Maximum Number of Occurrences of a Substring
Problem Description
Given a string s, return the maximum number of occurrences of any substring under the following rules: The number of unique characters in the substring must be less than or equal to maxLetters. The substring size must be between minSize and maxSize inclusive.
Examples of Maximum Number of Occurrences of a Substring
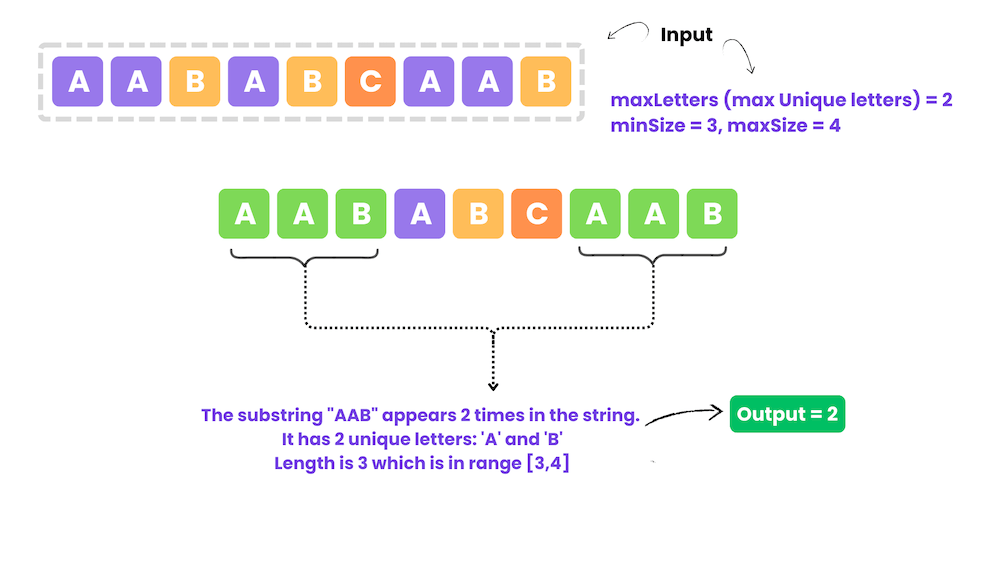
Input: s = "aababcaab", maxLetters = 2, minSize = 3, maxSize = 4
Output: 2
Explanation: We're looking for substrings with at most 2 unique letters and of length between 3 and 4.
The substring "aab" appears 2 times in the string and satisfies the conditions:
It has 2 unique letters: 'a' and 'b'. Its length is 3, which is within the allowed range (minSize = 3, maxSize = 4).
Thus, the answer is 2.
Input: s = "aaaa", maxLetters = 1, minSize = 3, maxSize = 3
Output: 2
Explanation: We're looking for substrings with at most 1 unique letter and of length exactly 3.
The substring "aaa" appears 2 times in the string:
It has only 1 unique letter ('a'), which is within the limit (maxLetters = 1).
Its length is exactly 3, which is within the allowed size.
So, the answer is 2.
Overlapping Substrings:
In the examples, notice that substrings can overlap. For example, the two occurrences of "aaa" overlap in “aaaa” are the highlighted part of "aaaa" and “aaaa” .
Constraints:
- 1 <= s.length <= 10^5
- 1 <= maxLetters <= 26
- 1 <= minSize <= maxSize <= min(26, s.length)
- s consists of only lowercase English letters.
Try it Yourself First !
Brute Force Approach
do we
We are given a string s and need to find the substring that appears the most times in s under a few specific rules.
The rules are:
- The number of unique characters in the substring must be less than or equal to a given number, maxLetters.
- The size of the substring must be between two values: minSize and maxSize (inclusive). So, the substring can be any length from minSize to maxSize.
Our task is to return how many times the most frequent valid substring appears in the string s.
Since the question asks us to find the maximum occurrences of a substring, why not generate all possible substrings whose length is between minSize and maxSize ??
Exactly, let's do it !!
But How to Generate the Substrings ?
To generate all substrings of s, we will be using two loops.
We begin at the first index (index 0) of the string and move through each index of the string one by one. For each index, this becomes the starting point of the substring.
At each starting index, we iterate through the next indices in the string. We continue this process until we reach the end of the string.
For each starting index, we consider every possible ending index. We ensure that the ending index is always greater than the starting index to form non-empty substrings.
For each pair of starting and ending indices, a substring is formed by selecting the characters between the starting index and one less than the ending index. This way, we build all possible substrings.
For example, for a string "ABCDEF":
Start at index 0:
Substrings: s[0 to 1] = "A", s[0 to 2] = "AB", s[0 to 3] = "ABC", ..., s[0 to 6] = "ABCDEF"
Start at index 1:
Substrings: s[1 to 2] = "B", s[1 to 3] = "BC", ..., s[1 to 6] = "BCDEF"
Continue with other indices until you cover all starting and ending points.
Each iteration forms a substring by slicing between the selected start and end indices.
Moving further.
Let’s generate a substring to exactly minSize because If a substring of size minSize appears frequently, it’s very likely that any larger substring (of size minSize + 1, minSize + 2, etc.) will appear less frequently because the larger substring is just an extension of the smaller one.
Why are we generating Substring of minSize ?
Let’s understand why we should consider the minSize for further steps:-
s = "abcabcabcabc"
maxLetters = 3
minSize = 3
maxSize = 4
Step 1: Find Substrings of Size minSize = 3
Let’s extract the substrings of length 3:
"abc" (index 0 to 2)
"bca" (index 1 to 3)
"cab" (index 2 to 4)
"abc" (index 3 to 5)
"bca" (index 4 to 6)
"cab" (index 5 to 7)
"abc" (index 6 to 8)
"bca" (index 7 to 9)
"cab" (index 8 to 10)
"abc" (index 9 to 11)
Now let’s count the frequencies of these substrings:
"abc" appears 4 times.
"bca" appears 3 times.
"cab" appears 3 times.
Step 2: What Happens with Substrings of Size maxSize = 4?
Now let’s extract the substrings of length 4:
"abca" (index 0 to 3)
"bcab" (index 1 to 4)
"cabc" (index 2 to 5)
"abca" (index 3 to 6)
"bcab" (index 4 to 7)
"cabc" (index 5 to 8)
"abca" (index 6 to 9)
"bcab" (index 7 to 10)
"cabc" (index 8 to 11)
Now let’s count the frequencies of these substrings:
"abca" appears 3 times.
"bcab" appears 3 times.
"cabc" appears 3 times.
Why focus on minSize substrings ?
We see that the substring "abc" of size 3 appears 4 times, which is the most frequent substring.
However, the substrings of size 4 (like "abca", "bcab", etc.) appear less frequently (at most 3 times).
Larger substrings are less likely to appear multiple times in the string due to their increased length and stricter constraints.
So, we can focus on substrings of length exactly minSize.
Since we come to know that generating the substrings of size minSize will be efficient.
For each substring of length minSize, we need to check if it contains at most “maxLetters” unique characters.
If the substring has more than “maxLetters” unique characters, it does not satisfy the condition, so we skip it.
If the condition is satisfied, then we will count the frequencies of those valid substrings.
How do we maintain the record for each String since there can be many such possible substrings?
Can we think of a data structure that stores a string and its frequency together?
Even if the same string appears multiple times, it will update its frequency.
Is it a Map ??
Exactly, a Map data structure stores Key-Value Pairs.
What is a HashMap/Map ?
HashMap is a data structure that stores key-value pairs.
If any duplicate Key enters the map, it just updates the value of that particular key to the newly entered value.
The Map data structure exactly aligns with our needs.
Operations we can perform on a map are:-
- Insertion
- Updation
- Search
- Removal
There are two types of maps, mainly unordered maps, which store key-value pairs in an unsorted manner and ordered maps which store the key-value pairs in sorted order.
Since the order of the substring doesn’t matter so we will be using an unordered map.
Further to our approach,
After scanning the entire string and counting the valid substrings, find the substring with the highest frequency and return that frequency.
How To Approach This Problem
Create a Map for Tracking Substring Frequencies:Start by creating an empty map that will store pairs of data: one part will be the substring, and the other part will be the number of times that substring appears.
Iterate Over the Input Text:Move through the text one position at a time, and at each position, capture a segment that starts at that position and has a specific length.Continue doing this until every possible segment of this specified length has been examined.
Analyze Unique Character Count:For each captured segment, calculate the number of distinct characters within it.If the count of distinct characters is within a certain acceptable limit, consider this segment valid for further analysis.
Store and Update Frequency:For valid segments, update their occurrences in the collection:If the segment already exists on the map, increase its occurrence count.If it does not exist yet, add it to the map with an initial count.
Identify the Maximum Frequency:After examining all segments, look through the map to find the segment with the highest occurrence count.This value represents the most frequently occurring valid segment.
Finally, return the maximum count you found. This represents the maximum number of times any valid substring appeared in the string.
Still having confusion ??
Let’s visualize this
Let’s take an example ifs = "abcabcabc"
maxLetters = 3
minSize = 3
maxSize = 3
We are looking for substrings with at most 3 unique letters and of length exactly 3 (minSize = 3, maxSize = 3).
Let's extract all the possible substrings of length 3 from the string s = "abcabcabc":
"abc" (from index 0 to 2)
"bca" (from index 1 to 3)
"cab" (from index 2 to 4)
"abc" (from index 3 to 5)
"bca" (from index 4 to 6)
"cab" (from index 5 to 7)
"abc" (from index 6 to 8)
Now, let’s check if each of these substrings satisfies the condition of having 3 or fewer unique letters:
"abc" has 3 unique letters ('a', 'b', 'c'), which is allowed.
"bca" also has 3 unique letters ('b', 'c', 'a'), which is allowed.
"cab" has 3 unique letters ('c', 'a', 'b'), which is allowed.
Since all of these substrings are valid, let’s count how often each appears in the string.
"abc" appears 3 times (at indices 0, 3, and 6).
"bca" appears 2 times (at indices 1 and 4).
"cab" appears 2 times (at indices 2 and 5).
The most frequent valid substring is "abc", which appears 3 times.
Output: 3

Dry-Run
Example :
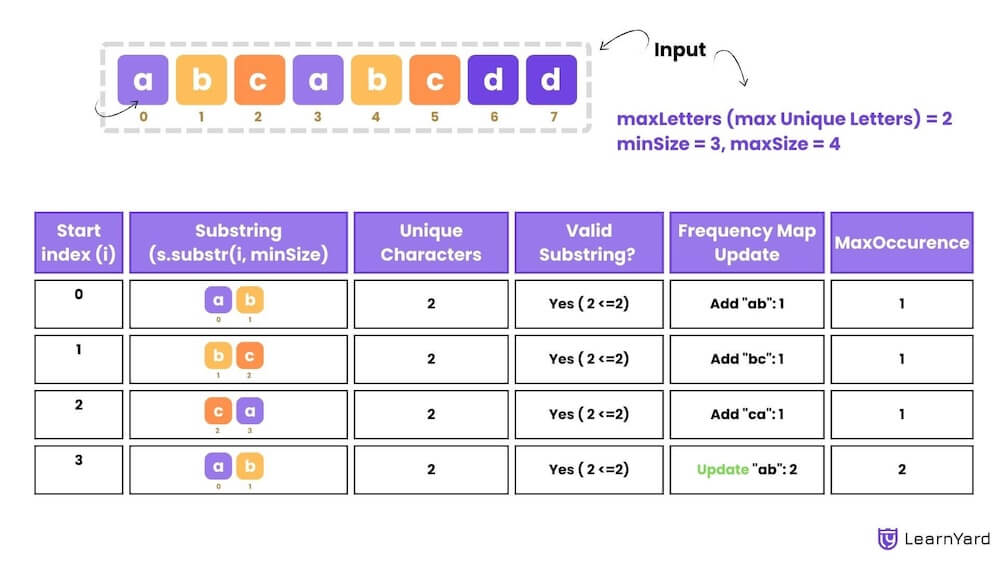
String s : "abcabcdd"
maxLetters: 2
minSize: 2
maxSize: 3
Output:- 2
Explanation:- The most frequent valid substring is "ab", which appears 2 times
Dry-Run
Substring 1:
Start at index 0: Substring = "ab"
Unique characters: "a", "b" → 2 unique characters (equal to maxLetters).
Add to frequency map: frequencyMap = {"ab": 1}
Substring 2:
Start at index 1: Substring = "bc"
Unique characters: "b", "c" → 2 unique characters (equal to maxLetters).
Add to frequency map: frequencyMap = {"ab": 1, "bc": 1}
Substring 3:
Start at index 2: Substring = "ca"
Unique characters: "c", "a" → 2 unique characters (equal to maxLetters).
Add to frequency map: frequencyMap = {"ab": 1, "bc": 1, "ca": 1}
Substring 4:
Start at index 3: Substring = "ab"
Unique characters: "a", "b" → 2 unique characters (equal to maxLetters).
Update frequency map: frequencyMap = {"ab": 2, "bc": 1, "ca": 1}
Substring 5:
Start at index 4: Substring = "bc"
Unique characters: "b", "c" → 2 unique characters (equal to maxLetters).
Update frequency map: frequencyMap = {"ab": 2, "bc": 2, "ca": 1}
Substring 6:
Start at index 5: Substring = "cd"
Unique characters: "c", "d" → 2 unique characters (equal to maxLetters).
Add to frequency map: frequencyMap = {"ab": 2, "bc": 2, "ca": 1, "cd": 1}
Substring 7:
Start at index 6: Substring = "dd"
Unique characters: "d" → 1 unique character (less than maxLetters).
Add to frequency map: frequencyMap = {"ab": 2, "bc": 2, "ca": 1, "cd": 1, "dd": 1}
Frequency Map:
Result:
Output:
frequencyMap = {
"ab": 2,
"bc": 2,
"ca": 1,
"cd": 1,
"dd": 1
}
Frequency Map:
Result:
Output:
The substrings "ab" and "bc" each occur 2 times, which is the maximum frequency of any substring that satisfies the conditions.
**Frequency Map:
Result:
Output:**
2 (The maximum number of occurrences for any valid substring).
Brute Force in all Languages
1. C++ Try on Compiler
#include <bits/stdc++.h>
using namespace std;
// Helper function to count unique characters
int uniqueCharCount(const string &s) {
vector<int> charCount(26, 0);
int uniqueCount = 0;
for (char c : s) {
if (charCount[c - 'a'] == 0) {
uniqueCount++;
}
charCount[c - 'a']++;
}
return uniqueCount;
}
// Function to calculate max occurrences of valid substrings
int maxFreq(const string &s, int maxLetters, int minSize, int maxSize) {
unordered_map<string, int> frequencyMap;
int maxOccurrence = 0;
for (int i = 0; i <= s.size() - minSize; i++) {
string substring = s.substr(i, minSize);
if (uniqueCharCount(substring) <= maxLetters) {
frequencyMap[substring]++;
maxOccurrence = max(maxOccurrence, frequencyMap[substring]);
}
}
return maxOccurrence;
}
2. Java Try on Compiler
import java.util.*;
public class MaxSubstringOccurrences {
// Method to calculate the maximum frequency of valid substrings
public static int maxFreq(String s, int maxLetters, int minSize, int maxSize) {
// Frequency map to store occurrences of valid substrings
Map<String, Integer> frequencyMap = new HashMap<>();
int maxOccurrence = 0;
// Iterate through the string to extract substrings of size minSize
for (int i = 0; i <= s.length() - minSize; i++) {
// Extract the substring of length minSize starting at index i
String substring = s.substring(i, i + minSize);
// Check if the substring has unique characters less than or equal to maxLetters
if (uniqueCharCount(substring) <= maxLetters) {
// Update the frequency map
frequencyMap.put(substring, frequencyMap.getOrDefault(substring, 0) + 1);
// Track the maximum occurrence of any valid substring
maxOccurrence = Math.max(maxOccurrence, frequencyMap.get(substring));
}
}
// Return the maximum occurrence of any valid substring
return maxOccurrence;
}
// Helper method to count the number of unique characters in a string
private static int uniqueCharCount(String s) {
// For lowercase English letters
int[] charCount = new int[26];
int uniqueCount = 0;
for (char c : s.toCharArray()) {
if (charCount[c - 'a'] == 0) {
uniqueCount++;
}
charCount[c - 'a']++;
}
return uniqueCount;
}
}
3. Python Try on Compiler
from collections import defaultdict
def max_freq(s: str, max_letters: int, min_size: int, max_size: int) -> int:
# Frequency dictionary to store occurrences of valid substrings
frequency_map = defaultdict(int)
max_occurrence = 0
# Iterate through the string to extract substrings of size min_size
for i in range(len(s) - min_size + 1):
# Extract the substring of length min_size starting at index i
substring = s[i:i + min_size]
# Check if the substring has unique characters less than or equal to max_letters
if unique_char_count(substring) <= max_letters:
# Update the frequency map
frequency_map[substring] += 1
# Track the maximum occurrence of any valid substring
max_occurrence = max(max_occurrence, frequency_map[substring])
# Return the maximum occurrence of any valid substring
return max_occurrence
# Helper function to count the number of unique characters in a string using a hash table
def unique_char_count(s: str) -> int:
char_count = {}
unique_count = 0
for char in s:
if char not in char_count:
char_count[char] = 1
unique_count += 1
else:
char_count[char] += 1
return unique_count
4. JavaScript Try on Compiler
function maxFreq(s, maxLetters, minSize, maxSize) {
const frequencyMap = new Map();
let maxOccurrence = 0;
// Iterate through the string to extract substrings of size minSize
for (let i = 0; i <= s.length - minSize; i++) {
const substring = s.substring(i, i + minSize);
// Check if the substring has unique characters <= maxLetters
if (uniqueCharCount(substring) <= maxLetters) {
// Update frequency map
frequencyMap.set(substring, (frequencyMap.get(substring) || 0) + 1);
// Track the max occurrence of any valid substring
maxOccurrence = Math.max(maxOccurrence, frequencyMap.get(substring));
}
}
return maxOccurrence;
}
function uniqueCharCount(s) {
const charCount = {};
let uniqueCount = 0;
for (let char of s) {
if (!charCount[char]) {
charCount[char] = 1;
uniqueCount++;
}
}
return uniqueCount;
}
Time Complexity : O(n x minSize)
We iterate through the string s to extract substrings of length minSize. This runs for O(n - minSize + 1) iterations, where n is the length of s.
Substring Extraction & Unique Character Count: Extracting a substring and counting unique characters both take O(minSize) time.
Inserting/updating a substring in the map takes O(1) time on average.
Thus, the overall time complexity is: O(n×minSize)
Space Complexity : O(n x minSize)
Auxiliary Space Complexity:
In the worst case, the map stores up to O(n - minSize + 1) substrings, each of length minSize. The space complexity for the map is O(n - minSize + 1) .
Unique Character Counting: Uses constant space, i.e., O(1).
So, the auxiliary space complexity is: O((n−minSize+1)×minSize)
Total Space Complexity:
Input string: O(n) for storing the input string.
Auxiliary space: Dominated by the frequency map, O(n - minSize + 1).
Thus, the total space complexity is: O(n×minSize)
The brute force won’t be accepted if When n=10^5 i.e number of characters is 1,00,000 , minSize=5 , maxSize=50 , maxLetters=26 (all are unique characters). So we need to find an optimal approach.
Optimal Approach
Intuition
We need a solution that:
Quickly check the substrings we care about (only those of the required length). Efficiently keeps track of how many times we see each valid substring.
Since we understood that limiting the substring size to minSize is more efficient than the substrings of minSize+1,minSize+2..etc.
So are we generating all substrings of minSize?
Yes, we are generating all substrings of minSize every time. Can we think of a way where we will be generating all substrings of size minSize but in a more efficient way and then checking them?
Let’s do the above. We can observe that whenever a new substring is formed, the left-most character is deleted, and the right-most is added to form the new substring.
For example: With s = "abcde" and minSize = 3, the sliding window generates:
- The substring "abc" (from index 0 to 2), which is the highlighted part of “abcde”
- The substring "bcd" (from index 1 to 3), which is the highlighted part of “abcde”
- The substring "cde" (from index 2 to 4) which is the highlighted part of “abcde”.
In the above can we observe that whenever a new substring is formed the left-most character is deleted and the right-most is added to form the new substring.
And we keep this doing every time we want a fixed size substring.
What we did was we had a sequence of characters from where the leftmost character was excluded and the next to the rightmost character was included to form a new substring.
Can we imagine it as a frame where the leftmost character is coming inside and the right to rightmost character enters the frame?
In a frame, we have two ends, mainly the left end and the right end. The frame size remains fixed, and whenever the frame slides, the left character comes in, and the right character to the rightmost character of the frame comes in.
As the frame slides, we encounter the formation of new substrings.
Let’s call the frame as a “window”.The algorithm we just figured out is the Sliding-window algorithm.
Did we figure out the optimal way to find the substrings of minSize ??
Yes, we did.
Since we figured out the optimal way to extract a substring.
Next, we need to check whether the frequency of each character is unique or not.
We can use a hash table of size 26 to track the occurrence of each character.
Let's Visualize with the below Video
Dry-Run
Example
String s : "abcabcdd"
maxLetters: 2
minSize: 2
maxSize: 3
Output:- 2
Explanation:- The most frequent valid substring is "ab", which appears 2 times.
Initial State:
frequencyMap = {} (empty map to store frequency of valid substrings)
charCount = [0, 0, ..., 0] (array of size 26 to store character counts in the sliding window)
uniqueCount = 0 (tracks the number of unique characters in the current window)
maxOccurrence = 0 (tracks the highest occurrence of any valid substring)
left = 0, right = 0 (pointers to maintain the window)
First Iteration: right = 0
Add 'a' to the window:
charCount['a' - 'a']++ → charCount[0] = 1
uniqueCount++ → uniqueCount = 1
right++ → right = 1
Window size = right - left = 1 (smaller than minSize = 2), so continue without checking.
Second Iteration: right = 1
Add 'b' to the window:
charCount['b' - 'a']++ → charCount[1] = 1
uniqueCount++ → uniqueCount = 2
right++ → right = 2
Window size = right - left = 2 (now equal to minSize).
Substring: "ab" → Unique characters = 2, which is ≤ maxLetters.
Add "ab" to frequencyMap: frequencyMap = {"ab": 1}
Update maxOccurrence = 1.
Third Iteration: right = 2
Add 'c' to the window:
charCount['c' - 'a']++ → charCount[2] = 1
uniqueCount++ → uniqueCount = 3
Window size exceeds minSize = 2, so shrink from the left.
Remove 'a' from the window:
charCount['a' - 'a']-- → charCount[0] = 0
uniqueCount-- → uniqueCount = 2
left++ → left = 1
Window size = 2 (substring: "bc").
Unique characters = 2, which is ≤ maxLetters.
Add "bc" to frequencyMap: frequencyMap = {"ab": 1, "bc": 1}
maxOccurrence = 1 (remains unchanged).
Fourth Iteration: right = 3
Add 'a' to the window:
charCount['a' - 'a']++ → charCount[0] = 1
uniqueCount++ → uniqueCount = 3
Shrink from the left:
Remove 'b' from the window:
charCount['b' - 'a']-- → charCount[1] = 0
uniqueCount-- → uniqueCount = 2
left++ → left = 2
Window size = 2 (substring: "ca").
Unique characters = 2, which is ≤ maxLetters.
Add "ca" to frequencyMap: frequencyMap = {"ab": 1, "bc": 1, "ca": 1}
maxOccurrence = 1.
Fifth Iteration: right = 4
Add 'b' to the window:
charCount['b' - 'a']++ → charCount[1] = 1
uniqueCount++ → uniqueCount = 3
Shrink from the left:
Remove 'c' from the window:
charCount['c' - 'a']-- → charCount[2] = 0
uniqueCount-- → uniqueCount = 2
left++ → left = 3
Window size = 2 (substring: "ab").
Unique characters = 2, which is ≤ maxLetters.
Update "ab" in frequencyMap: frequencyMap = {"ab": 2, "bc": 1, "ca": 1}
Update maxOccurrence = 2.
Sixth Iteration: right = 5
Add 'c' to the window:
charCount['c' - 'a']++ → charCount[2] = 1
uniqueCount++ → uniqueCount = 3
Shrink from the left:
Remove 'a' from the window:
charCount['a' - 'a']-- → charCount[0] = 0
uniqueCount-- → uniqueCount = 2
left++ → left = 4
Window size = 2 (substring: "bc").
Unique characters = 2, which is ≤ maxLetters.
Update "bc" in frequencyMap: frequencyMap = {"ab": 2, "bc": 2, "ca": 1}
maxOccurrence = 2 (remains unchanged).
Seventh Iteration: right = 6
Add 'd' to the window:
charCount['d' - 'a']++ → charCount[3] = 1
uniqueCount++ → uniqueCount = 3
Shrink from the left:
Remove 'b' from the window:
charCount['b' - 'a']-- → charCount[1] = 0
uniqueCount-- → uniqueCount = 2
left++ → left = 5
Window size = 2 (substring: "cd").
Unique characters = 2, which is ≤ maxLetters.
Add "cd" to frequencyMap: frequencyMap = {"ab": 2, "bc": 2, "ca": 1, "cd": 1}
maxOccurrence = 2.
Eighth Iteration: right = 7
Add 'd' to the window:
charCount['d' - 'a']++ → charCount[3] = 2
Shrink from the left:
Remove 'c' from the window:
charCount['c' - 'a']-- → charCount[2] = 0
uniqueCount-- → uniqueCount = 2
left++ → left = 6
Window size = 2 (substring: "dd").
Unique characters = 1, which is ≤ maxLetters.
Add "dd" to frequencyMap: frequencyMap = {"ab": 2, "bc": 2, "ca": 1, "cd": 1, "dd": 1}
maxOccurrence = 2 (remains unchanged).
Final frequencyMap:
{"ab": 2, "bc": 2, "ca": 1, "cd": 1, "dd": 1}
Final Output:
The most frequent valid substring is "ab", which appears 2 times.
Output = 2.
Optimal Code for all Languages
1. C++ Try on Compiler
#include <bits/stdc++.h>
using namespace std;
// Function to find the maximum frequency of valid substrings
int maxFreq(string s, int maxLetters, int minSize, int maxSize) {
// Frequency map to store occurrences of valid substrings
unordered_map<string, int> frequencyMap;
// Variable to track the maximum occurrence of any valid substring
int maxOccurrence = 0;
// To track frequency of each character (a-z)
vector<int> charCount(26, 0);
// To track the number of unique characters in the current window
int uniqueCount = 0;
// Left pointer for sliding window
int left = 0;
// Right pointer for sliding window
int right = 0;
// Slide the right pointer over the string
while (right < s.length()) {
// Character at the right pointer
char rightChar = s[right];
// If it's the first occurrence of the character, increment uniqueCount
if (charCount[rightChar - 'a'] == 0) {
uniqueCount++;
}
// Increment character count
charCount[rightChar - 'a']++;
// Move right pointer
right++;
// Shrink the window from the left if the window size exceeds minSize
if (right - left > minSize) {
// Character at the left pointer
char leftChar = s[left];
// If this was the last occurrence of the character, decrement uniqueCount
if (charCount[leftChar - 'a'] == 1) {
uniqueCount--;
}
// Decrement character count
charCount[leftChar - 'a']--;
// Move left pointer
left++;
}
// If the window size is equal to minSize and has valid unique characters
if (right - left == minSize && uniqueCount <= maxLetters) {
// Get the current substring
string substring = s.substr(left, minSize);
// Increment its count in the frequency map
frequencyMap[substring]++;
// Update maxOccurrence if needed
maxOccurrence = max(maxOccurrence, frequencyMap[substring]);
}
}
// Return the maximum occurrence of any valid substring
return maxOccurrence;
}2. Java Try on Compiler
import java.util.*;
public class MaxSubstringOccurrences {
public static int maxFreq(String s, int maxLetters, int minSize, int maxSize) {
// Frequency map to store occurrences of valid substrings
Map<String, Integer> frequencyMap = new HashMap<>();
int maxOccurrence = 0;
int[] charCount = new int[26]; // To track the frequency of each character in the current window
int uniqueCount = 0; // To track the number of unique characters in the current window
int left = 0;
int right = 0;
// Slide the right pointer
while (right < s.length()) {
// Add the character at the right pointer to the window
char rightChar = s.charAt(right);
if (charCount[rightChar - 'a'] == 0) {
uniqueCount++;
}
charCount[rightChar - 'a']++;
right++;
// Shrink the window from the left if the window size exceeds minSize
if (right - left > minSize) {
char leftChar = s.charAt(left);
if (charCount[leftChar - 'a'] == 1) {
uniqueCount--;
}
charCount[leftChar - 'a']--;
left++;
}
// If the window size is equal to minSize and has valid unique characters
if (right - left == minSize && uniqueCount <= maxLetters) {
String substring = s.substring(left, right);
frequencyMap.put(substring, frequencyMap.getOrDefault(substring, 0) + 1);
maxOccurrence = Math.max(maxOccurrence, frequencyMap.get(substring));
}
}
// Return the maximum occurrence of any valid substring
return maxOccurrence;
}
}
3. Python Try on Compiler
def max_freq(s, max_letters, min_size, max_size):
# Frequency map to store occurrences of valid substrings
frequency_map = {}
# Variable to track the maximum occurrence of any valid substring
max_occurrence = 0
# To track frequency of each character (a-z)
char_count = [0] * 26
# To track the number of unique characters in the current window
unique_count = 0
# Left pointer for sliding window
left = 0
# Right pointer for sliding window
right = 0
# Slide the right pointer over the string
while right < len(s):
# Character at the right pointer
right_char = s[right]
# If it's the first occurrence of the character, increment unique_count
if char_count[ord(right_char) - ord('a')] == 0:
unique_count += 1
# Increment character count
char_count[ord(right_char) - ord('a')] += 1
# Move right pointer
right += 1
# Shrink the window from the left if the window size exceeds minSize
if right - left > min_size:
# Character at the left pointer
left_char = s[left]
# If this was the last occurrence of the character, decrement unique_count
if char_count[ord(left_char) - ord('a')] == 1:
unique_count -= 1
# Decrement character count
char_count[ord(left_char) - ord('a')] -= 1
# Move left pointer
left += 1
# If the window size is equal to minSize and has valid unique characters
if right - left == min_size and unique_count <= max_letters:
# Get the current substring
substring = s[left:right]
# Increment its count
frequency_map[substring] = frequency_map.get(substring, 0) + 1
# Update max_occurrence if needed
max_occurrence = max(max_occurrence, frequency_map[substring])
# Return the maximum occurrence of any valid substring
return max_occurrence 4. JavaScript Try on Compiler
function maxFreq(s, maxLetters, minSize, maxSize) {
// Frequency map to store occurrences of valid substrings
const frequencyMap = {};
let maxOccurrence = 0; // Variable to track the maximum occurrence of any valid substring
// To track frequency of each character (a-z)
const charCount = new Array(26).fill(0);
// To track the number of unique characters in the current window
let uniqueCount = 0;
// Left pointer for sliding window
let left = 0;
// Right pointer for sliding window
let right = 0;
// Slide the right pointer over the string
while (right < s.length) {
const rightChar = s[right]; // Character at the right pointer
// If it's the first occurrence of the character, increment uniqueCount
if (charCount[rightChar.charCodeAt(0) - 'a'.charCodeAt(0)] === 0) {
uniqueCount++;
}
// Increment character count
charCount[rightChar.charCodeAt(0) - 'a'.charCodeAt(0)]++;
right++; // Move right pointer
// Shrink the window from the left if the window size exceeds minSize
if (right - left > minSize) {
const leftChar = s[left]; // Character at the left pointer
// If this was the last occurrence of the character, decrement uniqueCount
if (charCount[leftChar.charCodeAt(0) - 'a'.charCodeAt(0)] === 1) {
uniqueCount--;
}
// Decrement character count
charCount[leftChar.charCodeAt(0) - 'a'.charCodeAt(0)]--;
// Move left pointer
left++;
}
// If the window size is equal to minSize and has valid unique characters
if (right - left === minSize && uniqueCount <= maxLetters) {
// Get the current substring
const substring = s.substring(left, right);
// Increment its count
frequencyMap[substring] = (frequencyMap[substring] || 0) + 1;
// Update maxOccurrence if needed
maxOccurrence = Math.max(maxOccurrence, frequencyMap[substring]); }
}
// Return the maximum occurrence of any valid substring
return maxOccurrence;
}
Time Complexity: O(n x k)
1. Outer While Loop: The right pointer iterates through the entire string s , which takes O(n) time, where n is the length of the string.
2. Inner Logic:
• Each character is processed at most twice: once when the right pointer moves to the character and once when the left pointer moves past it. Therefore, the combined operations involving the left and right pointers take O(n) time.
• Checking and updating the character counts in charcount and updating uniqueCount is done in 0(1) time since there are a fixed number of characters (26 letters in the English alphabet).
3. Substring Operations: Extracting a substring when the window size is equal to minSize can take O(k) time, where k is minSize . Since this check only happens at most O(n) times, it contributes at most O(n • k).
Overall Time Complexity: The time complexity of the entire algorithm is dominated by the O(n • k) from the substring extraction.
Therefore, the overall time complexity is: O(n • k)
Space Complexity: O(n)
Auxiliary Space Complexity
Auxiliary space complexity refers to the extra space used by the algorithm, excluding the input size:
Frequency Map: The frequencyMap stores substrings as keys and their counts as values. In the worst case, the number of unique valid substrings can be up to O(n), but the practical number will depend on the distribution of characters. Thus, the worst-case auxiliary space complexity can be considered O(n).
Character Count Array: The charCount array has a fixed size of 26 (for the letters 'a' to 'z'), which contributes
O(1) to auxiliary space.
Other Variables: Variables such as maxOccurrence, left, right, and uniqueCount use constant space O(1).
The Overall Auxiliary Space Complexity: The most significant component is the frequency map, leading to: O(n)
Total Space Complexity
Total space complexity includes both the input size and auxiliary space. The input string s contributes O(n) space, while the auxiliary space is also O(n) from the frequency map.
Thus, the total space complexity is : O(n)+O(n)=O(n)
Learning Tip:
Longest Substring Without Repeating Characters
Count the Number of Substrings With Dominant Ones
Longest Continuous Subarray With Absolute Diff Less Than or Equal to Limit
Longest Repeating Character Replacement