H-Index II Solution In C++/Java/Python/JS
Problem Description:
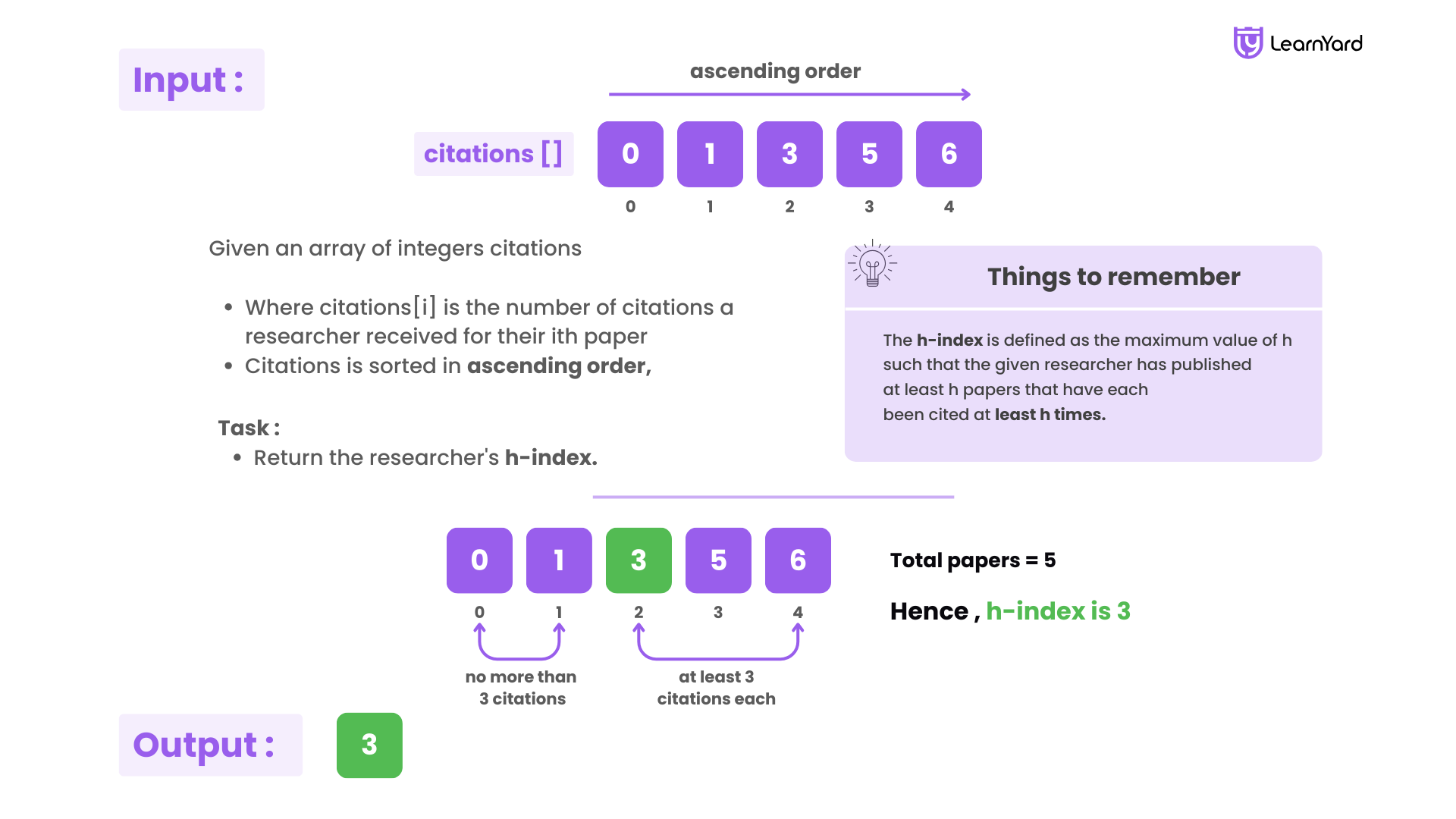
Given an array of integers citations where citations[i] is the number of citations a researcher received for their ith paper and citations is sorted in ascending order, return the researcher's h-index.
According to the definition of h-index on Wikipedia: The h-index is defined as the maximum value of h such that the given researcher has published at least h papers that have each been cited at least h times.
You must write an algorithm that runs in logarithmic time.
Examples:
Input: citations = [0,1,3,5,6]
Output: 3
Explanation: [0,1,3,5,6] means the researcher has 5 papers in total, and each of them had received 0, 1, 3, 5, 6 citations, respectively.
Since the researcher has 3 papers with at least 3 citations each and the remaining two with no more than 3 citations each, their h-index is 3.
Input: citations = [1,2,100]
Output: 2
Explanation: [0,2,100] means the researcher has 3 papers in total, and each of them had received 0, 2, 100 citations, respectively.
Since the researcher has 2 papers with at least 2 citations each and the remaining one with no more than 2 citations each, their h-index is 2.
Constraints:
- n == citations.length
- 1 <= n <= 105
- 0 <= citations[i] <= 1000
- citations is sorted in ascending order.
H-Index II problem
You have a sorted array of citations, where the larger values are at the end. The goal is to find the h-index, which is the highest number h such that there are at least h papers with h or more citations.
Since the array is sorted, can we use this property to build our brute-force solution?
Brute Force Approach
Imagine we have a collection of research papers, and each paper has been cited by other researchers. These citation numbers are sorted in ascending order, with the least cited paper at the beginning of the list and the most cited one at the end. The goal is to determine our h-index,
What is an h-index?
The h-index represents the maximum number of papers a researcher has that have each been cited at least that many times. It is a widely used metric for evaluating academic productivity and citation impact. For example, in an array of citation counts for 5 papers, say [1, 2, 3, 4, 5], there are 3 papers that have at least 3 or more citations, making the h-index 3.
When discussing h-index rankings, understanding what is a good h-index is crucial. A "good" h-index depends on the field of study and career stage:
- Early-career researchers might have an h-index in the range of 2-5.
- Mid-career researchers may aim for 10-20.
- Established researchers often achieve an h-index of 30 or higher.
Higher h-index values typically indicate a more significant academic contribution.
H-Index II Solution:
Start by considering the last number in our list, which is the highest citation count. If this number is greater than zero, it means we have at least one paper with at least one citation, so we can say our h-index is at least one. Next, we move backward through the list, one step at a time, checking whether the citation count at each position allows us to increase our h-index further.
For instance, to see if we can achieve an h-index of two, we look at the second last number in our list. If this number is at least two, it means the last two papers each have at least two citations, so our h-index can be increased to two. We continue this process, moving backward and checking each number in the list, comparing it to the h-index we are aiming for.
The key is to identify the point where the number of papers with citations equal to or greater than a certain value no longer meets the criteria for increasing the h-index. When we reach a position where the citation count is less than the h-index we are aiming for, we stop. The highest value we found before this condition fails is our h-index.
In essence, we are iteratively checking each citation count in our list, from the highest to the lowest, to find the maximum h-index. This method ensures we accurately determine the number of papers with a sufficient number of citations to meet the h-index criteria.
Dry run
Input: [1, 1, 2, 3, 3, 4, 5]
Output: 3
Explanation: [1, 1, 2, 3, 3, 4, 5] means the researcher has 3 papers in total and each of them had received 1, 1, 2, 3, 3, 4, 5 citations respectively.
Since the researcher has 3 papers with at least 3 citations each and the remaining 4 with no more than 3 citations each, their h-index is 2.
Initial Setup:
- citations = [1, 1, 2, 3, 3, 4, 5]
- n = 7
- ans = 0
Iteration 1 (i = 6):
- citations[6] = 5
- 5 >= ans + 1 → 5 >= 0 + 1 (True)
- Since this condition is true, increment ans: ans = 1.
Iteration 2 (i = 5):
- citations[5] = 4
- 4 >= ans + 1 → 4 >= 1 + 1 (True)
- Since this condition is true, increment ans: ans = 2.
Iteration 3 (i = 4):
- citations[4] = 3
- 3 >= ans + 1 → 3 >= 2 + 1 (True)
- Since this condition is true, increment ans: ans = 3.
Iteration 4 (i = 3):
- citations[3] = 3
- 3 >= ans + 1 → 3 >= 3 + 1 (False)
- Since this condition is false, the loop breaks.
Result:
- The loop stops when i = 3, and the final value of ans is 3.
So, the h-index for this array of citations [1, 1, 2, 3, 3, 4, 5] is 3.
Steps to write code
Step 1: Initialize Variables:
- Start by determining the size of the citations array. The variable
nwill hold this value. - Initialize a variable ans to 0, which will keep track of the h-index value.
Step 2: Iterate through the citations array:
- Start iterating from the last index of the array (i = n - 1) and work towards the first index. This ensures that we check the largest values first.
- The loop condition should be i >= 0 to ensure it iterates through all elements in the array.
Step 3: Check if the citation count meets the condition:
- In each iteration, check if the current citation value (citations[i]) is greater than or equal to ans + 1. This means, for each citation, we are checking if it can contribute to an increasing h-index.
- If the condition is true, increment ans by 1, as this citation can help achieve a higher h-index.
- If the condition is false, stop the iteration by breaking out of the loop, as further elements cannot increase the h-index anymore.
Step 4: Return the result:
- Once the loop finishes, return the value of ans as the h-index.
H-Index II solution
H-Index II solution in c++
class Solution {
public:
// Function to calculate the h-index
int hIndex(vector<int>& citations) {
// Get the size of the citations array
int n = citations.size();
// Initialize the answer to 0
int ans = 0;
// Loop through the citations from the last element to the first
for(int i = n - 1; i >= 0; --i) {
// If the current citation count is greater than or equal to the current h-index+1
if(citations[i] >= ans + 1) {
// Increment the h-index
ans++;
} else {
// Break the loop once the condition fails
break;
}
}
// Return the final h-index
return ans;
}
};H-Index II solution in java
class Solution {
// Function to calculate the h-index
public int hIndex(int[] citations) {
// Get the length of the citations array
int n = citations.length;
// Initialize the h-index to 0
int ans = 0;
// Loop through the citations array from the last element to the first
for (int i = n - 1; i >= 0; --i) {
// If the current citation count is greater than or equal to the current h-index+1
if (citations[i] >= ans + 1) {
// Increment the h-index
ans++;
} else {
// Break the loop once the condition fails
break;
}
}
// Return the final h-index
return ans;
}
}H-Index II solution in python
class Solution:
# Function to calculate the h-index
def hIndex(self, citations: List[int]) -> int:
# Get the length of the citations list
n = len(citations)
# Initialize the h-index to 0
ans = 0
# Loop through the citations list from the last element to the first
for i in range(n-1, -1, -1):
# If the current citation count is greater than or equal to the current h-index+1
if citations[i] >= ans + 1:
# Increment the h-index
ans += 1
else:
# Break the loop once the condition fails
break
# Return the final h-index
return ansH-Index II solution in Javascript
/**
* @param {number[]} citations
* @return {number}
*/
var hIndex = function(citations) {
// Get the length of the citations array
let n = citations.length;
// Initialize the h-index to 0
let ans = 0;
// Loop through the citations array from the last element to the first
for (let i = n - 1; i >= 0; --i) {
// If the current citation count is greater than or equal to the current h-index + 1
if (citations[i] >= ans + 1) {
// Increment the h-index
ans++;
} else {
// Break the loop once the condition fails
break;
}
}
// Return the final h-index
return ans;
};
Complexity Analysis of the solution:
Time Complexity: O(n)
Iteration through the Array:
- The loop runs from the last index of the array (n-1) to the first index (0).
- This means the loop runs n times in the worst case, where n is the size of the citations array.
Operations inside the Loop:
- Inside the loop, you perform constant-time operations:
- The comparison citations[i] >= ans + 1 is an O(1) operation.
- If the condition is met, you increment ans, which is also O(1).
- If the condition fails, the loop is broken early, but the worst case is still O(n) when no break occurs.
Hence, the overall time complexity of the code is O(n)
Space Complexity: O(1)
Auxiliary Space Complexity:
Auxiliary space refers to the extra space or temporary space used by the algorithm, excluding the input data.
- In this code, the only extra space used is for the variables:
- n: Stores the size of the input array. This is a single integer, so it takes O(1) space.
- ans: Stores the current count of the h-index. It’s also a single integer, so it takes O(1) space.
Thus, the auxiliary space complexity is O(1) (constant space).
Total Space Complexity:
Total space includes both the space used by the input data and the auxiliary space.
- The input array citations takes O(n) space, where n is the number of elements in the array.
- The auxiliary space, as discussed earlier, is O(1).
Therefore, the total space complexity is O(n) because the input array dominates the space usage.
Is the brute force approach efficient?
The brute force takes O(n) time. The constraints allow n to go up to 105. In one second system can perform 106 operations easily. Hence our complexity is within limits. This means the solution will easily pass all the testcases.
The problem wants us to write a solution with logarithmic time complexity. Hence, we need to optimize it further. Let's see how we can do this.
Optimal Approach
Intuition:
To make the solution faster, we don't want to check every index in the array. Instead, we need to focus on a part of the array where we are confident we can find the answer.
Since the array is sorted, we can use this to our advantage. To find an h such that at least h papers have h or more citations, we can look at the last h values of the array. This is because the larger values at the end of the array are more likely to meet the condition of having at least h citations, making it easier and quicker to find the correct h-index.
Let's visualize this. We start by assuming last h values satisfy the h-index condition. Meaning, those values will have at least h citations or more. We can also say that values at the end of the list with counts less than h will also satisfy the h-index condition because they fit within the criteria for the last h values. However, the values immediately after these h values, such as the last h+1 or h+2 values, won't satisfy the condition. Meaning The last 1 or 2 values considered after the last h values won't have the citations at least h+1 or h+2. Do you see it?.
This means there is a breakpoint after which there are at least h papers with h or more citations. Before this breakpoint, there are some papers with citations fewer than h, which prevents us from selecting them for the h-index.
Let's pick an index i from the array. To find the h-index, we need at least h values with h or more citations, so we'll focus on the right side of i. This means we consider all values from index i to n-1.
We then check if the count of numbers from i to n-1 can be the h-index. If this check is true, it means all values to the right of i meet the h-index condition because they are all equal to or greater than the value at i.
By focusing on this range, we can efficiently determine if the h-index criteria are met without having to check every value in the array. This approach makes it easier to identify the maximum h-index.
How do we check if an index i satisfies the h-index condition?
An index i is valid if the value at i is greater than or equal to the number of elements from i to the end of the array.
The last index in the array is n-1, so the count of elements from i+1 to n-1 is n-1-i. Including i itself, the total number of elements from i to the end is: count = n-i
Now, to check if i is a valid h-index, we simply verify: value at i ≥ n−i
If this condition is met, it means there are at least n - i papers with n - i or more citations.
What do we do next?
- If i satisfies the condition, we know that all values to the right of i will also satisfy it.
- However, we move left to check if we can find a better h-index (a larger h). This is because moving left increases the value of h, potentially leading to a better answer.
Example
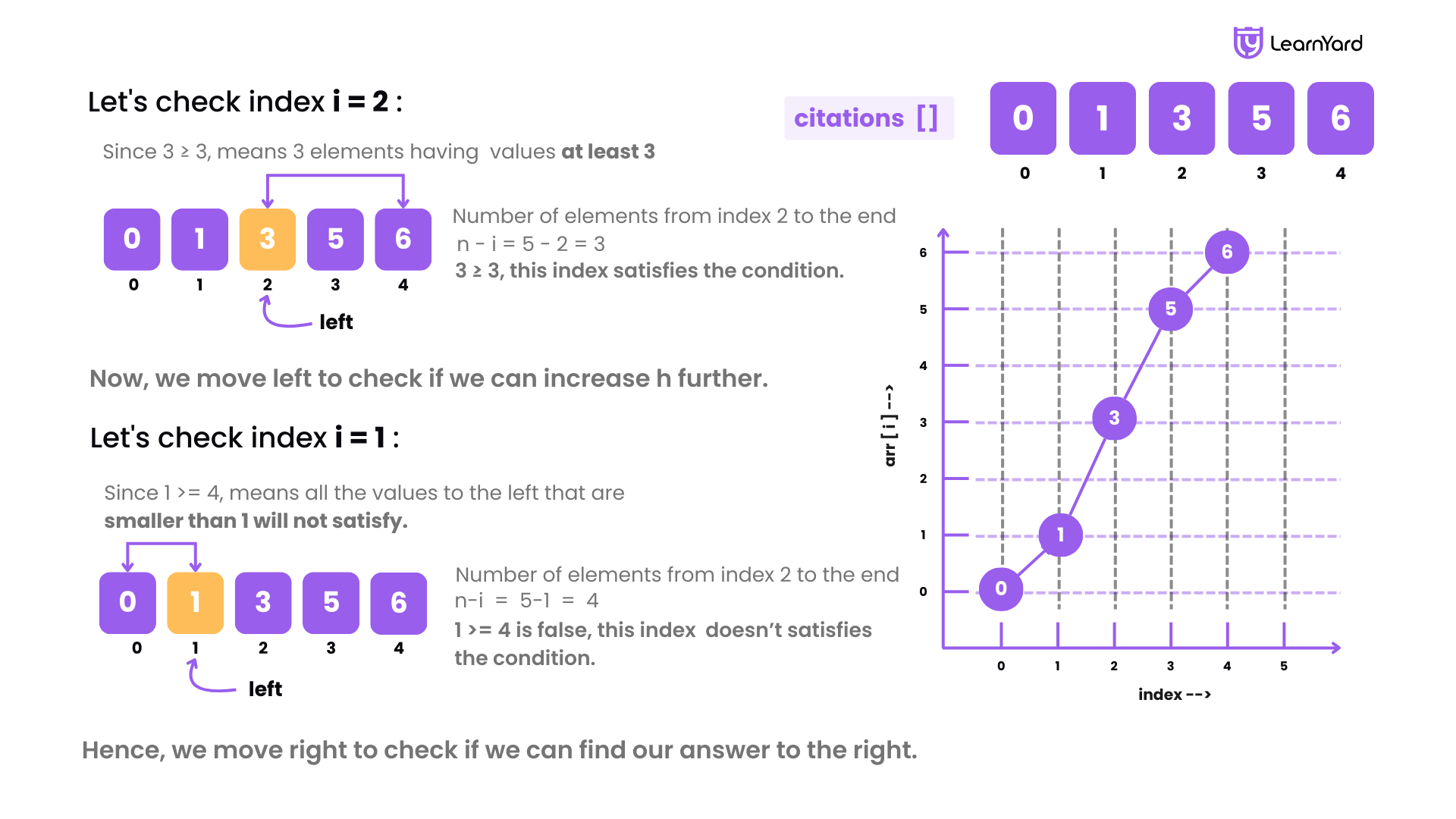
Suppose we have the sorted citations array: [0, 1, 3, 5, 6]
Let's check index i = 2 (value = 3).
- Number of elements from index 2 to the end = n - i = 5 - 2 = 3.
- Since 3 ≥ 3, this index satisfies the condition. This means there 3 elements that have their values at least 3.
Now, we move left to check if we can increase h further.
Let's check index i = 1 (value = 1)
- Number of elements from index 1 to the end = n-i = 5-1 = 4.
- Since 1 >= 4 is false. This means that all the values to the left that are smaller than 1 will also not satisfy it.
Hence, we move right to check if we can find our answer to the right.
H-index II Algorithm:
Initially, we define our search space using variables low and high. They lie at the two ends of the array. low at 0 and high at n-1.
The arbitrary index i we select is a middle index of the array. We apply to this middle index and choose either the or right side. Then we do the same again for the reduced search space.
At the end of the loop, the variable low will point to the smallest index where all the papers to the right have enough citations to satisfy the h-index condition. The problem asks us to find the highest possible h-index, which means the largest number of papers with either left or right side at least that many citations. To get this value, we return n-low, which gives us the count of papers that meet the h-index requirement.
This process of continuously reducing the search space to get closer to the answer is called binary search. If you want to know more about binary search refer to this article.
Let us understand this with a video,
h-index-ii-optimal-animation
Dry run
Input: [1, 1, 2, 3, 3, 4, 5]
Output: 3
Explanation: [1, 1, 2, 3, 3, 4, 5] means the researcher has 3 papers in total and each of them had received 1, 1, 2, 3, 3, 4, 5 citations respectively.
Since the researcher has 3 papers with at least 3 citations each and the remaining 4 with no more than 3 citations each, their h-index is 2.
Initial Values:
- n = 7 (size of citations)
- low = 0, high = 6
Iteration 1:
- mid = (0 + 6) / 2 = 3
- Check: citations[3] = 3
- Condition: citations[3] >= n - mid → 3 >= 7 - 3 → 3 >= 4 (False)
- Since the condition fails, update low = mid + 1 = 4
Iteration 2:
- mid = (4 + 6) / 2 = 5
- Check: citations[5] = 4
- Condition: citations[5] >= n - mid → 4 >= 7 - 5 → 4 >= 2 (True)
- Update high = mid - 1 = 4
Iteration 3:
- mid = (4 + 4) / 2 = 4
- Check: citations[4] = 3
- Condition: citations[4] >= n - mid → 3 >= 7 - 4 → 3 >= 3 (True)
- Update high = mid - 1 = 3
Loop Exit Condition:
low > high → low = 4, high = 3
Final Calculation:
- return n - low = 7 - 4 = 3
Final Output: 3
Steps to write code
Step 1: Find the Number of Papers
- Get the total number of papers n using citations.size().
Step 2: Initialize Search Range
- Set low = 0 (starting index).
- Set high = n - 1 (ending index).
Step 3: Start Binary Search
- Use a while loop to run the binary search while low <= high.
Step 4: Find the Middle Index
- Compute mid = (low + high) / 2.
Step 5: Check If Mid Satisfies H-Index Condition
- If citations[mid] is greater than or equal to n - mid:
- Move high to mid - 1 (search for a smaller index where condition holds).
- Else:
- Move low to mid + 1 (search for a larger index with a valid h-index).
Step 6: Compute the Final H-Index
- The search stops when low reaches the smallest index where all values to the right satisfy the h-index condition.
- Return n - low as the final h-index.
H-Index II leetcode solution
H-Index II solution in C++
class Solution {
public:
// Function to calculate the h-index
int hIndex(vector<int>& citations) {
// Get the total number of papers
int n = citations.size();
// Initialize low and high pointers for binary search
int low = 0, high = n-1;
// Perform binary search
while(low <= high) {
// Calculate mid-point of the current range
int mid = (low + high) / 2;
// If the number of citations at mid is greater than or equal to the remaining papers
if(citations[mid] >= n - mid) {
// If so, the h-index could be greater, so move the high pointer
high = mid - 1;
}
else {
// If not, adjust the low pointer
low = mid + 1;
}
}
// Return the h-index, which is the remaining number of papers
return n - low;
}
};H-Index II solution in java
class Solution {
public int hIndex(int[] citations) {
// Get the total number of papers (size of citations array)
int n = citations.length;
// Initialize low and high pointers for binary search
int low = 0, high = n - 1;
// Perform binary search to find the h-index
while (low <= high) {
// Calculate mid-point of the current range
int mid = (low + high) / 2;
// If the number of citations at mid is greater than or equal to the remaining papers
if (citations[mid] >= n - mid) {
// If so, adjust high to search in the left side of the range
high = mid - 1;
} else {
// If not, adjust low to search in the right side of the range
low = mid + 1;
}
}
// Return the h-index, which is the remaining number of papers
return n - low;
}
}H-Index II solution in python
class Solution:
def hIndex(self, citations: List[int]) -> int:
# Get the total number of papers (size of citations list)
n = len(citations)
# Initialize low and high pointers for binary search
low, high = 0, n - 1
# Perform binary search to find the h-index
while low <= high:
# Calculate mid-point of the current range
mid = (low + high) // 2
# If the number of citations at mid is greater than or equal to the remaining papers
if citations[mid] >= n - mid:
# If so, adjust high to search in the left side of the range
high = mid - 1
else:
# If not, adjust low to search in the right side of the range
low = mid + 1
# Return the h-index, which is the remaining number of papers
return n - lowH-Index II solution in Javascript
/**
* @param {number[]} citations
* @return {number}
*/
var hIndex = function(citations) {
// Get the number of papers (length of citations array)
let n = citations.length;
// Initialize low and high pointers for binary search
let low = 0, high = n - 1;
// Perform binary search to find the h-index
while (low <= high) {
// Calculate mid-point of the current range
let mid = Math.floor((low + high) / 2);
// If the number of citations at mid is greater than or equal to the remaining papers
if (citations[mid] >= n - mid) {
// Adjust high to search the left side of the range
high = mid - 1;
} else {
// Adjust low to search the right side of the range
low = mid + 1;
}
}
// Return the h-index, which is the remaining number of papers
return n - low;
};
Complexity Analysis of the Solution:
Time Complexity: O(log n)
Initializing Variables
- The initialization of n, low, and high takes O(1) time because assigning values and computing the size of the array are constant-time operations.
While Loop Execution
- The algorithm runs a while loop that performs a binary search, reducing the search space by half in each iteration.
- Binary search works by repeatedly dividing the search range in half until the correct index is found.
Breaking It Down
- At the beginning: The search space has n elements.
- After 1st iteration: The search space is reduced to n/2.
- After 2nd iteration: The search space is n/4.
- After k iterations: The search space becomes n / 2k.
The search ends when only one element remains, which happens when: n/2k = 1
Taking log base 2 on both sides: k=log2(n)
Thus, binary search runs in O(log n) time complexity
- Inside each iteration:
- Finding mid (middle index) takes O(1) time.
- The comparison citations[mid] >= n - mid takes O(1) time.
- Updating low or high also takes O(1) time.
Returning the Final Result
- The result is computed using n - low, which is a single arithmetic operation.
- This takes O(1) time.
Hence, overall time complexity is O(logn
Space Complexity: O(1)
Auxiliary Space Complexity (Extra Memory Used)
- The algorithm uses only a few integer variables:
- n (size of the array) → O(1)
- low, high, and mid (index tracking variables) → O(1)
- No extra data structures (like arrays, lists, or recursion stack) are used.
The Auxiliary space complexity is O(1)
Total Space Complexity (Including Input Storage)
- The input citations array is passed as a parameter. Since it is given as input, it is not counted as extra space.
- The total space required consists of:
- The input array O(n) (already given).
- The auxiliary space O(1).
The Total space complexity is O(n) (dominated by input array storage)
Similar Problems
Now we have successfully tackled this problem, let's try these similar problems:-
1. H-Index
Given an array of integers citations where citations[i] is the number of citations a researcher received for their ith paper, return the researcher's h-index.
According to the definition of h-index on Wikipedia: The h-index is defined as the maximum value of h such that the given researcher has published at least h papers that have each been cited at least h times.