Optimal Partition of String Solution In C++/Python/Java/Javascript
Problem Description:
Given a string s, partition the string into one or more substrings such that the characters in each substring are unique. That is, no letter appears in a single substring more than once.
Return the minimum number of substrings in such a partition.
Note that each character should belong to exactly one substring in a partition.
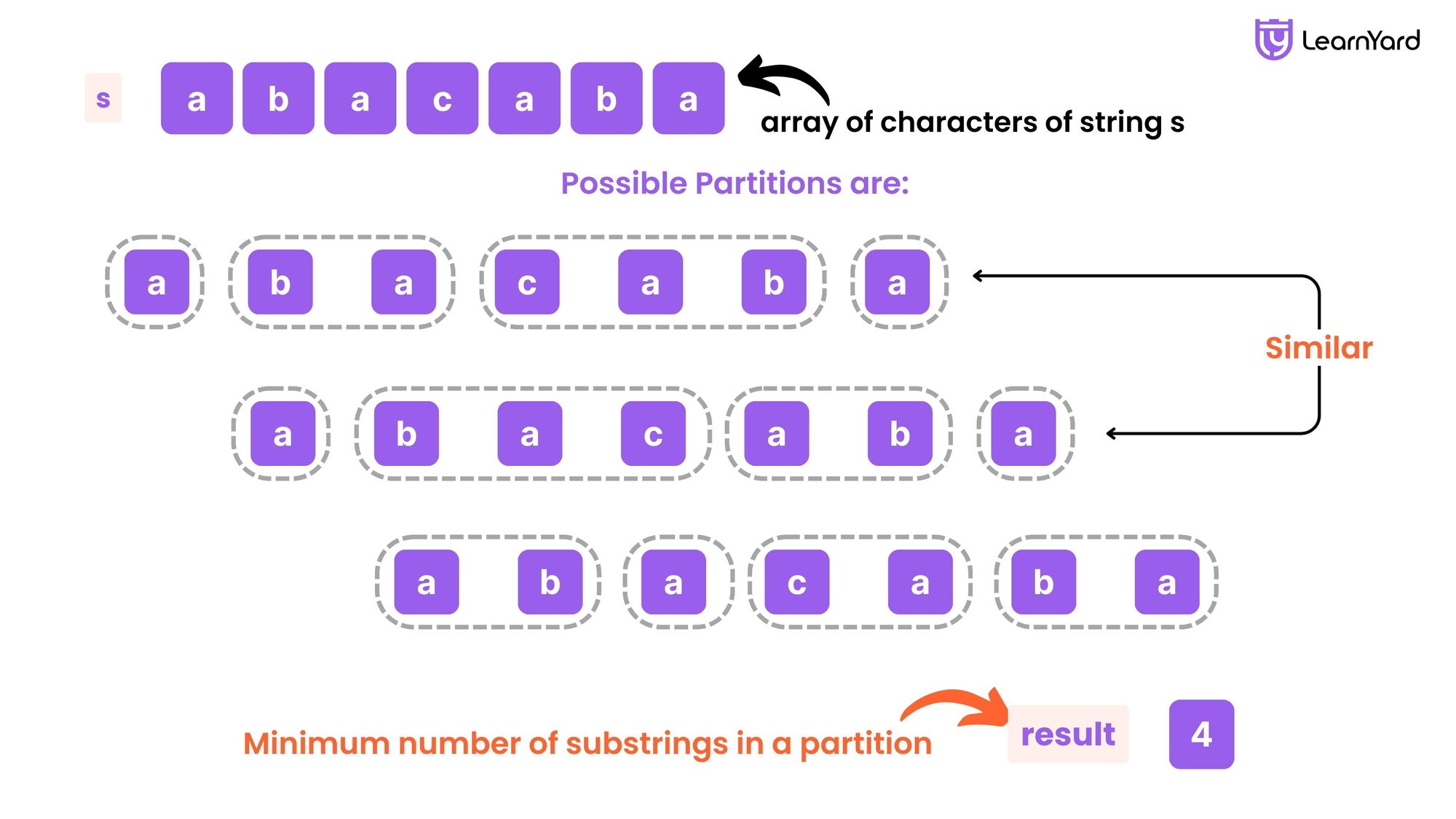
Examples:
Input: s = "abacaba"
Output: 4
Explanation: Two possible partitions are ("a","ba","cab","a") and ("ab","a","ca","ba").
It can be shown that 4 is the minimum number of substrings needed.
Input: s = "ssssss"
Output: 6
Explanation: The only valid partition is ("s","s","s","s","s","s").
Constraints:
1 <= s.length <= 10⁵
s consists of only English lowercase letters.
Brute Force Approach
Okay, so here's the thought process:
What comes to mind after reading the problem statement?
We need to partition the string such that each character in the substrings formed after partition appears exactly once, and the number of substrings is minimized.
A substring is a contiguous part of the string, and our goal is to find the minimum number of substrings after partitioning.
To find the minimum number of substrings, what do we need to do?
We need to maximize the length of each substring so that we can break the string s into the minimum number of substrings.
Ok, so we need to maximize the length of each substring.
How much maximum length can a substring achieve?
It could have the maximum length such that no character occurs twice.
It means that whenever a character comes twice, we need to start a new portion, right?
As we need to break it into substrings, and a valid partition should not contain two same characters.
Ok, to sum up:
We will iterate over the string and cut a new portion till any character doesn’t come twice.
How can we do it?
To solve the problem using the brute force approach, we need to find the largest substring we can cut out at each step such that all characters in the substring are unique. If we can form such a substring, we check if it can be extended further. If not, we cut the string at that point and move to the next partition.
Steps to Frame the Approach:
- Start with one complete string: Begin with the entire string as one potential substring.
- Initialize the answer: Set the initial number of partitions (answer) to 1 since we start with the entire string.
- Outer loop: Use a loop to iterate through the string from the starting index of each potential substring.
- For each starting index, assume you are attempting to form the largest possible substring starting from this index.
- Second loop: Use another loop to extend the substring from the starting index and check if it remains valid.
- A valid substring means that no character appears more than once.
- Two nested loops for validation: For every substring being considered, use two more nested loops to check if any character in the current substring repeats:
- Loop through all characters in the substring.
- Compare each character with every other character in the substring to detect duplicates.
- If a duplicate is found:
- Increment the partition count (answer) because we now need to cut the string at this point.
- Break out of the current loop since the substring cannot be extended further.
- Repeat the process: Start forming the next substring from the next character after the current partition and continue until the end of the string.
- Final answer: Return the total count of substrings (answer), which represents the minimum number of partitions needed.
This approach ensures that the string is partitioned into the minimum number of substrings, each with unique characters.
Let's understand with an example:
Dry Run of Brute Force for s = "abacaba":
Initial State:
- String: "abacaba"
- Partitions (answer): 1
- Start at index i = 0, attempt to form the largest substring:
Substring = "a": Valid (no duplicates).
Substring = "ab": Valid (no duplicates).
Substring = "aba": Invalid (duplicate 'a').
Cut the string → Increment answer to 2. - Start new substring at index i = 2:
Substring = "a": Valid (no duplicates).
Substring = "ac": Valid (no duplicates).
Substring = "aca": Invalid (duplicate 'a').
Cut the string → Increment answer to 3. - Start new substring at index i = 4:
Substring = "a": Valid (no duplicates).
Substring = "ab": Valid (no duplicates).
Substring = "aba": Invalid (duplicate 'a').
Cut the string → Increment answer to 4. - Start new substring at index i = 4:
Substring = "a": Valid (no duplicates).
End of string
Final Result: Minimum partitions = 4
Substrings: "ab", "ac", "ab", "a".
How to code it up:
Here's the steps to code this up:
- Initialize answer = 1 to start with one partition.
- Use an outer loop to iterate through the string from the starting index (i).
- Use an inner loop to extend the substring starting at index i.
- Use two nested loops to check for duplicates in the current substring:
- Outer loop: Iterate over each character in the substring (from k = i to k = j).
- Inner loop: Compare the character at k with all subsequent characters (from k + 1 to j).
- If a duplicate is found, increment answer and break the inner loop.
- Continue forming substrings from the next character after the partition.
- Return answer as the final result.
Code Implementation
1. C++ Try on Compiler
class Solution {
public:
int partitionString(string s) {
int n = s.length();
// Count of substrings
int answer = 1;
// Step 1: Start from the beginning of the string
for (int i = 0; i < n; i++) {
// Step 2: Loop to check substrings from current position
for (int j = i; j < n; j++) {
bool isUnique = true;
// Step 3: Loop to compare all characters in the current substring
for (int k = i; k <= j; k++) {
for (int l = k + 1; l <= j; l++) {
// Step 4: If characters repeat, the substring is not valid
if (s[k] == s[l]) {
isUnique = false;
break;
}
}
if (!isUnique) break;
}
// Step 5: If the current substring is invalid, increment the count and move to the next partition
if (!isUnique) {
answer++;
// Adjust the position of `i` to start a new partition
i = j - 1;
break;
}
}
}
// Step 6: Increment for the last substring
return answer;
}
};
2. Java Try on Compiler
class Solution {
public int partitionString(String s) {
int n = s.length();
// Count of substrings
int answer = 1;
// Step 1: Start from the beginning of the string
for (int i = 0; i < n; i++) {
// Step 2: Loop to check substrings from current position
for (int j = i; j < n; j++) {
boolean isUnique = true;
// Step 3: Loop to compare all characters in the current substring
for (int k = i; k <= j; k++) {
for (int l = k + 1; l <= j; l++) {
// Step 4: If characters repeat, the substring is not valid
if (s.charAt(k) == s.charAt(l)) {
isUnique = false;
break;
}
}
if (!isUnique) break;
}
// Step 5: If the current substring is invalid, increment the count and move to the next partition
if (!isUnique) {
answer++;
// Adjust the position of `i` to start a new partition
i = j - 1;
break;
}
}
}
// Step 6: Increment for the last substring
return answer;
}
}
3. Python Try on Compiler
class Solution:
def partitionString(self, s):
n = len(s)
# Count of substrings
answer = 1
# Step 1: Start from the beginning of the string
i = 0
while i < n:
# Step 2: Loop to check substrings from current position
for j in range(i, n):
isUnique = True
# Step 3: Loop to compare all characters in the current substring
for k in range(i, j + 1):
for l in range(k + 1, j + 1):
# Step 4: If characters repeat, the substring is not valid
if s[k] == s[l]:
isUnique = False
break
if not isUnique:
break
# Step 5: If the current substring is invalid, increment the count and move to the next partition
if not isUnique:
answer += 1
# Adjust the position of `i` to start a new partition
i = j-1 # start from the next character
break
i += 1
# Step 6: Return the count of partitions
return answer
4. Javascript Try on Compiler
/**
* @param {string} s
* @return {number}
*/
var partitionString = function (s) {
const n = s.length;
// Count of substrings
let answer = 1;
// Step 1: Start from the beginning of the string
for (let i = 0; i < n; i++) {
// Step 2: Loop to check substrings from current position
for (let j = i; j < n; j++) {
let isUnique = true;
// Step 3: Loop to compare all characters in the current substring
for (let k = i; k <= j; k++) {
for (let l = k + 1; l <= j; l++) {
// Step 4: If characters repeat, the substring is not valid
if (s[k] === s[l]) {
isUnique = false;
break;
}
}
if (!isUnique) break;
}
// Step 5: If the current substring is invalid, increment the count and move to the next partition
if (!isUnique) {
answer++;
// Adjust the position of `i` to start a new partition
i = j - 1;
break;
}
}
}
// Step 6: Increment for the last substring
return answer;
};
Time Complexity: O(n⁴)
The time complexity of this code is O(n⁴), where n is the length of the string s. Here's the detailed breakdown of the time complexity:
- Outer loop:
This loop iterates n times because i goes from 0 to n-1. - Second loop:
For each iteration of the outer loop, the second loop runs from i to n-1. This means the second loop runs at most n - i times.
Total iterations for the second loop = n+(n−1)+(n−2)+…+1
This is the sum of the first n integers, hence it has time complexity of O(n). - Third and fourth loops :
These nested loops compare all characters within the current substring (from i to j).
The third loop runs from i to j, so it runs O(j - i + 1) times.
The fourth loop runs from k + 1 to j, so it runs O(j - k) times.
Therefore, the total number of comparisons made by these two nested loops for a given i and j is the sum of all possible pairs of characters within the substring from i to j. This sum is roughly O((n - i)²), because for each value of k, the second loop runs fewer times, but the total number of comparisons over all k will be proportional to the square of the length of the substring.
Total Time Complexity:
- The total time complexity is the product of the time complexities of the loops.
- The outer loop runs O(n) times.
- The second loop runs O(n) times for each iteration of the outer loop.
- The third and fourth nested loops have a complexity of O(n²) in the worst case (comparing characters in the substring).
So, the total time complexity is: O(n) * O(n) * O(n²) = O(n⁴).
The time complexity of this solution is O(n⁴) because of the nested loops comparing all characters in each substring of the string.
Space Complexity: O(n)
Auxiliary Space: O(1)
Explanation: The algorithm only uses a fixed amount of extra space, mainly for variables like the answer, i, j, k, and l.
Total Space Complexity: O(n)
Explanation: The input string s itself occupies space proportional to its length, which is O(n). The visited array also occupies O(n) space.
Therefore, the total space used by the algorithm is O(n).
Will Brute Force Work Against the Given Constraints?
For the current solution, the time complexity is O(n⁴), which is not suitable for n ≤ 10⁵. This means that for each test case, where the size of the string is at most 10⁵, the solution might not execute within the given time limits.
Since O(n⁴) results in a maximum of 10²⁰ operations (for n = 10⁵), the solution is not expected to work well for larger test cases. In most competitive programming environments, problems can handle up to 10⁶ operations per test case, meaning that for n ≤ 10⁵, the solution with 10²⁰ operations is not efficient enough.
When multiple test cases are involved, the total number of operations could easily exceed this limit and approach 10²⁰ operations, especially when there are many test cases or the value of n increases.
Thus, while the solution meets the time limits for a single test case, the O(n⁴) time complexity poses a risk for Time Limit Exceeded (TLE) errors when handling larger input sizes or multiple test cases. This can be a challenge for competitive programming problems with larger inputs or numerous test cases.
Can we optimize it?
In our previous approach, we iterated over the string and kept cutting a new portion until any character appeared twice. We used two nested loops to check for the maximum possible length of a substring, and inside them, we used another two nested loops to check if all the characters in that substring were unique.
However, we don't actually need all these nested loops to check the maximum length of a substring. We are essentially checking each substring and increasing its size as long as no character repeats. Instead of checking every possible substring with multiple loops, we can achieve the same result in a more efficient way.
We can simplify this approach to a single pass through the string. Here's how:
- Start from the first character and keep track of all characters that have been seen in the current substring.
- As we iterate, if we encounter a character that's already in the current substring, we partition the string at that point, increment the number of substrings, and start a new substring from that character.
How can we optimize the detection of a character appearing twice in the substring to make our solution more efficient?
We can use something like faster lookup.
Can you think of some data structure?
Yes, we can use a hash table.
What is a hash table?
A hashtable is a data structure that stores key-value pairs, using a hash function to compute an index for quick access. It offers average O(1) time complexity for operations like insertion, deletion, and lookup.
Our hash table can contain at most 26 indices, as the number of lowercase characters in the English language is 26.
Since we start with the entire string, we initialize the answer to 1 and increment it each time we make a cut or partition the string.
So, whenever we come across a character, we will check if it's already encountered using the hash table.
If yes, we will clear the entire hash table because the new substring will start now as it’s a partition.
Then, we will start inserting characters of the new substring in the hash table and repeat the process till we reach the end of the string.
For each partition, we will increase our answer and at the end, return the answer.
Let's understand with an example:
Dry Run of the Approach on Input s = "abacaba"
Initialize:
- Hash table: Empty (tracks characters in the current substring).
- Answer: 1 (tracks the number of substrings).
Iterating over s = "abacaba":
- First Character: 'a'
Not in the hash table.
Add 'a' to the hash table. - Second Character: 'b'
Not in the hash table.
Add 'b' to the hash table. - Third Character: 'a'
'a' is already in the hash table (duplicate).
Increment Answer: 2 (start new substring).
Clear the hash table and add 'a' to the hash table (start new substring). - Fourth Character: 'c'
Not in the hash table.
Add 'c' to the hash table. - Fifth Character: 'a'
'a' is already in the hash table (duplicate).
Increment Answer: 3 (start new substring).
Clear the hash table and add 'a' to the hash table (start new substring). - Sixth Character: 'b'
Not in the hash table.
Add 'b' to the hash table. - Seventh Character: 'a'
'a' is already in the hash table (duplicate).
Increment Answer: 4 (start new substring).
Clear the hash table and add 'a' to the hash table (start new substring). - Final Answer:
After processing all characters, Answer = 4, meaning the minimum number of substrings is 4.
Substrings:
- First substring: "ab"
- Second substring: "ac"
- Third substring: "ab"
- Fourth substring: "a"
Thus, the minimum number of substrings is 4.
How to code it up?
- Initialize:
n: Length of the string s.
hashtable: A vector of size 26 to track character occurrences.
ans: Set to 1 (minimum number of substrings). - Iterate through each character c in the string s.
- Check if the character has already appeared in the current substring:
If hashtable[c - 'a'] > 0, increment ans and reset the hashtable. - Update the hash table by incrementing the count for the current character.
- Return ans after iterating through the string.
Code Implementation
1. C++ Try on Compiler
class Solution {
public:
int partitionString(string s) {
// Step 1: Get the length of the string
int n = s.length();
// Step 2: Initialize a hash table of size 26 to track character occurrences
vector<int> hashtable(26, 0);
// Step 3: Start with 1 partition (substring)
int ans = 1;
// Step 4: Iterate through each character in the string
for(auto &c: s)
{
// Step 5: Check if the character has appeared before in the current substring
if(hashtable[c-'a'] > 0)
{
// Step 6: If the character appears again, increment the number of partitions (new substring)
ans++;
// Step 7: Reset the hash table to start a new substring
for(int i = 0; i < 26; i++)
{
hashtable[i] = 0;
}
}
// Step 8: Mark the current character as seen by incrementing its corresponding entry in the hash table
hashtable[c-'a']++;
}
// Step 9: Return the total number of substrings
return ans;
}
};
2. Java Try on Compiler
class Solution {
public int partitionString(String s) {
// Step 1: Get the length of the string
int n = s.length();
// Step 2: Initialize a hash table of size 26 to track character occurrences
int[] hashtable = new int[26];
// Step 3: Start with 1 partition (substring)
int ans = 1;
// Step 4: Iterate through each character in the string
for (char c : s.toCharArray()) {
// Step 5: Check if the character has appeared before in the current substring
if (hashtable[c - 'a'] > 0) {
// Step 6: If the character appears again, increment the number of partitions (new substring)
ans++;
// Step 7: Reset the hash table to start a new substring
for (int i = 0; i < 26; i++) {
hashtable[i] = 0;
}
}
// Step 8: Mark the current character as seen by incrementing its corresponding entry in the hash table
hashtable[c - 'a']++;
}
// Step 9: Return the total number of substrings
return ans;
}
}
3. Python Try on Compiler
class Solution:
def partitionString(self, s):
# Step 1: Get the length of the string
n = len(s)
# Step 2: Initialize a hash table of size 26 to track character occurrences
hashtable = [0] * 26
# Step 3: Start with 1 partition (substring)
ans = 1
# Step 4: Iterate through each character in the string
for c in s:
# Step 5: Check if the character has appeared before in the current substring
if hashtable[ord(c) - ord('a')] > 0:
# Step 6: If the character appears again, increment the number of partitions (new substring)
ans += 1
# Step 7: Reset the hash table to start a new substring
for i in range(26):
hashtable[i] = 0
# Step 8: Mark the current character as seen by incrementing its corresponding entry in the hash table
hashtable[ord(c) - ord('a')] += 1
# Step 9: Return the total number of substrings
return ans
4. Javascript Try on Compiler
/**
* @param {string} s
* @return {number}
*/
var partitionString = function (s) {
// Step 1: Get the length of the string
let n = s.length;
// Step 2: Initialize a hash table of size 26 to track character occurrences
let hashtable = new Array(26).fill(0);
// Step 3: Start with 1 partition (substring)
let ans = 1;
// Step 4: Iterate through each character in the string
for (let c of s) {
// Step 5: Check if the character has appeared before in the current substring
if (hashtable[c.charCodeAt(0) - 'a'.charCodeAt(0)] > 0) {
// Step 6: If the character appears again, increment the number of partitions (new substring)
ans++;
// Step 7: Reset the hash table to start a new substring
for (let i = 0; i < 26; i++) {
hashtable[i] = 0;
}
}
// Step 8: Mark the current character as seen by incrementing its corresponding entry in the hash table
hashtable[c.charCodeAt(0) - 'a'.charCodeAt(0)]++;
}
// Step 9: Return the total number of substrings
return ans;
};
Time Complexity: O(n)
The main loop iterates over every character of the string s. This takes O(n) time, where n is the length of the string.
Inside the loop, we check if a character has already appeared in the current substring by accessing the hash table (hashtable[c - 'a'] > 0). This operation is O(1).
If the character is already seen, we reset the hash table, which involves resetting all 26 entries. This is O(26), but since 26 is a constant, this operation is effectively O(1).
We also increment the value in the hash table for each character, which is O(1).
Since the time spent per character is O(1), and we are iterating over n characters, the overall time complexity is: O(n).
Space Complexity: O(n)
Auxiliary Space: O(1)
Explanation: The hashtable is the only extra space used that grows with the input (though its size is constant at 26), so its space complexity is O(1).
The variables n, ans, and the loop variables require constant space, i.e., O(1).
Therefore, the auxiliary space complexity is O(1).
Total Space Complexity: O(n)
Explanation: The input string s requires O(n) space, where n is the length of the string. This is the space needed to store the string.
Bonus tip (using bitmask):
Using a bitmask in this problem allows us to efficiently track the presence of characters in the current substring without using a hash table or array.
A bitmask is an integer where each of its 26 least significant bits represents one of the lowercase English letters ('a' to 'z'). If a character is present in the substring, its corresponding bit in the bitmask is set to 1.
To check if a character has already appeared, we perform a bitwise AND operation between the bitmask and a bit representing the character. If the result is non-zero, the character is already present, and we partition the string, reset the bitmask, and start tracking a new substring. To add a character to the bitmask, we use a bitwise OR operation, which sets the corresponding bit.
This approach reduces memory usage by replacing a size-26 array with a single integer and improves performance by leveraging constant-time bitwise operations.
As we iterate through the string, we efficiently manage partitions based on whether a character's bit is set, ultimately counting the minimum number of substrings needed.
Learning Tip
Now we have successfully tackled this problem, let's try these similar problems.
Given a string s, find the length of the longest substring without repeating characters.
Given a string s and an integer k, return the length of the longest substring of s such that the frequency of each character in this substring is greater than or equal to k.
if no such substring exists, return 0.