People Whose List of Favorite Companies is Not a Subset of Another List Solution In C++/Python/Java/Javascript
Problem Description:
Given the array favoriteCompanies where favoriteCompanies[i] is the list of favorite companies for the i-th person (indexed from 0):
Return the indices of people whose list of favorite companies is not a subset of any other list of favorite companies. You must return the indices in increasing order.
Examples:
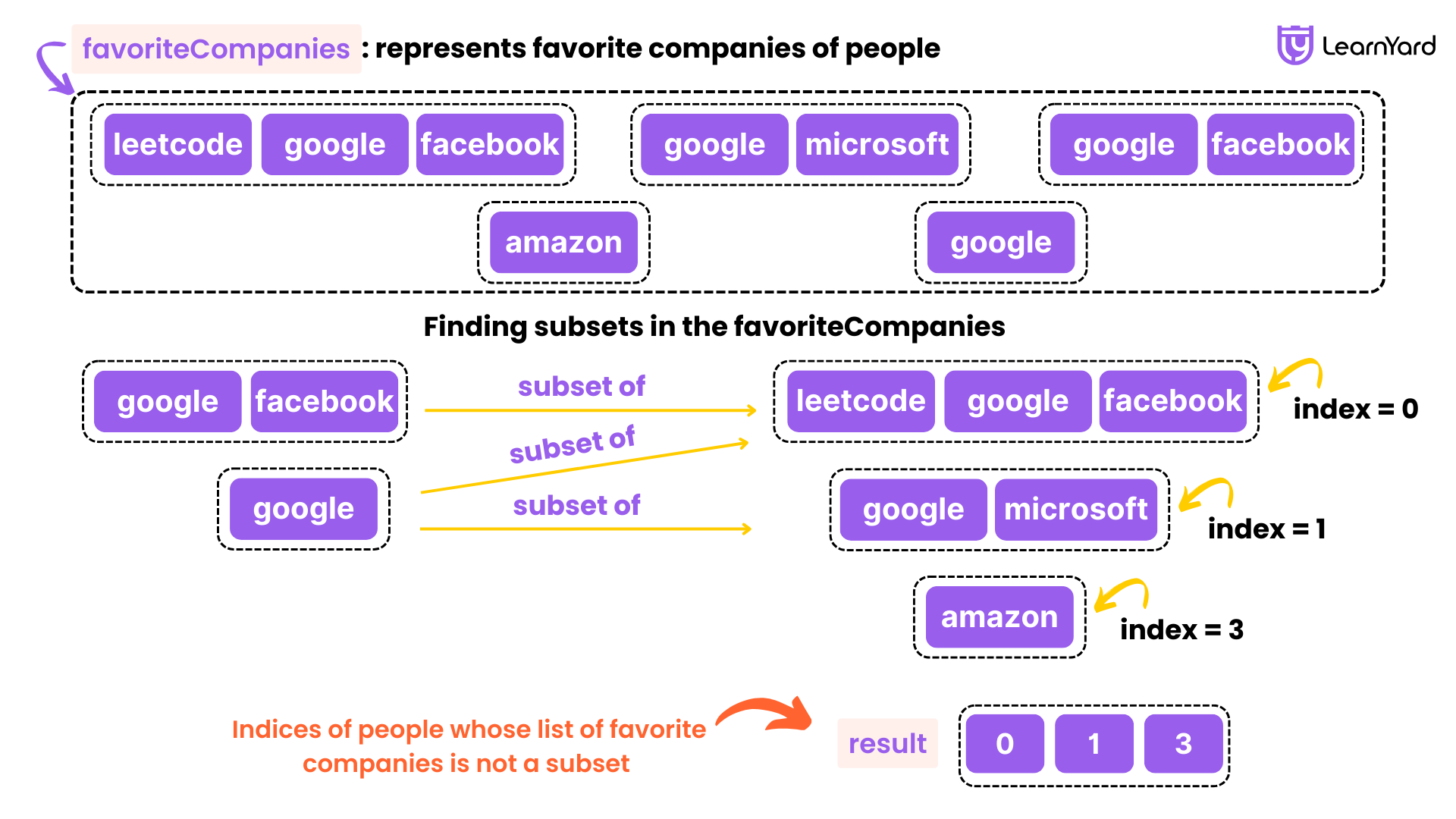
Input: favoriteCompanies = [["leetcode","google","facebook"],["google","microsoft"],["google","facebook"],["google"],["amazon"]]
Output: [0,1,4]
Explanation: Person with index=2 has favoriteCompanies[2]=["google","facebook"], which is a subset of favoriteCompanies[0]=["leetcode","google","facebook"] corresponding to the person with index 0.
Person with index=3 has favoriteCompanies[3]=["google"], which is a subset of favoriteCompanies[0]=["leetcode","google","facebook"] and favoriteCompanies[1]=["google","microsoft"].
Other lists of favorite companies are not a subset of another list; therefore, the answer is [0,1,4].
Input: favoriteCompanies = [["leetcode","google","facebook"],["leetcode","amazon"],["facebook","google"]]
Output: [0,1]
Explanation: In this case, favoriteCompanies[2]=["facebook","google"] is a subset of favoriteCompanies[0]=["leetcode","google","facebook"]; therefore, the answer is [0,1].
Input: favoriteCompanies = [["leetcode"],["google"],["facebook"],["amazon"]]
Output: [0,1,2,3]
Explanation: In this case, none of the lists is a subset of any other list. Each person has a unique favorite company, and no person's list of favorite companies can be found entirely within someone else's list.
Thus, all indices [0, 1, 2, 3] are included in the output.
Constraints:
1 <= favoriteCompanies.length <= 100
1 <= favoriteCompanies[i].length <= 500
1 <= favoriteCompanies[i][j].length <= 20
All strings in favoriteCompanies[i] are distinct.
All lists of favorite companies are distinct, that is, if we sort alphabetically each list, then favoriteCompanies[i] != favoriteCompanies[j].
All strings consist of lowercase English letters only.
Brute Force Approach:
When we read the problem statement, the first idea that comes to mind is simple:
In the brute-force approach, the solution involves iterating over every index and checking whether the list of favorite companies at that index is a subset of any other list belonging to any other index in the array. Here is the detailed step-by-step process:
- Iterate through each index (i):
For every index i in the array favoriteCompanies, treat it as the current list to evaluate. - Check subset condition:
For each index i, iterate through the entire array and check if the list at favoriteCompanies[i] is a subset of any other list favoriteCompanies[j] (where i ≠ j).
If favoriteCompanies[i] is a subset of favoriteCompanies[j], skip this index and move to the next. - Add valid indices to the result:
If the list at favoriteCompanies[i] is not a subset of any other list, add the index i to the result. - Return the result:
At the end, return the list of indices that meet the criteria in increasing order.
Let's understand with an example:
Input: favoriteCompanies = [["leetcode", "google", "facebook"], ["google", "microsoft"], ["google", "facebook"], ["google"], ["amazon"]]
- Outer Loop (i=0):
- Compare ["leetcode", "google", "facebook"] with all other lists.
- Subset Check:
- Compare with i=1: Not a subset.
- Compare with i=2: Not a subset.
- Compare with i=3: Not a subset.
- Compare with i=4: Not a subset.
- Result: Add index 0 to the result.
- Outer Loop (i=1):
- Compare ["google", "microsoft"] with all other lists.
- Subset Check:
- Compare with i=0: Not a subset.
- Compare with i=2: Not a subset.
- Compare with i=3: Not a subset.
- Compare with i=4: Not a subset.
- Result: Add index 1 to the result.
- Outer Loop (i=2):
- Compare ["google", "facebook"] with all other lists.
- Subset Check:
- Compare with i=0: Subset (["google", "facebook"] ⊆ ["leetcode", "google", "facebook"]).
- Result: Skip index 2.
- Outer Loop (i=3):
- Compare ["google"] with all other lists.
- Subset Check:
- Compare with i=0: Subset.
- Compare with i=1: Subset.
- Result: Skip index 3.
- Outer Loop (i=4):
- Compare ["amazon"] with all other lists.
- Subset Check:
- Compare with i=0: Not a subset.
- Compare with i=1: Not a subset.
- Compare with i=2: Not a subset.
- Compare with i=3: Not a subset.
- Result: Add index 4 to the result.
Final Result: [0, 1, 4]
How to code it up?
- Initialize the Result List:
Create an empty list or array result to store indices of lists that are not subsets of any other list. - Iterate Over All Indices:
Use an outer loop to go through each index i in the input list. - Subset Check Initialization:
For each index i, initialize a boolean variable isSubset as false to track whether the current list is a subset of another list. - Nested Loop for Comparison:
Use an inner loop to compare the list at index i with all other lists (index j), ensuring i ≠ j. - Check for Subset Condition:
- Assume the list at index i is a subset of the list at index j.
- Iterate through all elements of the list at i.
- If any element in i is missing from the list at j, mark it as not a subset and exit the inner loop.
- Update Result:
If the list at i is not a subset of any other list (i.e., isSubset remains false), add the index i to the result list. - Return the Result:
After processing all indices, return the result list containing indices in increasing order.
Code Implementation
1. C++ Try on Compiler
class Solution {
public:
vector<int> peopleIndexes(vector<vector<string>>& favoriteCompanies) {
// Initialize an empty vector to store the result
vector<int> result;
// Get the number of people (lists) in the favoriteCompanies array
int n = favoriteCompanies.size();
// Iterate over each person's favorite companies list
for (int i = 0; i < n; i++)
{
// Flag to check if the current person's favorite companies list is a subset of any other
bool isSubset = false;
// Compare with every other person's favorite companies list
for (int j = 0; j < n; j++)
{
// Skip comparison with the same person (i != j)
if (i != j)
{
// Assume the list is a subset unless proven otherwise
bool subset = true;
// Check if each company in person i's list is in person j's list
for (const auto& company : favoriteCompanies[i])
{
// If a company from person i's list is not found in person j's list, it's not a subset
if (find(favoriteCompanies[j].begin(), favoriteCompanies[j].end(), company) == favoriteCompanies[j].end()) {
subset = false;
// No need to check further, as the subset condition is already violated
break;
}
}
// If person i's list is a subset of person j's list, set the flag to true
if (subset) {
isSubset = true;
// No need to check with other lists, as we've already found it's a subset
break;
}
}
}
// If person i's list is not a subset of any other list, add their index to the result
if (!isSubset) {
result.push_back(i);
}
}
// Return the list of indices of people whose lists are not subsets of others
return result;
}
};
2. Java Try on Compiler
import java.util.*;
class Solution {
public List<Integer> peopleIndexes(List<List<String>> favoriteCompanies) {
// Initialize an empty list to store the result
List<Integer> result = new ArrayList<>();
// Get the number of people (lists) in the favoriteCompanies array
int n = favoriteCompanies.size();
// Iterate over each person's favorite companies list
for (int i = 0; i < n; i++) {
// Flag to check if the current person's favorite companies list is a subset of any other
boolean isSubset = false;
// Compare with every other person's favorite companies list
for (int j = 0; j < n; j++) {
// Skip comparison with the same person (i != j)
if (i != j) {
// Assume the list is a subset unless proven otherwise
boolean subset = true;
// Check if each company in person i's list is in person j's list
for (String company : favoriteCompanies.get(i)) {
// If a company from person i's list is not found in person j's list, it's not a subset
if (!favoriteCompanies.get(j).contains(company)) {
subset = false;
// No need to check further, as the subset condition is already violated
break;
}
}
// If person i's list is a subset of person j's list, set the flag to true
if (subset) {
isSubset = true;
// No need to check with other lists, as we've already found it's a subset
break;
}
}
}
// If person i's list is not a subset of any other list, add their index to the result
if (!isSubset) {
result.add(i);
}
}
// Return the list of indices of people whose lists are not subsets of others
return result;
}
}
3. Python Try on Compiler
class Solution:
def peopleIndexes(self, favoriteCompanies):
# Initialize an empty list to store the result
result = []
# Get the number of people (lists) in the favoriteCompanies array
n = len(favoriteCompanies)
# Iterate over each person's favorite companies list
for i in range(n):
# Flag to check if the current person's favorite companies list is a subset of any other
isSubset = False
# Compare with every other person's favorite companies list
for j in range(n):
# Skip comparison with the same person (i != j)
if i != j:
# Assume the list is a subset unless proven otherwise
subset = True
# Check if each company in person i's list is in person j's list
for company in favoriteCompanies[i]:
# If a company from person i's list is not found in person j's list, it's not a subset
if company not in favoriteCompanies[j]:
subset = False
# No need to check further, as the subset condition is already violated
break
# If person i's list is a subset of person j's list, set the flag to True
if subset:
isSubset = True
# No need to check with other lists, as we've already found it's a subset
break
# If person i's list is not a subset of any other list, add their index to the result
if not isSubset:
result.append(i)
# Return the list of indices of people whose lists are not subsets of others
return result
4. Javascript Try on Compiler
/**
* @param {string[][]} favoriteCompanies
* @return {number[]}
*/
var peopleIndexes = function (favoriteCompanies) {
// Initialize an empty array to store the result
let result = [];
// Get the number of people (lists) in the favoriteCompanies array
let n = favoriteCompanies.length;
// Iterate over each person's favorite companies list
for (let i = 0; i < n; i++) {
// Flag to check if the current person's favorite companies list is a subset of any other
let isSubset = false;
// Compare with every other person's favorite companies list
for (let j = 0; j < n; j++) {
// Skip comparison with the same person (i != j)
if (i !== j) {
// Assume the list is a subset unless proven otherwise
let subset = true;
// Check if each company in person i's list is in person j's list
for (const company of favoriteCompanies[i]) {
// If a company from person i's list is not found in person j's list, it's not a subset
if (!favoriteCompanies[j].includes(company)) {
subset = false;
// No need to check further, as the subset condition is already violated
break;
}
}
// If person i's list is a subset of person j's list, set the flag to true
if (subset) {
isSubset = true;
// No need to check with other lists, as we've already found it's a subset
break;
}
}
}
// If person i's list is not a subset of any other list, add their index to the result
if (!isSubset) {
result.push(i);
}
}
// Return the list of indices of people whose lists are not subsets of others
return result;
};Time Complexity: O(n² * m * p)
The time complexity of the given approach can be analyzed as follows:
- Outer Loop (Iterating over each person i):
This loop runs for all n people in the favoriteCompanies array, so it runs n times. - Inner Loop (Iterating over each person j to compare with person i):
For each person i, we compare their list with every other person's list. Hence, this loop also runs n times. - Innermost Loop (Checking if a company in person i's list exists in person j's list):
The number of companies for each person can vary, so for person i, there are m companies, and for person j, there are p companies.
For each company in person i's list (with m companies), we perform a find() operation in person j's list (which has p companies).
The find() operation will take O(p) time for each company in person i's list.
So the time complexity for the innermost loop is O(m * p).
Total Time Complexity:
- The outer loop runs n times.
- The inner loop also runs n times.
- The innermost loop performs O(m * p) work for each comparison (where m and p are the number of companies in person i's and person j's lists, respectively).
Thus, the overall time complexity is: O(n * n * m * p) = O(n² * m * p)
Where:
- n is the number of people (lists),
- m is the number of companies in person i's list,
- p is the number of companies in person j's list.
Space Complexity: O(n * m)
Auxiliary Space Complexity: O(n)
We are taking a result vector, which can store at most n indices when no index is a subset of any other. Therefore, the auxiliary space complexity will be O(n).
Total Space Complexity: O(n * m)
The input is the favoriteCompanies array, which contains n lists, each having a number of companies (up to m for each list). The space for the input is O(n * m) (where m is the maximum number of companies in any list).
Adding this to the auxiliary space gives: Total Space = O(n * m)
Will Brute Force Work Against the Given Constraints?
For the current solution, the time complexity is O(n² * m * p), where n is the number of people (lists) and m and p represent the number of companies in the lists of person i and person j, respectively.
The worst-case time complexity is O(n² * m * p). For the largest input size, where n = 100, m = 500, and p = 500, the number of operations would be:
O(100² * 500 * 500) = O(10⁸ * 500) = O(2.5 × 10⁹) operations.
This results in 2.5 × 10⁹ operations for n = 100, which is too large and could lead to Time Limit Exceeded (TLE) errors. Competitive programming environments typically allow up to 10⁸ or 10⁹ operations per test case, making this solution inefficient for larger inputs or multiple test cases.
In most competitive programming environments, the solution could easily exceed the time limit when there are multiple test cases, especially if n increases to its maximum of 100 and the number of companies per person reaches 500.
Thus, while the solution meets the time limits for small input sizes, the O(n² * m * p) time complexity poses a significant risk for TLE errors with larger test cases or multiple test cases.
Can we optimize it?
Yes, of course!
We can definitely optimize it—let's do it!
In the previous approach, for each index i, we were checking every other index j of the array. Then, for each string of index i, we compared it with all the strings of index j, which resulted in a time complexity of O(n² * m * p).
Now, let’s consider whether we can optimize this part.
We are essentially checking if all strings of index i are present in the strings of index j.
Can we make this more efficient?
Yes, we can use a HashSet!
What is a HashSet?
A HashSet is a data structure that stores a collection of unique elements without any particular order. It uses a hash table internally to provide efficient lookups, insertions, and deletions with average time complexity of O(1).
The idea is to store all strings for each index in a HashSet. For each index i, we can then simply check if all of its strings are present in the HashSet of any index j. By doing this, we eliminate the need for the nested for loop that checks all strings of index i with all strings of index j.
Now to sum up:
- For each index, store all its strings in a corresponding HashSet.
- For each index i, check all other indices j. For each string in index i, check if it is present in the HashSet of index j.
- If all strings of index i are found in the HashSet of index j, skip it. Otherwise, add index i to the result.
By using a HashSet, the time complexity for checking if a string exists in another list becomes O(1) on average, which reduces the overall time complexity significantly. This optimization can help handle larger inputs more efficiently.
Let's understand with an example:
Input: favoriteCompanies = [["leetcode", "google", "facebook"], ["google", "microsoft"], ["google", "facebook"], ["google"], ["amazon"]]
Step 1: Store all strings in corresponding HashSets
HashSet for index 0: {"leetcode", "google", "facebook"}
HashSet for index 1: {"google", "microsoft"}
HashSet for index 2: {"google", "facebook"}
HashSet for index 3: {"google"}
HashSet for index 4: {"amazon"}
Step 2: Compare index i with all other indices j
- For i = 0:
- Compare with j = 1, 2, 3, 4: No other index contains all companies of i = 0.
- Result: Add 0 to result.
- For i = 1:
- Compare with j = 0, 2, 3, 4: No other index contains all companies of i = 1.
- Result: Add 1 to result.
- For i = 2:
- Compare with j = 0: All companies of i = 2 are in j = 0's HashSet.
- Result: Skip 2 (since it's a subset).
- For i = 3:
- Compare with j = 0: All companies of i = 3 are in j = 0's HashSet.
- Result: Skip 3 (since it's a subset).
- For i = 4:
- Compare with j = 0, 1, 2, 3: No other index contains all companies of i = 4.
- Result: Add 4 to result.
Output: [0, 1, 4]
How to code it up:
Here are the concise generic steps to implement the solution:
- Initialize Variables:
Get the size of the input list favoriteCompanies as n.
Create a vector of unordered sets (vec), with each element representing a set of companies for each person. - Store Companies in HashSets:
For each person's list of favorite companies, convert it into an unordered set and store it in vec[i] (for person i). - Iterate Over All Persons:
For each person i, initialize a flag isSubset to false to track whether their list is a subset of any other person's list. - Compare with Other Persons:
For each other person j:
Skip comparison if i = j (same person).
If vec[i] is not larger than vec[j] (to avoid unnecessary checks), check if all companies in vec[i] are present in vec[j].
Use the count() function on vec[j] to check if each company in vec[i] exists in vec[j]. If any company is not found, mark it as not a subset and break the loop. - Update Result:
If i's list is not a subset of any other list, add i to the result vector ans. - Return the Result:
Return the vector ans containing indices of persons whose lists are not subsets of others.
Code Implementation
1. C++ Try on Compiler
class Solution {
public:
vector<int> peopleIndexes(vector<vector<string>>& favoriteCompanies) {
// Get the number of people (lists) in the favoriteCompanies array
int n = favoriteCompanies.size();
// Create a vector of unordered sets to store the companies for each person
vector<unordered_set<string>> vec(n);
// Convert each person's list of favorite companies into an unordered set for fast lookups
for (int i = 0; i < n; i++) {
vec[i] = unordered_set<string>(favoriteCompanies[i].begin(), favoriteCompanies[i].end());
}
// Initialize a vector to store the result (indices of people whose lists are not subsets)
vector<int> ans;
// Iterate over each person's favorite companies list
for (int i = 0; i < n; i++) {
// Flag to check if the current person's list is a subset of any other list
bool isSubset = false;
// Compare the current person's list with every other person's list
for (int j = 0; j < n; j++) {
// Skip comparison with the same person (i != j)
if (i != j && vec[i].size() <= vec[j].size()) {
// Assume the current list is a subset unless proven otherwise
bool subset = true;
// Check if each company in person i's list is found in person j's list
for (const auto& company : vec[i]) {
if (vec[j].count(company) == 0) {
// If any company is not found, it's not a subset
subset = false;
break;
}
}
// If the list is a subset, mark isSubset as true and break the loop
if (subset) {
isSubset = true;
break;
}
}
}
// If the current person's list is not a subset of any other list, add their index to the result
if (!isSubset) {
ans.push_back(i);
}
}
// Return the indices of the people whose lists are not subsets of others
return ans;
}
};
2. Java Try on Compiler
import java.util.*;
class Solution {
public List<Integer> peopleIndexes(List<List<String>> favoriteCompanies) {
// Get the number of people (lists) in the favoriteCompanies array
int n = favoriteCompanies.size();
// Create a list of HashSets to store the companies for each person
List<HashSet<String>> vec = new ArrayList<>(n);
// Convert each person's list of favorite companies into a HashSet for fast lookups
for (int i = 0; i < n; i++) {
vec.add(new HashSet<>(favoriteCompanies.get(i)));
}
// Initialize a list to store the result (indices of people whose lists are not subsets)
List<Integer> ans = new ArrayList<>();
// Iterate over each person's favorite companies list
for (int i = 0; i < n; i++) {
// Flag to check if the current person's list is a subset of any other list
boolean isSubset = false;
// Compare the current person's list with every other person's list
for (int j = 0; j < n; j++) {
// Skip comparison with the same person (i != j)
if (i != j && vec.get(i).size() <= vec.get(j).size()) {
// Assume the current list is a subset unless proven otherwise
boolean subset = true;
// Check if each company in person i's list is found in person j's list
for (String company : vec.get(i)) {
if (!vec.get(j).contains(company)) {
// If any company is not found, it's not a subset
subset = false;
break;
}
}
// If the list is a subset, mark isSubset as true and break the loop
if (subset) {
isSubset = true;
break;
}
}
}
// If the current person's list is not a subset of any other list, add their index to the result
if (!isSubset) {
ans.add(i);
}
}
// Return the indices of the people whose lists are not subsets of others
return ans;
}
}
3. Python Try on Compiler
class Solution:
def peopleIndexes(self, favoriteCompanies):
# Get the number of people (lists) in the favoriteCompanies array
n = len(favoriteCompanies)
# Create a list of sets to store the companies for each person
vec = [set(companies) for companies in favoriteCompanies]
# Initialize a list to store the result (indices of people whose lists are not subsets)
ans = []
# Iterate over each person's favorite companies list
for i in range(n):
# Flag to check if the current person's list is a subset of any other list
isSubset = False
# Compare the current person's list with every other person's list
for j in range(n):
# Skip comparison with the same person (i != j)
if i != j and len(vec[i]) <= len(vec[j]):
# Assume the current list is a subset unless proven otherwise
subset = True
# Check if each company in person i's list is found in person j's list
for company in vec[i]:
if company not in vec[j]:
# If any company is not found, it's not a subset
subset = False
break
# If the list is a subset, mark isSubset as true and break the loop
if subset:
isSubset = True
break
# If the current person's list is not a subset of any other list, add their index to the result
if not isSubset:
ans.append(i)
# Return the indices of the people whose lists are not subsets of others
return ans
4. Javascript Try on Compiler
var peopleIndexes = function(favoriteCompanies) {
// Get the number of people (lists) in the favoriteCompanies array
let n = favoriteCompanies.length;
// Create an array of sets to store the companies for each person
let vec = favoriteCompanies.map(companies => new Set(companies));
// Initialize an array to store the result (indices of people whose lists are not subsets)
let ans = [];
// Iterate over each person's favorite companies list
for (let i = 0; i < n; i++) {
// Flag to check if the current person's list is a subset of any other list
let isSubset = false;
// Compare the current person's list with every other person's list
for (let j = 0; j < n; j++) {
// Skip comparison with the same person (i != j)
if (i !== j && vec[i].size <= vec[j].size) {
// Assume the current list is a subset unless proven otherwise
let subset = true;
// Check if each company in person i's list is found in person j's list
for (let company of vec[i]) {
if (!vec[j].has(company)) {
// If any company is not found, it's not a subset
subset = false;
break;
}
}
// If the list is a subset, mark isSubset as true and break the loop
if (subset) {
isSubset = true;
break;
}
}
}
// If the current person's list is not a subset of any other list, add their index to the result
if (!isSubset) {
ans.push(i);
}
}
// Return the indices of the people whose lists are not subsets of others
return ans;
};
Time Complexity: O(n² * m)
Let's break down the time complexity for the optimized approach step by step:
- Creating HashSets for each person's favorite companies:
We iterate over each person's favorite companies list, and for each list, we convert it into a HashSet.
The time complexity to convert each list of companies (with m companies) into a HashSet is O(m).
So, for n people, the total time complexity for this step is O(n * m), where m is the average number of companies per person. - Comparing each person's list with every other person's list:
For each person i, we compare their HashSet of companies with every other person's list (i.e., for every j where i ≠ j).
The outer loop runs n times, iterating over all the people.
For each person i, the inner loop also runs n times, comparing the set of person i with each of the other people's sets. So, the nested loops contribute O(n²). - Checking if a company's string is present in another person's HashSet:
For each company in person i's list, we check if it is present in the HashSet of person j using Set.contains().
The time complexity of Set.contains() is O(1) on average.
We iterate over each company of person i, so for each comparison, we perform O(m) operations (where m is the size of person i's list). This gives us a time complexity of O(m) for each comparison of two lists.
Total Time Complexity:
- Creating the HashSets for all people: O(n * m).
- Comparing each person's list with every other person's list:
- Outer loop runs n times.
- Inner loop runs n times.
- For each pair of lists, we perform a comparison of m companies. So, the time complexity for the comparison step is O(n² * m).
Thus, the overall time complexity is: O(n * m) + O(n² * m)
Since O(n² * m) dominates O(n * m) when n² > n, the final time complexity is: O(n² * m)
Space Complexity: O(n * m)
- Auxiliary Space Complexity: O(n * m)
We create a vector of HashSets to store each person's favorite companies. The size of the vector is n, and each HashSet can store up to m companies. So, the auxiliary space used for storing the HashSets is O(n * m). - Total Space Complexity: O(n * m)
The input consists of n lists, each with up to m companies. The space required for the input is O(n * m).
Thus, the total space complexity is O(n * m).
Can there be any other approach?
You're absolutely right! We can indeed optimize the solution further.
In our previous approach, we used hashsets to store the favorite companies for each person. Then, for each person, we compared their list with every other person's list by iterating through each company and checking its presence in the other person's hashset. This resulted in an O(n² * m) time complexity, where 'n' is the number of people and 'm' is the average number of companies per person.
We improved upon this by using hashmaps to index the companies, which reduced the time complexity for some operations. But can we do even better?
The key observation is that we can compare the "presence" of strings more efficiently. Instead of directly comparing strings, we can assign a unique integer ID to each distinct string. For example: "google" → 1, "facebook" → 2, "leetcode" → 3.
Since we have a maximum of 100 people and each person can have up to 500 companies, we can have at most 100 * 500 = 50,000 unique strings.
Now, for each person, we can create a bitmask. This bitmask will be a binary string where each bit represents the presence or absence of a particular string. If a string is in the person's list, the corresponding bit in the bitmask will be set to 1, otherwise, it will be 0.
Suppose we take two binary numbers a = 10 (which is 1010 in binary) and b = 11 (which is 1011 in binary). If we perform a bitwise AND operation between a and b, the result will be a & b = 10 & 11 = 10, which is equal to a. This means that the set bits (1s) of number a are contained within number b, and that's why the result of the operation is a.
Similarly, to check if person i's favorite companies are a subset of person j's favorite companies, we perform a bitwise AND operation between their respective bitmasks: bitmasks[i] & bitmasks[j]. If the result of this operation is equal to bitmasks[i], it means that every number which is set in bitmasks[i] is also set in bitmask[j], and since numbers in bitmask are unique integer IDs of companies, it means that every company that person i likes is also liked by person j, indicating that i's list of favorite companies is a subset of j's.
This bitwise operation can be performed in constant time, significantly improving the efficiency of our subset checks.
By using this bitmasking technique, we can effectively represent the presence/absence of each string with a single bit, enabling us to perform efficient subset checks using bitwise operations.
Let's understand with and example:
Input:
favoriteCompanies = [["leetcode", "google", "facebook"], ["google", "microsoft"], ["google", "facebook"], ["google"], ["amazon"]]
Step 1: Assign Unique Numbers
Assign unique numbers to each company:
- "leetcode" → 0, "google" → 1, "facebook" → 2, "microsoft" → 3, "amazon" → 4
Step 2: Create Bitmasks for Each Index
Convert each index into a bitmask:
- Index 0: ["leetcode", "google", "facebook"] → Bitmask: 111 (binary for {0, 1, 2})
- Index 1: ["google", "microsoft"] → Bitmask: 1010 (binary for {1, 3})
- Index 2: ["google", "facebook"] → Bitmask: 110 (binary for {1, 2})
- Index 3: ["google"] → Bitmask: 10 (binary for {1})
- Index 4: ["amazon"] → Bitmask: 10000 (binary for {4})
Step 3: Compare Using Bitwise Operations
Iterate over all indices and compare with others:
- Index 0 (111):
Compare with all other indices: - Index 1 (1010): (111 & 1010 != 111) → Not a subset
- Index 2 (110): (111 & 110 != 111) → Not a subset
- Index 3 (10): (111 & 10 != 111) → Not a subset
- Index 4 (10000): (111 & 10000 != 111) → Not a subset
→ Add 0 to result
- Index 1 (1010):
Compare with all other indices: - Index 0 (111): (1010 & 111 != 1010) → Not a subset
- Index 2 (110): (1010 & 110 != 1010) → Not a subset
- Index 3 (10): (1010 & 10 != 1010) → Not a subset
- Index 4 (10000): (1010 & 10000 != 1010) → Not a subset
→ Add 1 to result
- Index 2 (110):
Compare with all other indices: - Index 0 (111): (110 & 111 == 110) → Subset → Skip
→ Do not add 2 to result
- Index 0 (111): (110 & 111 == 110) → Subset → Skip
- Index 3 (10):
Compare with all other indices: - Index 0 (111): (10 & 111 == 10) → Subset → Skip
→ Do not add 3 to result
- Index 0 (111): (10 & 111 == 10) → Subset → Skip
- Index 4 (10000):
Compare with all other indices: - None match as a superset → Add 4 to result
Final Result: Indices: [0, 1, 4]
How to code it up:
- Map Each Unique String to an Index
- Use a mapping data structure (like a hash map) to assign a unique index to each distinct company.
- Create Bitmasks for Each Index
- For each person's list of favorite companies, create a bitmask where bits corresponding to the indices of the companies are set.
- Compare Bitmasks for Subset Condition
- Traverse through all pairs of indices i and j.
- For each pair, check if (bitmask[i] & bitmask[j] == bitmask[i]), meaning all companies in index i are present in j.
- Store Non-Subset Indices
- If an index is not a subset of any other, add it to the result list.
- Return the Result
- Return the list of indices that are not subsets of others.
Code Implementation
1. C++ Try on Compiler
class Solution {
public:
vector<int> peopleIndexes(vector<vector<string>>& favoriteCompanies) {
// Map each company to a unique index
unordered_map<string, int> companyIndex;
int index = 0;
// Assign unique indices to companies
for (const auto& companies : favoriteCompanies) {
for (const auto& company : companies) {
if (companyIndex.find(company) == companyIndex.end()) {
companyIndex[company] = index++;
}
}
}
// Determine the size of the bitset
int maxCompanies = index;
// Create a vector of bitsets to represent favorite companies
vector<bitset<50001>> bitmasks(favoriteCompanies.size());
// Create bitmask for each person
for (int i = 0; i < favoriteCompanies.size(); i++) {
for (const auto& company : favoriteCompanies[i]) {
bitmasks[i].set(companyIndex[company]);
}
}
// Vector to store the result
vector<int> ans;
// Compare each bitmask to find subsets
for (int i = 0; i < bitmasks.size(); i++) {
bool isSubset = false;
// Check if current bitmask is a subset of any other
for (int j = 0; j < bitmasks.size(); j++) {
if (i != j && (bitmasks[i] & bitmasks[j]) == bitmasks[i]) {
isSubset = true;
break;
}
}
// Add index to the result if not a subset
if (!isSubset) {
ans.push_back(i);
}
}
// Return the result
return ans;
}
};
2. Java Try on Compiler
import java.util.*;
class Solution {
public List<Integer> peopleIndexes(List<List<String>> favoriteCompanies) {
// Map each company to a unique index
Map<String, Integer> companyIndex = new HashMap<>();
int index = 0;
// Assign unique indices to companies
for (List<String> companies : favoriteCompanies) {
for (String company : companies) {
companyIndex.putIfAbsent(company, index++);
}
}
// Determine the size of the bitmask
int maxCompanies = index;
// Create a list of bitsets to represent favorite companies
List<BitSet> bitmasks = new ArrayList<>();
for (List<String> companies : favoriteCompanies) {
BitSet bitmask = new BitSet(maxCompanies);
for (String company : companies) {
bitmask.set(companyIndex.get(company));
}
bitmasks.add(bitmask);
}
// List to store the result
List<Integer> result = new ArrayList<>();
// Compare each bitmask to find subsets
for (int i = 0; i < bitmasks.size(); i++) {
boolean isSubset = false;
// Check if current bitmask is a subset of any other
for (int j = 0; j < bitmasks.size(); j++) {
if (i != j && isSubset(bitmasks.get(i), bitmasks.get(j))) {
isSubset = true;
break;
}
}
// Add index to the result if not a subset
if (!isSubset) {
result.add(i);
}
}
// Return the result
return result;
}
// Helper function to check if one BitSet is a subset of another
private boolean isSubset(BitSet a, BitSet b) {
BitSet temp = (BitSet) a.clone(); // Clone BitSet `a` to avoid modification
temp.and(b); // Perform AND operation with `b`
return temp.equals(a); // Check if result is equal to `a`
}
}
3. Python Try on Compiler
class Solution:
def peopleIndexes(self, favoriteCompanies):
# Map each company to a unique index
company_index = {}
index = 0
# Assign unique indices to companies
for companies in favoriteCompanies:
for company in companies:
if company not in company_index:
company_index[company] = index
index += 1
# Determine the size of the bitmask
max_companies = index
# Create a list of bitmasks to represent favorite companies
bitmasks = []
for companies in favoriteCompanies:
bitmask = 0
for company in companies:
bitmask |= (1 << company_index[company])
bitmasks.append(bitmask)
# List to store the result
result = []
# Compare each bitmask to find subsets
for i in range(len(bitmasks)):
is_subset = False
# Check if current bitmask is a subset of any other
for j in range(len(bitmasks)):
if i != j and (bitmasks[i] & bitmasks[j]) == bitmasks[i]:
is_subset = True
break
# Add index to the result if not a subset
if not is_subset:
result.append(i)
# Return the result
return result
4. Javascript Try on Compiler
const peopleIndexes = (favoriteCompanies) => {
const companyIndex = new Map();
let index = 0;
// Assign unique indices to companies
for (const companies of favoriteCompanies) {
for (const company of companies) {
if (!companyIndex.has(company)) {
companyIndex.set(company, index++);
}
}
}
const maxCompanies = index;
const bitmasks = new Array(favoriteCompanies.length).fill(0).map(() => 0n);
// Create bitmask for each person
for (let i = 0; i < favoriteCompanies.length; i++) {
for (const company of favoriteCompanies[i]) {
bitmasks[i] |= BigInt(1) << BigInt(companyIndex.get(company));
}
}
const ans = [];
// Compare each bitmask to find subsets
for (let i = 0; i < bitmasks.length; i++) {
let isSubset = false;
for (let j = 0; j < bitmasks.length; j++) {
if (i !== j && (bitmasks[i] & bitmasks[j]) === bitmasks[i]) {
isSubset = true;
break;
}
}
if (!isSubset) {
ans.push(i);
}
}
return ans;
};Time Complexity: O(n² + n * m)
The time complexity of the JavaScript solution can be broken down as follows:
- Mapping Companies to Unique Indices:
For each person's list of companies, we iterate over each company to map it to a unique index.
Given n people and m companies per person, this takes O(n * m) time. - Creating the Bitmask:
For each person, we create a bitmask by iterating over their list of companies. Setting the corresponding bit in the bitmask requires O(m) time for each person.
Since there are n people, the total time to create all bitmasks is O(n * m). - Checking Subsets:
For each pair of people (i and j), we check if the bitmask of person i is a subset of person j using the bitwise AND operation.
This check involves comparing all bits in the bitmasks, which takes O(1) time (since the bitmask size is constant and limited by the number of companies).
Since we are comparing all pairs of people, this step takes O(n²) time.
Overall Time Complexity:
- Mapping companies to indices: O(n * m)
- Creating bitmasks: O(n * m)
- Checking subsets: O(n²)
Thus, the overall time complexity is O(n² + n * m), which can be simplified to O(n * m) since n * m dominates n², since n <= 100 and m <= 500.
Space Complexity: O(n² * m)
- Auxiliary Space Complexity: O(n² * m)
The auxiliary space is used for the companyIndex map and the bitmasks array. Therefore, the auxiliary space is O(n * m) for the companyIndex map and O(n * (n * m)) for the bitmasks. Thus, the auxiliary space complexity is O(n² * m). - Total Space Complexity: O(n * m)
The input is the favoriteCompanies array, which contains n lists, and each list can have up to m strings. Therefore, the input space is O(n * m).
Thus, the total space complexity is O(n² * m).
Learning Tip
Now we have successfully tackled this problem, let's try these similar problems.
1. Word Subsets
You are given two lists of words: words1 and words2.
A word from words2 is called a subset of a word in words1 if:All the letters in the word from words2 are present in the word from words1.
And each letter appears at least as many times in the word from words1 as it does in the word from words2.For example:
"wrr" is a subset of "warrior" (because "warrior" has at least 2 'r's and one 'w').
But "wrr" is not a subset of "world" (because "world" doesn’t have 2 'r's).A word from words1 is called universal if:
Every word in words2 is a subset of it.The goal is to return all the universal words from words1.
You are given an array of strings of the same length words.
In one move, you can swap any two even indexed characters or any two odd indexed characters of a string words[i].
Two strings words[i] and words[j] are special-equivalent if after any number of moves, words[i] == words[j].For example, words[i] = "zzxy" and words[j] = "xyzz" are special-equivalent because we may make the moves "zzxy" -> "xzzy" -> "xyzz".
A group of special-equivalent strings from words is a non-empty subset of words such that:
1. Every pair of strings in the group are special equivalent, and
2. The group is the largest size possible (i.e., there is not a string words[i] not in the group such that words[i] is special-equivalent to every string in the group).Return the number of groups of special-equivalent strings from words.