Minimum Length of String After Deleting Similar Ends
Problem Description
Given a string s consisting only of characters 'a', 'b', and 'c'. You are asked to apply the following algorithm on the string any number of times:
- Pick a non-empty prefix from the string s where all the characters in the prefix are equal.
- Pick a non-empty suffix from the string s where all the characters in this suffix are equal.
- The prefix and the suffix should not intersect at any index.
- The characters from the prefix and suffix must be the same.
- Delete both the prefix and the suffix.
Return the minimum length of s after performing the above operation any number of times (possibly zero).
Examples
Input: s = "ca"
Output: 2
Explanation: You can't remove any characters, so the string stays as is.
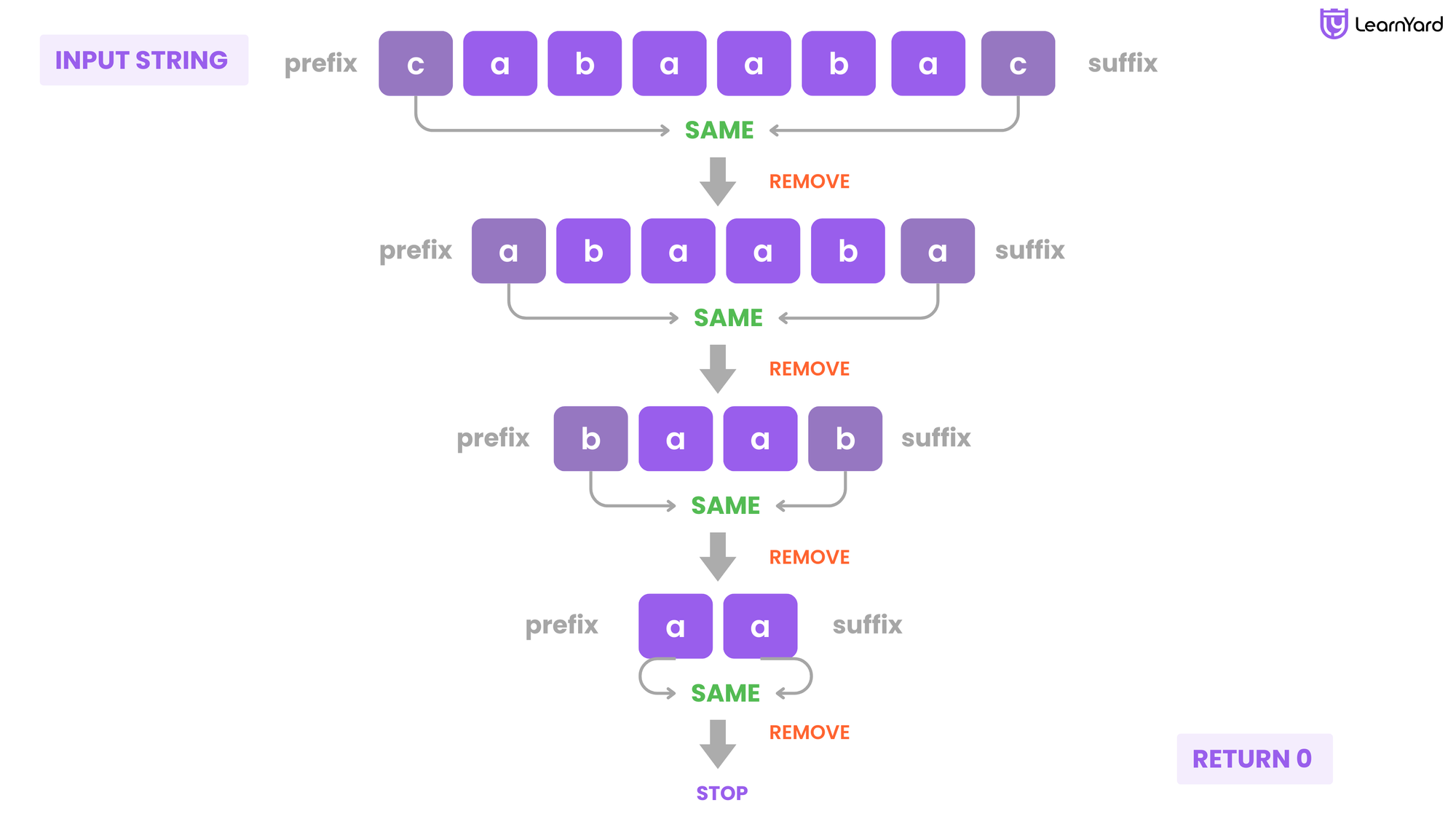
Input: s = "cabaabac"
Output: 0
Explanation: An optimal sequence of operations is:
- Take prefix = "c" and suffix = "c" and remove them, s = "abaaba".
- Take prefix = "a" and suffix = "a" and remove them, s = "baab".
- Take prefix = "b" and suffix = "b" and remove them, s = "aa".
- Take prefix = "a" and suffix = "a" and remove them, s = "".
Input: s = "aabccabba"
Output: 3
Explanation: An optimal sequence of operations is:
- Take prefix = "aa" and suffix = "a" and remove them, s = "bccabb".
- Take prefix = "b" and suffix = "bb" and remove them, s = "cca".
Constraints
- 1 <= s.length <= 10⁵
- s only consists of characters 'a', 'b', and 'c'.
Let’s try to formulate exactly what it says. This will help find our brute-force solution for this problem. Then we will see what all important things matter to us and remove those that don't contribute much to the answer. Finally, this will help us find our optimal solution.
Brute Force Approach
Intuition
We will do exactly what the problem asks us to do. It tells us to remove the prefix and suffix with all the characters equal. Also, all the characters of the prefix (which are the same) must be equal to all the characters of the suffix (which are also the same).
So, the removal of prefixes and suffixes is only possible when the first and last characters are the same, if they are not the same then we cannot do any operation in this case we simply return the string length.
Hence to do this we will start only when our string has its first and last character the same. Then we will run two iterations one from the start to achieve an index before which all the characters can be removed and another from the end to achieve an index after which every character can be removed ensuring that all the characters are equal in both prefix and suffix.
To update the string after each iteration we can keep a temporary string as a helper variable which will denote our reduced string. But to make things cleaner and easier to understand we will be using C++ inbuilt substr function which returns a substring of a string provided the starting index and length of the substring.
Once we have our updated starting and ending indexes then all the elements in the range [strIdx, endIdx] will make our reduced string. After we perform this operation, we will get our reduced string. Doing the same operation on this reduced string until we cannot do more will get us to our desired answer.
What is a substring?
A substring is a contiguous sequence of characters within a string. It is a subset of the original string and is formed by taking one or more adjacent characters from it. A substring must start at a position within the original string and end at a position within the original string as well.
Examples:
String: “abc”
Substrings: [“a”, “b”, “c”, “ab”, “bc”, “abc”]
What is the substr function in C++?
The substr function in C++ helps to find a substring of some base string given the starting index and length of the substring. If no second parameter (length) is provided, then it will give the whole string after the starting index (first parameter).
Examples:
String: s = “abcdef”
s.substr(1, 3) = “bcd”
s.substr(2, 2) = “cd”
s.substr(3) = “def”
Dry-run
Input: s = "bbaccbaab"
Output: 3
Explanation: An optimal sequence of operations is:
- Take prefix = "bb" and suffix = "b" and remove them, s = "accbaa".
- Take prefix = "a" and suffix = "aa" and remove them, s = "ccb".
First Iteration (s = “bbaccbaab”)
Step 1: Check if the length of s is 1.
- Length of s = 1
- The length is greater than 1, so we proceed.
Step 2: Check if the first and last characters are the same.
- s.front() = 'b', s.back() = 'b'.
- They are the same, so we proceed.
Step 3: Initialize variables.
- n = 9 (size of the string).
- strIdx = 0 (starting index).
- endIdx = 8 (ending index).
Step 4: Move strIdx to the first character different from s.front().
- Starting at strIdx = 0:
- s[0] = 'b' → Move strIdx to 1.
- s[1] = 'b' → Move strIdx to 2.
- s[2] = 'a' → Stop.
- Now, strIdx = 2.
Step 5: Move endIdx to the first character different from s.back()
- Starting at endIdx = 8:
- s[8] = 'b' → Move endIdx to 7.
- s[7] = 'a' → Stop.
- Now, endIdx = 7.
Step 6: Check the conditions.
- If endIdx == strIdx:
- endIdx (7) ≠ strIdx (2).
- Proceed.
- If endIdx < strIdx:
- endIdx (7) > strIdx (2).
- Proceed.
- Otherwise, reduce the string to the substring s[strIdx : endIdx+1].
- s = s[2:8] = "accbaa".
Second Iteration: ( s = “accbaa” )
Step 1: Check if the first and last characters are the same.
- s.front() = 'a', s.back() = 'a'.
- They are the same, so we proceed.
Step 2: Initialize variables.
- n = 6.
- strIdx = 0.
- endIdx = 5.
Step 3: Move strIdx to the first character different from s.front().
- Starting at strIdx = 0:
- s[0] = 'a' → Move strIdx to 1.
- s[1] = 'c' → Stop.
- Now, strIdx = 1.
Step 4: Move endIdx to the first character different from s.back().
- Starting at endIdx = 5:
- s[5] = 'a' → Move endIdx to 4.
- s[4] = 'a' → Move endIdx to 3.
- s[3] = 'b' → Stop.
- Now, endIdx = 3.
Step 5: Check the conditions.
- If endIdx == strIdx:
- endIdx (3) ≠ strIdx (1).
- Proceed.
- If endIdx < strIdx:
- endIdx (3) > strIdx (1).
- Proceed.
- Otherwise, reduce the string to the substring s[strIdx:endIdx+1].
- s = s[1:4] = "ccb".
Third Iteration: (s = “ccb”)
Step 1: Check if the first and last characters are the same.
- s[0] = 'c', s[n-1] = 'b'.
- They are not the same, so the string cannot be reduced further.
Step 2: Return the size of string s.
Steps to write code
Step 1: Check if length of string is 1:
- If the length of the string is 1 we simply return 1.
Step 2: We will only proceed if the first and last character of the string are the same.
Step 3: Initialize the variables:
- n for size of string,
- strIdx to track starting index which will point to the first character different from that of the start of the string.
- endIdx to track the ending index which will point to the first character from the end of the string different from that of the last character of the string.
Step 4: Iterate till strIdx points to the first character different from that of the start of the string.
Step 5: Iterate till endIdx points to the first character from the end of the string different from that of the last character of the string.
Step 6: Check necessary conditions:
- If endIdx and strIdx coincide then we simply return 1.
- If endIdx crosses strIdx meaning we can remove the whole string so return 0.
Step 7: Update the string s with substr function containing only characters in range [strIdx , endIdx].
Step 8: The length of the reduced string is our required answer.
Brute Force in All Languages
C++
class Solution {
public:
int minimumLength(string s) {
// base case to handle, if string size is 1 we return 1.
if(s.size() == 1) {
return 1;
}
// Check until rule no. 4 satisfies
while(s.front() == s.back()) {
// define variable size, starting index, ending index.
int n = s.size(), strIdx = 0, endIdx = n-1;
// increase starting index until we find a different character
while(strIdx < n and s[strIdx] == s[0]) {
strIdx++;
}
// decrease ending index until we find a different character
while(endIdx >=0 and s[endIdx] == s[n-1]) {
endIdx--;
}
// If ending index crosses starting index then we can delete the whole string
if(endIdx < strIdx) return 0;
// If the ending index stops exactly where the starting index stopped then we return 1.
if(endIdx == strIdx) return 1;
// Update s to contain only characters which lie from starting to ending index
s = s.substr(strIdx, endIdx-strIdx+1);
}
// Return the size of the final string.
return s.size();
}
};
Java
class Solution {
public int minimumLength(String s) {
// Base case to handle, if string size is 1 we return 1
if (s.length() == 1) {
return 1;
}
// Check until the first and last characters are the same
while (s.charAt(0) == s.charAt(s.length() - 1)) {
// Define variable size, starting index, ending index
int n = s.length();
int strIdx = 0, endIdx = n - 1;
// Increase starting index until we find a different character
while (strIdx < n && s.charAt(strIdx) == s.charAt(0)) {
strIdx++;
}
// Decrease ending index until we find a different character
while (endIdx >= 0 && s.charAt(endIdx) == s.charAt(n - 1)) {
endIdx--;
}
// If ending index crosses starting index, then we can delete the whole string
if (endIdx < strIdx) {
return 0;
}
// If ending index stops exactly where starting index stopped, then return 1
if (endIdx == strIdx) {
return 1;
}
// Update `s` to contain only characters which lie from starting to ending index
s = s.substring(strIdx, endIdx + 1);
}
// Return the size of the final string
return s.length();
}
}
Python
class Solution:
def minimumLength(self, s: str) -> int:
# Base case: if the string size is 1, return 1
if len(s) == 1:
return 1
# Check until the first and last characters are different
while s[0] == s[-1]:
# Define the size, starting index, and ending index
n = len(s)
strIdx, endIdx = 0, n - 1
# Increase starting index until we find a different character
while strIdx < n and s[strIdx] == s[0]:
strIdx += 1
# Decrease ending index until we find a different character
while endIdx >= 0 and s[endIdx] == s[-1]:
endIdx -= 1
# If ending index crosses starting index, the string can be deleted entirely
if endIdx < strIdx:
return 0
# If ending index stops exactly where starting index stopped, return 1
if endIdx == strIdx:
return 1
# Update the string to only contain the characters from start to end index
s = s[strIdx:endIdx + 1]
# Return the size of the final string
return len(s)Javascript
/**
* @param {string} s
* @return {number}
*/
var minimumLength = function(s) {
// Base case: if the string size is 1, return 1
if (s.length === 1) {
return 1;
}
// Check until the first and last characters are different
while (s[0] === s[s.length - 1]) {
// Define the size, starting index, and ending index
let n = s.length;
let strIdx = 0;
let endIdx = n - 1;
// Increase starting index until we find a different character
while (strIdx < n && s[strIdx] === s[0]) {
strIdx += 1;
}
// Decrease ending index until we find a different character
while (endIdx >= 0 && s[endIdx] === s[s.length - 1]) {
endIdx -= 1;
}
// If ending index crosses starting index, the string can be deleted entirely
if (endIdx < strIdx) {
return 0;
}
// If ending index stops exactly where starting index stopped, return 1
if (endIdx === strIdx) {
return 1;
}
// Update the string to only contain the characters from start to end index
s = s.slice(strIdx, endIdx + 1);
}
// Return the size of the final string
return s.length;
};Time Complexity: O(n)
Each character in the string is processed at most once in the strIdx and endIdx loops.
The substr operation creates substrings with decreasing lengths. The total cost of all substr calls can be analyzed as a geometric series:
- In the first iteration, the substring is of size n.
- In the second iteration, it's approximately n - k, where k is the number of characters removed from the boundaries.
- The total cost of creating substrings across all iterations is bounded by O(n).
Final Complexity:
- Outer while loop: Runs until the string is fully processed. The maximum number of iterations is proportional to n (or less, depending on the number of repeated characters).
- Inner operations (finding indices, substring creation): These are linear across all iterations.
Thus, the overall time complexity of the algorithm is O(n).
Space Complexity: O(n²)
Auxiliary Space Complexity: refers to the additional or extra space used by an algorithm, excluding the space required to store the input data.
Three integer variables are used to store the length of the string (n), the starting index (strIdx), and the ending index (endIdx).
- Each integer variable typically requires 4 bytes of memory (platform-dependent but often constant).
- Total space used for these variables: 4×3=12 bytes, which is O(1).
The algorithm repeatedly updates the string s using the substr method:
[s = s.substr(strIdx, endIdx - strIdx + 1);]
- This creates a new substring of length (endIdx - strIdx + 1).
- First iteration: Allocate memory for O(n).
- Second iteration: Allocate memory for O(n−k), where k is the trimmed portion.
- Over n iterations, this could lead to an accumulated memory usage of O(n²).
The length of this substring decreases with each iteration, but since the maximum length is at most n, the maximum auxiliary space used for the substring is O(n²).
Total auxiliary space complexity: O(n²)
Total Space Complexity: It includes both the auxiliary space, and the space required for the input
Input String:
- The input string s is provided as input to the function.
- For a string of length n, it occupies O(n) space in memory.
Auxiliary Space:
- As calculated above, the auxiliary space is O(n²).
So, the overall total space complexity is O(n²).
The brute force solution updates the string after each iteration. This is taking extra memory and hence this solution passes the time but not the space complexity. The extra space is due to the substr function which needs handling in order to pass all the test cases.
Optimal Approach
Intuition
The problem asks us to print the length of the final reduced string after removing valid prefixes and suffixes satisfying the required condition as mentioned in the problem description.
The brute force solution kept track of our string and did operations on it if feasible and updated the string accordingly, but you see the output is a single integer, not the string. So, the next question to be answered is how to find the length of the substring without explicitly storing the substring.
What things do we need to get the length of a substring of some string without explicitly storing the substring?
We only need the starting index inside the original string from where our substring starts and the ending index inside the original string marking where our substring ends. All the elements inside the range [starting index, ending index] mark our substring.
We are more interested in the length of the substring; it doesn't matter what the substring or our reduced string is! If we have our strIdx and endIdx then the length of the substring is given by endIdx-strIdx+1.
Why is the length of the substring of some string given the starting index (strIdx) and ending index (endIdx) is endIdx-strIdx+1?
endIdx - strIdx will include all the characters that are greater than strIdx and less than equal to endIdx. But we also need to include strIdx for that we need to add 1 to get the length of our desired substring.
So, what we will do is that once we are done with the operations on the original string we will get our updated strIdx and endIdx. we will simply return endIdx - strIdx +1 (length of the substring). This will save our efforts to find a substring after each operation and will pass all the test cases and get our solution accepted.
Let us understand with a video,
Dry-run
Input: s = "bbaccbaab"
Output: 3
Explanation: An optimal sequence of operations is:
- Take prefix = "bb" and suffix = "b" and remove them, s = "accbaa".
- Take prefix = "a" and suffix = "aa" and remove them, s = "ccb".
First Iteration (s=”bbaccbaab”)
Step 1: Check if the length of s is 1.
- Length of s = 9.
- The length is greater than 1, so we proceed.
Step 2: Check if the first and last characters are the same.
- s.front() = 'b', s.back() = 'b'.
- They are the same, so we proceed.
Step 3: Initialize variables.
- n = 9 (size of the string).
- strIdx = 0 (starting index).
- endIdx = 8 (ending index).
Step 4: Move strIdx to the first character different from s.front().
- Starting at strIdx = 0:
- s[0] = 'b' → Move strIdx to 1.
- s[1] = 'b' → Move strIdx to 2.
- s[2] = 'a' → Stop.
- Now, strIdx = 2.
Step 5: Move endIdx to the first character different from s.back().
- Starting at endIdx = 8:
- s[8] = 'b' → Move endIdx to 7.
- s[7] = 'a' → Stop.
- Now, endIdx = 7.
Step 6: Check the conditions.
- If endIdx == strIdx:
- endIdx (7) ≠ strIdx (2). Proceed.
- If endIdx < strIdx:
- endIdx (7) > strIdx (2). Proceed.
Second Iteration: (s = "accbaa")
Step 1: Check if the first and last characters are the same.
- s.front() = 'a', s.back() = 'a'.
- They are the same, so we proceed.
Step 2: Initialize variables.
- n = 6.
- strIdx = 0.
- endIdx = 5.
Step 3: Move strIdx to the first character different from s.front().
- Starting at strIdx = 0:
- s[0] = 'a' → Move strIdx to 1.
- s[1] = 'c' → Stop.
- Now, strIdx = 1.
Step 4: Move endIdx to the first character different from s.back().
- Starting at endIdx = 5:
- s[5] = 'a' → Move endIdx to 4.
- s[4] = 'a' → Move endIdx to 3.
- s[3] = 'b' → Stop.
- Now, endIdx = 3.
Step 5: Check the conditions.
- If endIdx == strIdx:
- endIdx (3) ≠ strIdx (1). Proceed.
- If endIdx < strIdx:
- endIdx (3) > strIdx (1). Proceed.
Third Iteration: (s = "ccb")
Step 1: Check if the length of s is 1.
- Length of s = 3.
- The length is greater than 1, so we proceed.
Step 2: Check if the first and last characters are the same.
- s.front() = 'c', s.back() = 'b'.
- They are not the same, so the string cannot be reduced further.
Step 3: Finally we return the substring length endIdx - strIdx +1
Steps to write code
Step1: Check if length of string is 1:
- If the length of the string is 1 we simply return 1.
Step2: We will only proceed if the first and last character of the string are the same.
Step3: Initialize the variables:
- n for size of string,
- strIdx to track starting index which will point to the first character different from that of the start of the string.
- endIdx to track the ending index which will point to the first character from the end of the string different from that of the last character of the string.
Step4: Iterate till strIdx points to the first character different from that of the start of the string.
Step5: Iterate till endIdx points to the first character from the end of the string different from that of the last character of the string.
Step6: Check necessary conditions:
- If endIdx and strIdx coincide then we simply return 1.
- If endIdx crosses strIdx meaning we can remove the whole string so return 0.
Step7: The length of the reduced string (endIdx - strIdx + 1) is our required answer.
Optimal Approach in All Languages
C++
class Solution {
public:
int minimumLength(string s) {
int n = s.size();
// Initialize our two pointers strIdx and endIdx.
int strIdx=0, endIdx=n-1;
// if strIdx already coincides with endIdx return 1.
if(strIdx==endIdx) {
return 1;
}
// We will process if s[strIdx] == s[endIdx] satisfies.
while(s[strIdx] == s[endIdx]) {
// Character of interest current is s[strIdx] or s[endIdx] both are same.
char curr = s[strIdx];
// We will loop until there is any other character other then curr.
while(strIdx < n and s[strIdx] == curr) {
strIdx++;
}
// Like wise for 'endIdx' too but in reverse direction.
while(endIdx >=0 and s[endIdx] == curr) {
endIdx--;
}
// We handle the case when strIdx and endIdx coincides after looping we return 1.
if(strIdx == endIdx) return 1;
// We handle case then endIdx crosses strIdx after looping we return 0.
if(endIdx < strIdx) return 0;
}
// Final length to return.
return endIdx-strIdx+1;
}
};Java
class Solution {
public int minimumLength(String s) {
int n = s.length();
// Initialize our two pointers strIdx and endIdx.
int strIdx = 0, endIdx = n - 1;
// If strIdx already coincides with endIdx, return 1.
if (strIdx == endIdx) {
return 1;
}
// We will process if s.charAt(strIdx) == s.charAt(endIdx) satisfies.
while (s.charAt(strIdx) == s.charAt(endIdx)) {
// Character of interest current is s.charAt(strIdx) or s.charAt(endIdx), both are same.
char curr = s.charAt(strIdx);
// We will loop until there is any other character other than curr.
while (strIdx < n && s.charAt(strIdx) == curr) {
strIdx++;
}
// Likewise for 'endIdx' too but in the reverse direction.
while (endIdx >= 0 && s.charAt(endIdx) == curr) {
endIdx--;
}
// Handle the case when strIdx and endIdx coincide after looping.
if (strIdx == endIdx) return 1;
// Handle the case when endIdx crosses strIdx after looping.
if (endIdx < strIdx) return 0;
}
// Final length to return.
return endIdx - strIdx + 1;
}
}Python
class Solution:
def minimumLength(self, s: str) -> int:
n = len(s)
# Initialize our two pointers strIdx and endIdx.
strIdx, endIdx = 0, n - 1
# If strIdx already coincides with endIdx, return 1.
if strIdx == endIdx:
return 1
# Process while s[strIdx] == s[endIdx] satisfies.
while s[strIdx] == s[endIdx]:
# Character of interest current is s[strIdx] or s[endIdx], both are same.
curr = s[strIdx]
# Loop until there is any other character other than curr.
while strIdx < n and s[strIdx] == curr:
strIdx += 1
# Likewise for 'endIdx' too but in the reverse direction.
while endIdx >= 0 and s[endIdx] == curr:
endIdx -= 1
# Handle the case when strIdx and endIdx coincide after looping.
if strIdx == endIdx:
return 1
# Handle the case when endIdx crosses strIdx after looping.
if endIdx < strIdx:
return 0
# Final length to return.
return endIdx - strIdx + 1Javascript
/**
* @param {string} s
* @return {number}
*/
var minimumLength = function(s) {
let n = s.length;
// Initialize our two pointers strIdx and endIdx.
let strIdx = 0, endIdx = n - 1;
// If strIdx already coincides with endIdx, return 1.
if (strIdx === endIdx) {
return 1;
}
// Process while s[strIdx] === s[endIdx] satisfies.
while (s[strIdx] === s[endIdx]) {
// Character of interest current is s[strIdx] or s[endIdx], both are same.
let curr = s[strIdx];
// Loop until there is any other character other than curr.
while (strIdx < n && s[strIdx] === curr) {
strIdx++;
}
// Likewise for 'endIdx' too but in the reverse direction.
while (endIdx >= 0 && s[endIdx] === curr) {
endIdx--;
}
// Handle the case when strIdx and endIdx coincide after looping.
if (strIdx === endIdx) {
return 1;
}
// Handle the case when endIdx crosses strIdx after looping.
if (endIdx < strIdx) {
return 0;
}
}
// Final length to return.
return endIdx - strIdx + 1;
};Time Complexity : O(n)
Both loops process each character of the string at most once across all iterations of the main loop because:
- Each character is processed either as part of strIdx++ or endIdx--.
- Once a character is processed, it is skipped in further iterations.
The dominant factor is the total number of iterations across the inner while loops, which process each character exactly once. Therefore, the time complexity is O(n), where n is the length of the input string.
The total time complexity is O(n).
Space Complexity : O(n)
Auxiliary Space Complexity : refers to the additional or extra space used by an algorithm, excluding the space required to store the input data.
- The algorithm uses only a fixed number of variables (strIdx, endIdx, and curr) and does not require any additional data structures.
- Integer variables take 4 bytes in most systems and characters take 1 byte. Taking constant space.
So, the overall auxiliary space complexity is O(1).
Total Space Complexity: this will include both the memory for the input and the auxiliary space used by the algorithm.
- Input Space: O(n) (for storing the string s).
- Auxiliary Space: O(1) (for the variables used in the algorithm)
So, the overall total space complexity is O(n) + O(1) = O(n).
Learning Tip
Now we have successfully tackled our problem. Let’s try these similar problems:
Given an array of characters chars, compress it using the following algorithm:
Begin with an empty string s. For each group of consecutive repeating characters in chars:
- If the group's length is 1, append the character to s.
- Otherwise, append the character followed by the group's length.
The compressed string s should not be returned separately, but instead, be stored in the input character array chars. Note that group lengths that are 10 or longer will be split into multiple characters in chars.
After you are done modifying the input array, return the new length of the array.
You must write an algorithm that uses only constant extra space.
You are given an integer array height of length n. There are n vertical lines drawn such that the two endpoints of the iᵗʰ line are (i, 0) and (i, height[i]).
Find two lines that together with the x-axis form a container, such that the container contains the most water.
Return the maximum amount of water a container can store.
Notice that you may not slant the container.