdef", a substring must consist of characters that appear consecutively in the original string.
Single-character substrings: "a", "b", "c", "d", "e", "f"
Two-character substrings: "ab", "bc", "cd", "de", "ef"
Three-character substrings: "abc", "bcd", "cde", "def"
Four-character substrings: "abcd", "bcde", "cdef"
Five-character substrings: "abcde", "bcdef"
Six-character substring (the whole string itself): "abcdef"
Invalid Substrings (Non-contiguous sequences):
"acd", "ace", "bac", etc., are not substrings because they skip over characters or mix up the order of characters in s.
Examples of Longest Substring Without Repeating Characters
Input: s = "abcabcbb"
Output: 3
Explanation: The possible substring with unique characters in s is “ab”, “bc”, “abc”, “cab” , “bca”, “bc” , “cb”, etc.
The answer is "abc" with the length of 3 which has unique characters and is the longest substring.
The substring “cab”, “bca” are also accepted solutions.
Input: s = "bbbbb"
Output: 1
Explanation: The only possible substring of s with a unique character is “b”.
Hence, the answer is "b", with a length of 1 which is the maximum.
Input: s = "pwwkew"
Output: 3
Explanation: The possible substring with unique character in s are “pw”, “wk”, “wke”, “ke”, “kew”, etc.
The answer is "wke", with a length of 3 which is the maximum length of all substrings.
*Note:- that the answer must be a substring if s=”pwwkew” . The substrings are “pww” , “wwk”, “wwkew”, “kew” and not “pwk” or “pkw” or “kww”. Individual characters are also considered substrings.
Constraints:
- 0 <= s.length <= 5 * 10^4
- s consists of English letters, digits, symbols, and spaces.
Try Solving it Yourself First !
Although this problem might seem straightforward, there are different ways to solve it by using two pointers/sliding window, etc. Each approach has its own benefits and challenges in terms of how fast it works and how much memory it uses.
Brute Force Approach (Generate All Substrings)
Let’s start with a simple brute-force approach. As the question says to find the Longest Substring Without Repeating Characters, let us.
Generate all substrings of the string s.
How to generate all substrings of a string ?
To generate all substrings of s, we will be using two loops.
We will start from the first character and move through each character of the string one by one. For each character, this is considered as the starting point of the substring.
For each starting character, we iterate over the next character and will continue till the end of the string. We will consider every possible ending point for the substring, ensuring that the ending index is always greater than the starting point (so you get non-empty substrings).
For each pair of start and end points, a substring is formed by selecting characters between the start index and one less than the end index. This way, we will be building all possible substrings.
For example if s = “abcde”,
The start point = 0
The end point = 1
The highlighted part is the substring formed in “abcde”.
Then the end point increments to the next index i.e end point = 2
The highlighted part is the substring formed in “abcde”. Similarly, we will move the end point till the end of the substring.
Once the end point reaches the end of the substring. We will increment the start point and start the same procedure all again until our start point is equal to the length of the substring.
When the start point =1
The end point = 2 The highlighted part is the substring formed , “abcde”
The next substring formed is the highlighted part in “abcde”.
Once we generate all possible substrings of the given string, check each substring to determine if it contains any repeating characters. Track the length of the longest substring that does not contain repeating characters.
How To Approach This Problem
- We can use two nested loops to generate all possible substrings of s.
- For each substring, we will check if all characters are unique.
- We can maintain a boolean array of size 256, assuming all ASCII characters.
- We will keep track of the maximum length of substrings with unique characters.
Why array of size 256 is used ?
There are 256 number of ASCII characters including special characters.
How we handle the boolean array of 256 ?
All the values of array is initially set to false , representing that the value at that particular index is unvisited.
Once, we encounter a value, the index of that particular value is set to true, representing the value is visited.
- If a character is repeated, we break out of the inner loop since the substring no longer satisfies the requirement.
The maxLength is updated whenever a new, longer valid substring is found.
Dry Run
String s= “aabcccdefec”
Answer= 4
Explanation:- “cdef” is the longest possible substring among all other substrings with unique characters in it.
1. Start with i = 0 (first character 'a'):
Substring: "a" → No repeating characters → Current length = 1.
Substring: "aa" → Repeating 'a' → Stop this substring.
Max length so far = 1.
2. Start with i = 1 (second character 'a'):
Substring: "a" → No repeating characters → Current length = 1.
Substring: "ab" → No repeating characters → Current length = 2.
Substring: "abc" → No repeating characters → Current length = 3.
Substring: "abcc" → Repeating 'c' → Stop this substring.
Max length so far = 3.
3. Start with i = 2 (third character 'b'):
Substring: "b" → No repeating characters → Current length = 1.
Substring: "bc" → No repeating characters → Current length = 2.
Substring: "bcc" → Repeating 'c' → Stop this substring.
Max length so far = 3.
4. Start with i = 3 (fourth character 'c'):
Substring: "c" → No repeating characters → Current length = 1.
Substring: "cc" → Repeating 'c' → Stop this substring.
Max length so far = 3.
5. Start with i = 4 (fifth character 'c'):
Substring: "c" → No repeating characters → Current length = 1.
Substring: "cd" → No repeating characters → Current length = 2.
Substring: "cde" → No repeating characters → Current length = 3.
Substring: "cdef" → No repeating characters → Current length = 4.
Substring: "cdefe" → Repeating 'e' → Stop this substring.
Max length so far = 4.
6. Start with i = 5 (sixth character 'c'):
Substring: "c" → No repeating characters → Current length = 1.
Substring: "cd" → No repeating characters → Current length = 2.
Substring: "cde" → No repeating characters → Current length = 3.
Substring: "cdef" → No repeating characters → Current length = 4.
Substring: "cdefe" → Repeating 'e' → Stop this substring.
Max length so far = 4.
7. Start with i = 6 (seventh character 'd'):
Substring: "d" → No repeating characters → Current length = 1.
Substring: "de" → No repeating characters → Current length = 2.
Substring: "def" → No repeating characters → Current length = 3.
Substring: "defe" → Repeating 'e' → Stop this substring.
Max length so far = 4.
8. Start with i = 7 (eighth character 'e'):
Substring: "e" → No repeating characters → Current length = 1.
Substring: "ef" → No repeating characters → Current length = 2.
Substring: "efe" → Repeating 'e' → Stop this substring.
Max length so far = 4.
9. Start with i = 8 (ninth character 'f'):
Substring: "f" → No repeating characters → Current length = 1.
Substring: "fe" → No repeating characters → Current length = 2.
Substring: "fec" → No repeating characters → Current length = 3.
Max length so far = 4.
10. Start with i = 9 (tenth character 'e'):
Substring: "e" → No repeating characters → Current length = 1.
Substring: "ec" → No repeating characters → Current length = 2.
Max length so far = 4.
11. Start with i = 10 (eleventh character 'c'):
Substring: "c" → No repeating characters → Current length = 1.
Max length so far = 4.
Conclusion:
After generating all possible substrings and checking them, the longest substring without repeating characters in "aabcccdefec" is "cdef" with a length of 4.
Final Result:
Longest substring without repeating characters: "cdef"
Length: 4
Brute Force in all Languages
1. C++ Try on Compiler
#include <iostream>
#include <string>
#include <vector>
#include <algorithm>
using namespace std;
class Solution {
public:
int lengthOfLongestSubstring(string s) {
int maxLength = 0;
// Iterate over all possible substrings
for (int i = 0; i < s.length(); i++) {
for (int j = i + 1; j <= s.length(); j++) {
string substring = s.substr(i, j - i);
// Check if the substring has all unique characters
if (hasAllUniqueChars(substring)) {
maxLength = max(maxLength, j - i); // Update maxLength if valid
}
}
}
return maxLength;
}
private:
// Helper function to check if a string has all unique characters
bool hasAllUniqueChars(const string& substring) {
vector<bool> charSet(256, false); // Array to track the presence of characters (size 256 for extended ASCII)
for (char ch : substring) {
if (charSet[ch]) {
return false; // If the character is already found, the substring does not have unique characters
}
charSet[ch] = true; // Mark the character as found
}
return true; // All characters are unique
}
};
2. Java Try on Compiler
import java.util.Scanner;
public class LongestUniqueSubstring {
// Helper function to check if a string has all unique characters
public static boolean hasAllUniqueChars(String substring) {
boolean[] charSet = new boolean[256]; // Array to track the presence of characters (size 256 for extended ASCII)
for (int i = 0; i < substring.length(); i++) {
char ch = substring.charAt(i);
if (charSet[ch]) {
return false; // If the character is already found, the substring does not have unique characters
}
charSet[ch] = true; // Mark the character as found
}
return true; // All characters are unique
}
// Brute force function to find the length of the longest substring with unique characters
public static int lengthOfLongestSubstring(String s) {
int maxLength = 0;
// Generate all substrings using two nested loops
for (int i = 0; i < s.length(); i++) {
for (int j = i + 1; j <= s.length(); j++) {
String substring = s.substring(i, j);
// Check if the substring has all unique characters
if (hasAllUniqueChars(substring)) {
maxLength = Math.max(maxLength, substring.length()); // Update maxLength if valid
}
}
}
return maxLength;
}
}
3. Python Try on Compiler
class Solution:
# Function to count the number of good substrings of length 3
def countGoodSubstrings(self, s: str) -> int:
count = 0
# Traverse the string and check every substring of length 3
for i in range(len(s) - 2):
substring = s[i:i+3]
if self.hasAllUniqueChars(substring):
# If the substring has all unique characters, increment the count
count += 1
return count
# Helper function to check if all characters in a substring are unique
def hasAllUniqueChars(self, substring: str) -> bool:
# Array to track presence of characters (size 256 for extended ASCII)
charSet = [False] * 256
for ch in substring:
if charSet[ord(ch)]:
# If character is already found, return false
return False
# Mark the character as found
charSet[ord(ch)] = True
# All characters are unique
return True
4. JavaScript Try on Compiler
class Solution {
// Function to count the number of good substrings of length 3
countGoodSubstrings(s) {
let count = 0;
// Traverse the string and check every substring of length 3
for (let i = 0; i < s.length - 2; i++) {
let substring = s.slice(i, i + 3);
if (this.hasAllUniqueChars(substring)) {
// If the substring has all unique characters, increment the count
count++;
}
}
return count;
}
// Helper function to check if all characters in a substring are unique
hasAllUniqueChars(substring) {
// Array to track presence of characters (size 256 for extended ASCII)
let charSet = new Array(256).fill(false);
for (let ch of substring) {
if (charSet[ch.charCodeAt(0)]) {
// If character is already found, return false
return false;
}
// Mark the character as found
charSet[ch.charCodeAt(0)] = true;
}
// All characters are unique
return true;
}
}
Time Complexity: O(n^3)
We have two nested loops:
The outer loop runs from i = 0 to i = n - 1 (total n iterations).
The inner loop runs from j = i + 1 to n for each i, making approximately n - i iterations for each i.
Therefore, generating all substrings takes O(n^2) time.
For each substring, the helper function hasAllUniqueChars() checks if all characters in the substring are unique. The length of each substring is approximately O(n) in the worst case (when the substring length approaches n).
Since we're generating O(n^2) substrings, and for each substring we check the uniqueness in O(n) time, the total time complexity becomes O(n^3).
Space Complexity : O(n)
2. Auxiliary Space Complexity:
Auxiliary space refers to any extra space (excluding input) required by the algorithm.
In the helper function hasAllUniqueChars(), a set or boolean array is used to track characters' uniqueness. This space is O(1) since the size of the tracking structure (either 256 for ASCII or 128 for extended ASCII) is fixed and does not depend on the input size n.
Other than the tracking structure, we're only using a few variables like maxLength, loop counters, and temporary substrings. These all take constant space, so O(1).
Auxiliary Space Complexity: O(1).
3. Total Space Complexity:
The total space complexity includes the input space plus the auxiliary space.
Input Space:The input string s requires O(n) space, where n is the length of the string.
Auxiliary Space: As discussed above, auxiliary space is O(1).
Total Space Complexity: O(n) (for the input string).
We analyzed that the total Time Complexity is O(n^3) which is a brute force and will never be accepted as a solution for the given problem statement . The brute force approach will make the interviewer dissatisfied because the time complexity of O(n^3) is a major concern for large input sizes.
Why will it give TLE ?
What if the string size was greater than 10^3?
Given a string with a length up to 5×10^4(as per the problem constraints), an O(n²) solution would result in 2.5 billion operations in the worst case, which would be extremely slow and inefficient.
That means for larger input size of 10^9 will end up in Time Limit Exceeded !!
Our previous solution was a O(n^3) solution which means we have to either find a solution with O(n^2) or O(n) or maybe O(nlogn) or O(logn) or maybe lesser than that.
Optimized Approach Using Sliding Window
Intuition
Can we think of a O(n) solution as it tells that, “Traverse your string once and get me the answer !!
While traversing the string, when we find a repeating character, there's no point in continuing to check every single character step by step.
Instead, once we hit a repeating character, we should jump forward to where we can start checking again with a new substring.
Consider the string "abcabcbb".
As we traverse this string, we start building substrings of unique characters. Initially, we find the substring "abc", which contains unique characters: a, b, and c.
As we process the characters, we keep track of their last seen positions using an array (or hash map).
For instance, after processing the first three characters (a, b, c), our character tracker (let’s call it charIndex) looks like this:
- charIndex['a'] = 0 (index of a)
- charIndex['b'] = 1 (index of b)
- charIndex['c'] = 2 (index of c)
All other indices remain -1 (indicating those characters haven't been seen yet).
Now, as we continue traversing the string, we encounter the next “a” at index 3.
At this point, we see that charIndex['a'] is 0, which indicates that “a” was last seen at index 0.
Since the current character “a” at index 3 is a duplicate of the “a” we saw earlier (at index 0), we need to update our current substring to maintain unique characters.
Did we observe that any characters from the previous substring ("abc") that we have already processed cannot be part of the new valid substring that starts after the last occurrence of a? , Yes !!
To ensure the new substring remains unique, we move our left pointer to one position right after the last occurrence of “a”. This means we will move left to charIndex['a'] + 1, which is 0 + 1 = 1.
By doing this, we are essentially saying:
"I will now start checking from the character right after the last occurrence of a".
After moving the left pointer: The substring we are now considering starts from index 1 (which is b).
The characters currently being considered for our new substring are "bca".
We can now continue exploring the string without worrying about any characters from the previous substring that could cause duplicates.
Does skipping make sense ?
The reason we can skip looking at characters within "abc" is because we have already established that these characters were part of a valid substring.
Since we know that the last occurrence of the character that caused the repeat (a) was at index 0, any substring that includes this character (from the start up to 0) is no longer valid.
Instead of looking at every substring from scratch, can we remember where we saw each character?
Let's think about tracking the last position of each character in the string. Whenever we see a character again, we can move ahead and start fresh from the character right after the last occurrence of that repeating character.
How to Track the Characters ?
We can use an array (or a simple table) that stores the last index where each character was seen. This way, for every character we come across, we can:
Check if it has been seen before within the current portion of the string we’re looking at.
If it has, we know exactly where it was, and we can jump ahead and start fresh from the next character after the last occurrence.
For each character, we keep moving forward through the string and update our longest valid substring. When we see a repeating character, we know where to restart because we have tracked its last position.
What we are essentially doing is maintaining a dynamic frame of characters (we'll call it a window) that always contains unique characters. The size of this window adjusts as we move forward through the string.
The frame is designed in such a way that it doesn’t allow duplicate characters inside it. The frame is dynamic, which means that it can expand and shrink.
When will it Expand /Shrink ?
The frame expands as long as unique characters of the string come inside the frame.
The frame shrinks whenever a duplicate character enters the frame.
This approach is often called a sliding window because the "window" (or range of unique characters) moves forward as we process the string.
The left side of the window moves forward when we encounter a repeating character, and the right side moves forward as we explore new characters.
The length of the valid window at each step is tracked, and the maximum is updated as you traverse the string.
How will the length be calculated ??
The length will be equal to the distance between the left end and the right end +1. i.e right - left + 1
Why the length is (right-left+1) ?
Suppose s = “abccde”
When we start expanding the frame that consumes all unique characters, the last substring with no repeating characters is the highlighted part of “abccdee”.
The substring is “cde”, here the left pointer is at:- 3 and the right pointer is at 5.
The length of the substring is right-left+1 i.e 3.We are adding 1 to the answer since we follow 0-based indexing.
We are on the right track!!
Since, we know that we have to traverse the complete string and find out the longest substring with unique characters, and without traversing the whole substring we cannot determine the answer, hence we can get the answer in O(n) runtime, right??
Yes, the Sliding Window Algorithm exactly aligns with our thought process.
How To Approach This Problem
- Initialize maxLength to keep track of the longest substring found.
- Initialize the a to represent the beginning of the current window.
- Create a charMap to map each character to its last seen index.
- Iterate through the string using the Let's right pointer, which represents the end of the current window.
- For each character at the right pointer, check if it has been seen before.
- If the character is found in charMap, it indicates a repetition within the current window. Therefore, move the left pointer to just after the last occurrence of that character to shrink the window.
- Update the last seen position of the current character in charMap.
- Calculate the length of the current window and update maxLength if this window is larger.
- After completing the iterations, return maxLength, which contains the length of the longest substring without repeating characters.
Let's Visualize the example with a Video
Dry Run
String s= “aabcccdefec”
Answer= 4
Explanation:- “cdef” is the longest possible substring among all other substrings with unique characters in it.
Initial Setup
Input string: "aabcccdefec"
Array charIndex: Initialized to -1 for all 256 characters.
Variables:
maxLength = 0
start = 0
Iteration 1 (end = 0):
Current character: 'a'
charIndex['a'] is -1 (not seen before).
Update charIndex['a'] to 0 (current index).
Calculate new length: end - start + 1 → 0 - 0 + 1 = 1.
Update maxLength to 1.
Iteration 2 (end = 1):
Current character: 'a'
charIndex['a'] is 0 (last seen at index 0).
Since charIndex['a'] (0) is not less than start (0), update start to 1 (charIndex['a'] + 1).
Update charIndex['a'] to 1.
Calculate new length: end - start + 1 → 1 - 1 + 1 = 1.
maxLength remains 1.
Iteration 3 (end = 2):
Current character: 'b'
charIndex['b'] is -1.
Update charIndex['b'] to 2.
Calculate new length: end - start + 1 → 2 - 1 + 1 = 2.
Update maxLength to 2.
Iteration 4 (end = 3):
Current character: 'c'
charIndex['c'] is -1.
Update charIndex['c'] to 3.
Calculate new length: end - start + 1 → 3 - 1 + 1 = 3.
Update maxLength to 3.
Iteration 5 (end = 4):
Current character: 'c'
charIndex['c'] is 3.
Since charIndex['c'] (3) is not less than start (1), update start to 4.
Update charIndex['c'] to 4.
Calculate new length: end - start + 1 → 4 - 4 + 1 = 1.
maxLength remains 3.
Iteration 6 (end = 5):
Current character: 'c'
charIndex['c'] is 4.
Since charIndex['c'] (4) is not less than start (4), update start to 5.
Update charIndex['c'] to 5.
Calculate new length: end - start + 1 → 5 - 5 + 1 = 1.
maxLength remains 3.
Iteration 7 (end = 6):
Current character: 'd'
charIndex['d'] is -1.
Update charIndex['d'] to 6.
Calculate new length: end - start + 1 → 6 - 5 + 1 = 2.
maxLength remains 3.
Iteration 8 (end = 7):
Current character: 'e'
charIndex['e'] is -1.
Update charIndex['e'] to 7.
Calculate new length: end - start + 1 → 7 - 5 + 1 = 3.
maxLength remains 3.
Iteration 9 (end = 8):
Current character: 'f'
charIndex['f'] is -1.
Update charIndex['f'] to 8.
Calculate new length: end - start + 1 → 8 - 5 + 1 = 4.
Update maxLength to 4.
Iteration 10 (end = 9):
Current character: 'e'
charIndex['e'] is 7.
Since charIndex['e'] (7) is not less than start (5), update start to 8.
Update charIndex['e'] to 9.
Calculate new length: end - start + 1 → 9 - 8 + 1 = 2.
maxLength remains 4.
Iteration 11 (end = 10):
Current character: 'c'
charIndex['c'] is 5.
Since charIndex['c'] (5) is not less than start (8), update start to 6.
Update charIndex['c'] to 10.
Calculate new length: end - start + 1 → 10 - 6 + 1 = 5.
Update maxLength to 5.
Final Result
After processing the entire string, the maximum length of the substring without repeating characters is 5.
Optimal Code for all languages
1. C++ Try on Compiler
#include <iostream>
#include <vector>
#include <string>
using namespace std;
class Solution {
public:
int lengthOfLongestSubstring(string s) {
// To store last seen index of characters
vector<int> charIndex(256, -1);
int maxLength = 0, start = 0;
for (int end = 0; end < s.length(); end++) {
char currentChar = s[end];
if (charIndex[currentChar] >= start) {
// Move start to the right of the last occurrence
start = charIndex[currentChar] + 1;
}
// Update the last seen index of the character
charIndex[currentChar] = end;
// Update maxLength
maxLength = max(maxLength, end - start + 1);
}
return maxLength;
}
};2. Java Try on Compiler
import java.util.*;
class Solution {
public static int lengthOfLongestSubstring(String s) {
// To store last seen index of characters
int[] charIndex = new int[256];
for (int i = 0; i < 256; i++) {
// Initialize all values to -1
charIndex[i] = -1;
}
int maxLength = 0, start = 0;
for (int end = 0; end < s.length(); end++) {
char currentChar = s.charAt(end);
if (charIndex[currentChar] >= start) {
// Move start to the right of the last occurrence
start = charIndex[currentChar] + 1;
}
// Update the last seen index of the character
charIndex[currentChar] = end;
// Update maxLength
maxLength = Math.max(maxLength, end - start + 1);
}
return maxLength;
}
3. Python Try on Compiler
def length_of_longest_substring(s: str) -> int:
# To store last seen index of characters
char_index = [-1] * 256
max_length = 0
start = 0
for end in range(len(s)):
current_char = s[end]
if char_index[ord(current_char)] >= start:
# Move start to the right of the last occurrence
start = char_index[ord(current_char)] + 1
# Update the last seen index of the character
char_index[ord(current_char)] = end
# Update maxLength
max_length = max(max_length, end - start + 1)
return max_length
4. JavaScript Try on Compiler
function lengthOfLongestSubstring(s) {
const charIndex = new Array(256).fill(-1); // To store last seen index of characters
let maxLength = 0;
let start = 0;
for (let end = 0; end < s.length; end++) {
const currentChar = s.charCodeAt(end);
if (charIndex[currentChar] >= start) {
start = charIndex[currentChar] + 1; // Move start to the right of the last occurrence
}
charIndex[currentChar] = end; // Update the last seen index of the character
maxLength = Math.max(maxLength, end - start + 1); // Update maxLength
}
return maxLength;
}
Time Complexity: O(n)
The algorithm processes each character in the string exactly once using two pointers (start and end).
The end pointer iterates through the entire string, while the start pointer only moves forward when a duplicate character is found.
In the worst case, each character will be added and removed from the charMap at most once, leading to an overall time complexity of O(n), where n is the length of the string.
Space Complexity: O(n)
Auxiliary Space Complexity:
Auxiliary space refers to the extra space used by the algorithm that is not part of the input.
The auxiliary space complexity will be determined by the size of the character array used to track the last seen positions. Since this array is fixed in size (256), the auxiliary space complexity is O(1). This is because the space used does not grow with the input size but remains constant regardless of the length of the input string.
Total Space Complexity:
The total space complexity is the sum of:
Input space: The string s occupies O(n) space.
Auxiliary space: The character array used to track the last occurrence of each character occupies O(1) space.
Therefore, the total space complexity is O(n).
Learning Tip
Since we solved a sliding window problem, let us visit the following problems.
- Count the Number of Substrings With Dominant Ones
- Minimum Size Subarray Sum
- Longest Continuous Subarray With Absolute Diff Less Than or Equal to Limit
- Longest Repeating Character Replacement
- Max Consecutive Ones III
Given a string s, return the maximum number of occurrences of any substring under the following rules:
- The number of unique characters in the substring must be less than or equal to maxLetters.
- The substring size must be between minSize and maxSize inclusive.
Given a string s, return the maximum number of occurrences of any substring under the following rules:
- The number of unique characters in the substring must be less than or equal to maxLetters.
- The substring size must be between minSize and maxSize inclusive.