Custom Sort String Solution In C++/Java/Python/Javascript
Problem Description:
You are given two strings order and s. All the characters of order are unique and were sorted in some custom order previously.
Permute the characters of s so that they match the order that order was sorted. More specifically, if a character x occurs before a character y in order, then x should occur before y in the permuted string.
Return any permutation of s that satisfies this property.
Examples:
Input: order = "cba", s = "abcd"
Output: "cbad"
Explanation: "a", "b", "c" appear in order, so the order of "a", "b", "c" should be "c", "b", and "a".
Since "d" does not appear in order, it can be at any position in the returned string. "dcba", "cdba", "cbda" are also valid outputs.
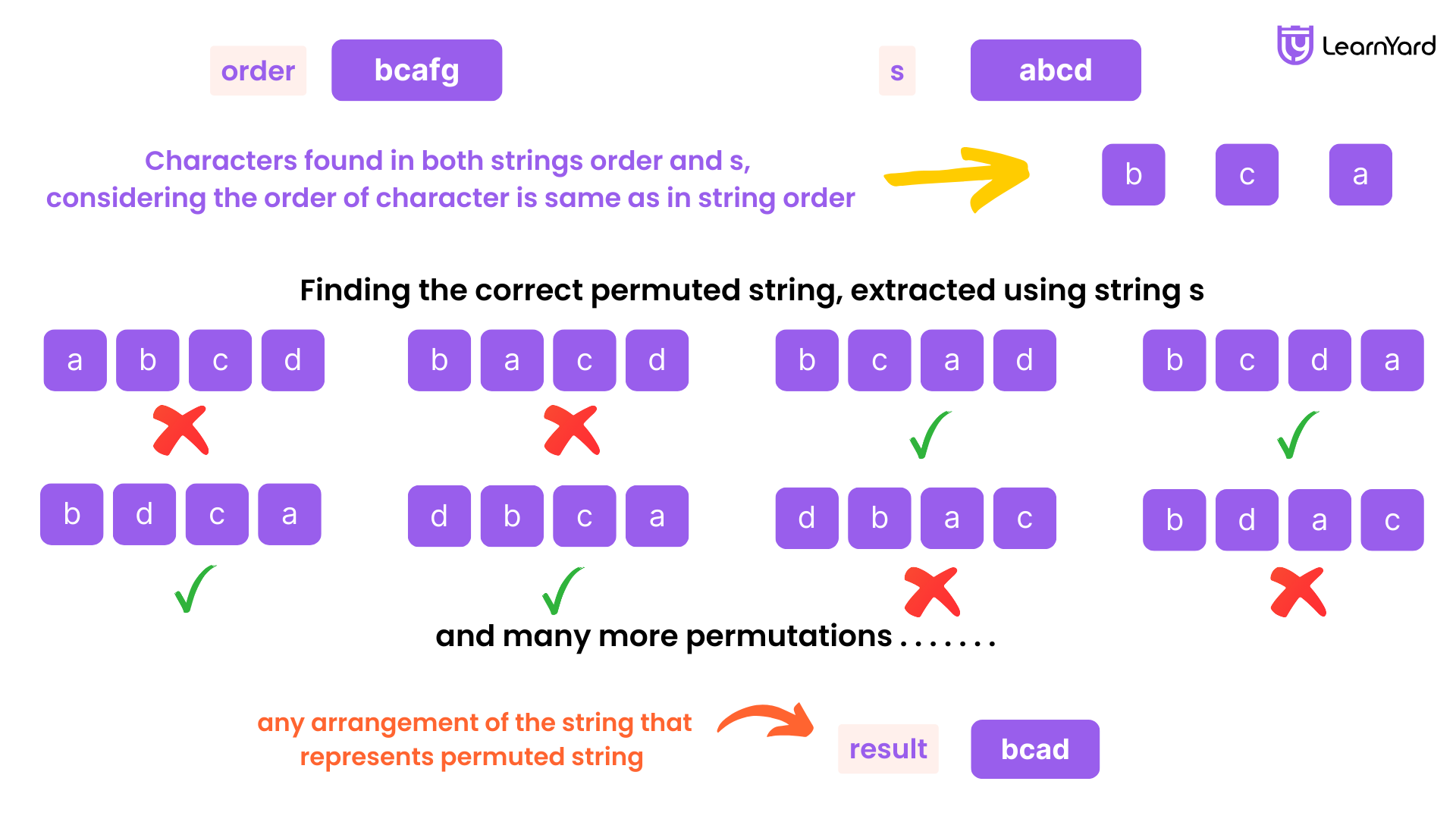
Input: order = "bcafg", s = "abcd"
Output: "bcad"
Explanation: The characters "b", "c", and "a" from order dictate the order for the characters in s. The character "d" in s does not appear in order, so its position is flexible.
Following the order of appearance in order, "b", "c", and "a" from s should be arranged as "b", "c", "a". "d" can be placed at any position since it's not in order. The output "bcad" correctly follows this rule. Other arrangements like "dbca" or "bcda" would also be valid, as long as "b", "c", "a" maintain their order.
Constraints:
- 1 <= order.length <= 26
- 1 <= s.length <= 200
- order and s consist of lowercase English letters.
- All the characters of order are unique.
Brute Force Approach
Okay, so here's the thought process:
What comes to mind after reading the problem statement?
We need to arrange the characters of string s according to the order given in string order.
So we can start by recognizing that the characters that appear earlier in order have higher precedence to come first in string s. So, we can simply traverse through order and for each character, check if it is present in s. If the character is found, we place it in the result as many times as it appears in s. Then, we continue processing the next characters in order. If any character from order is not present in s, we skip it.
Finally, after processing all characters from order, we append the remaining characters from s that were not included in order. This way, we ensure that the characters of s follow the custom order while placing the characters not found in order at the end.
How can we do it?
Now we understand what we need to do, so let's focus on how to do it.
To solve the problem, we start by traversing the string order.
For each character in order, we search for it in string s by traversing through s. If the character is found in s, we add it to the result string (let's call it result).
After processing all the characters in order, we then append any characters from s that were not part of order to the result string.
Finally, we return the result string, which will have the characters of s arranged according to the custom order specified in order, followed by any remaining characters from s that were not in order.
Let's understand with an example:
Dry Run of Brute Force for : order = "cba", s = "abcd"
Steps:
- Start traversing through order:
First character in order is 'c'.
Search for 'c' in s: Found at position 2.
Add 'c' to result: result = "c".
s becomes "abd" (after removing 'c').
Second character in order is 'b'.
Search for 'b' in s: Found at position 1.
Add 'b' to result: result = "cb".
s becomes "ad" (after removing 'b').
Third character in order is 'a'.
Search for 'a' in s: Found at position 0.
Add 'a' to result: result = "cba".
s becomes "d" (after removing 'a'). - Add remaining characters in s:
The only remaining character in s is 'd'.
Add 'd' to result: result = "cbad".
Output: result = "cbad"
How to code it up:
Here are the concise steps to code the solution:
- Initialize an empty string result to store the final output.
- Loop through each character in order to process the characters in the specified order.
- For each character in order, search for it in s, add it to result as many times as it appears, and mark it as processed by replacing it with a placeholder (e.g., '#').
- After processing order, loop through s again to find any characters not processed, and append them to result in their original order.
- Return the result string, which now contains the characters of s sorted according to order with the remaining characters appended at the end.
Code Implementation
1. C++ Try on Compiler
class Solution {
public:
string customSortString(string order, string s) {
// Initialize the resultant string to store the sorted result
string result = "";
// Step 1: Process each character in `order`
for (char c : order) {
// Step 1.1: Loop through the string `s` to find the character `c`
for (int i = 0; i < s.size(); ++i) {
// Step 1.2: If the character `c` is found in `s`
if (s[i] == c) {
// Step 1.3: Add the character `c` to the result string
result += c;
// Step 1.4: Mark the character in `s` as processed by replacing it with a placeholder
s[i] = '#';
}
}
}
// Step 2: Append any remaining characters in `s` that were not processed (not in `order`)
for (char c : s) {
// Step 2.1: If the character was not marked as processed
if (c != '#') {
// Step 2.2: Add the unprocessed character to the result string
result += c;
}
}
// Step 3: Return the final result string
return result;
}
};
2. Java Try on Compiler
class Solution {
public String customSortString(String order, String s) {
// Initialize the resultant string to store the sorted result
StringBuilder result = new StringBuilder();
// Step 1: Process each character in `order`
for (char c : order.toCharArray()) {
// Step 1.1: Loop through the string `s` to find the character `c`
for (int i = 0; i < s.length(); ++i) {
// Step 1.2: If the character `c` is found in `s`
if (s.charAt(i) == c) {
// Step 1.3: Add the character `c` to the result string
result.append(c);
// Step 1.4: Mark the character in `s` as processed by replacing it with a placeholder
s = s.substring(0, i) + "#" + s.substring(i + 1);
}
}
}
// Step 2: Append any remaining characters in `s` that were not processed (not in `order`)
for (int i = 0; i < s.length(); ++i) {
if (s.charAt(i) != '#') {
// Add the unprocessed character to the result string
result.append(s.charAt(i));
}
}
// Step 3: Return the final result string
return result.toString();
}
}
3. Python Try on Compiler
class Solution:
def customSortString(self, order, s):
# Initialize the resultant string to store the sorted result
result = ""
# Step 1: Process each character in `order`
for c in order:
# Step 1.1: Loop through the string `s` to find the character `c`
for i in range(len(s)):
# Step 1.2: If the character `c` is found in `s`
if s[i] == c:
# Step 1.3: Add the character `c` to the result string
result += c
# Step 1.4: Mark the character in `s` as processed by replacing it with a placeholder
s = s[:i] + "#" + s[i+1:]
# Step 2: Append any remaining characters in `s` that were not processed (not in `order`)
for c in s:
if c != '#':
# Add the unprocessed character to the result string
result += c
# Step 3: Return the final result string
return result
4. Javascript Try on Compiler
/**
* @param {string} order
* @param {string} s
* @return {string}
*/
var customSortString = function (order, s) {
// Initialize the resultant string to store the sorted result
let result = "";
// Step 1: Process each character in `order`
for (let c of order) {
// Step 1.1: Loop through the string `s` to find the character `c`
for (let i = 0; i < s.length; i++) {
// Step 1.2: If the character `c` is found in `s`
if (s[i] === c) {
// Step 1.3: Add the character `c` to the result string
result += c;
// Step 1.4: Mark the character in `s` as processed by replacing it with a placeholder
s = s.substring(0, i) + "#" + s.substring(i + 1);
}
}
}
// Step 2: Append any remaining characters in `s` that were not processed (not in `order`)
for (let c of s) {
if (c !== '#') {
// Add the unprocessed character to the result string
result += c;
}
}
// Step 3: Return the final result string
return result;
};Time Complexity: O(n*m)
The outer loop iterates through each character in order, which has a length of n (where n is the length of the order string). Time Complexity: O(n).
For each character in order, the inner loop iterates through s, which has a length of m (where m is the length of the string s).The inner loop checks each character of s to see if it matches the current character from order. Time Complexity: O(m)
Since the outer loop runs n times, and for each iteration of the outer loop the inner loop runs m times, the total time complexity for this part is O(n * m).
After processing the characters from order, we loop through s again to append any remaining unprocessed characters to result. This requires iterating over s once, which takes O(m) time.
Thus, the overall time complexity is O(n * m).
Space Complexity: O(n+m)
Auxiliary Space Complexity: O(m)
Explanation: The only significant additional space used is for storing the result string, which takes O(m) space. The length of the result string can go up to m, where m is the length of the string s.
Total Space Complexity: O(n + m)
Explanation: We are given two input strings, order and s, of lengths n and m respectively. The total space used will be the space for these input strings plus the space for the result string, which has a maximum length of m.
Therefore, the total space used by the algorithm is O(n + m).
Will Brute Force Work Against the Given Constraints?
For the current solution, the time complexity is O(n * m), where n is the length of the order string and m is the length of the s string. Given the constraints of 1 ≤ order.length ≤ 26 and 1 ≤ s.length ≤ 200, the solution is expected to execute within the given time limits.
Since O(n * m) results in a maximum of 26 * 200 = 5200 operations (for n = 26 and m = 200), the solution is efficient enough to handle these inputs comfortably within typical time limits, typically executing within 1–2 seconds per test case.
In most competitive programming environments, problems can handle up to 10⁶ operations per test case. Given that the maximum number of operations here is 5200, the solution works very efficiently, well within these limits. Even with multiple test cases, the total number of operations remains manageable.
Thus, with O(n * m) operations per test case, the solution efficiently handles up to 10⁶ operations, comfortably fitting within the typical competitive programming constraints.
Can we optimize it?
In the previous approach, we traversed the entire string order, and for each character in order, we checked if it was present in s. If it was, we added it to our result. This approach worked fine but took O(n * m) time, where n is the length of order and m is the length of s.
So, can this be optimized?
The answer is yes.
In the previous approach, we were checking for each character in order whether it is present in s or not, which takes O(m) time since s has m characters. So, collectively, this takes O(n * m) time for traversing both order and s.
But instead of checking the entire string s for each character in order, can we check at once if the character is present or not?
The answer is yes! We can use a hashtable.
What is a hash table?
A hashtable is a data structure that stores key-value pairs, using a hash function to compute an index for quick access. It offers average O(1) time complexity for operations like insertion, deletion, and lookup.
We can store the frequency of every character in s in a hashtable, and then, as we traverse through order, we simply check if a character from order is present in the hashtable. If it is, we can quickly add that character to the result based on its frequency stored in the hashtable.
At the end, we will add all the characters from s that are not present in the hashtable, meaning the characters that weren't part of order.
This approach makes the solution more efficient by reducing the time complexity to O(n + m), where:
- O(m) is the time needed to build the frequency map from s,
- O(n) is the time needed to traverse order and construct the final result.
By using a hashtable, we avoid the need to traverse s multiple times, resulting in a much faster solution.
Let's understand with an example:
Dry Run of the Approach on Input:
Input: order = "bcafg", s = "abcd"
Step 1: Build Frequency Map for s
- Create a frequency map for s:
- Frequency Map: { 'a': 1, 'b': 1, 'c': 1, 'd': 1 }
Step 2: Traverse order and Add Characters to Result
- First character in order: 'b'
- Check if 'b' is in the frequency map. Yes, it is.
- Add 'b' to the result and update frequency map: { 'b': 0, 'a': 1, 'c': 1, 'd': 1 }.
- Next character in order: 'c'
- Check if 'c' is in the frequency map. Yes, it is.
- Add 'c' to the result and update frequency map: { 'b': 0, 'a': 1, 'c': 0, 'd': 1 }.
- Next character in order: 'a'
- Check if 'a' is in the frequency map. Yes, it is.
- Add 'a' to the result and update frequency map: { 'b': 0, 'a': 0, 'c': 0, 'd': 1 }.
- Next character in order: 'f'
- 'f' is not in the frequency map, so skip it.
- Next character in order: 'g'
- 'g' is not in the frequency map, so skip it.
Step 3: Add Remaining Characters from s
- After processing all characters in order, add characters that still have non-zero counts in the frequency map.
- Add 'd' to the result (since 'd' has a count of 1 in the frequency map).
- Final Result: "bcad"
Output: "bcad"
How to code it up?
Here are the concise steps to code the solution:
- Initialize the result string:
Create an empty string ans to store the final result. - Create a frequency map using a vector:
Initialize a hashtable (a vector of size 26, all initialized to 0). Traverse the string s, and for each character c, increment the corresponding position in hashtable[c - 'a'] to record its frequency. - Process characters in order:
For each character o in order, check if its frequency in hashtable is greater than 0. If yes, append o to ans as many times as its frequency, then set hashtable[o - 'a'] to 0 to mark it as processed. - Append remaining characters from s:
After processing order, loop through the hashtable for any remaining characters (those with frequency > 0). Append these characters to ans based on their frequency. - Return the final result string:
Return ans as the final sorted string.
Code Implementation
1. C++ Try on Compiler
class Solution {
public:
string customSortString(string order, string s) {
// Initialize the result string to store the final sorted string
string ans = "";
// Create a frequency map (hashtable) to store the count of each character in string s
vector<int> hashtable(26, 0);
// Traverse through string s to populate the frequency map
for(auto &c: s) {
// Increment the count of the character c in the hashtable
hashtable[c - 'a']++;
}
// Traverse through the string order to process characters in the specified order
for(auto &o: order) {
// If the character o exists in string s (frequency > 0)
if(hashtable[o - 'a'] > 0) {
// Append the character o to the result string as many times as it appears in s
ans += string(hashtable[o - 'a'], o);
// Set the frequency of the character o to 0 to mark it as processed
hashtable[o - 'a'] = 0;
}
}
// Append any remaining characters from string s that are not in order
for(int i = 0; i < 26; i++) {
// If the character i ('a' + i) appears in string s (frequency > 0)
if(hashtable[i] > 0) {
// Append the remaining characters to the result string
ans += string(hashtable[i], 'a' + i);
}
}
// Return the final result string
return ans;
}
};
2. Java Try on Compiler
class Solution {
public String customSortString(String order, String s) {
// Initialize the result string to store the final sorted string
StringBuilder ans = new StringBuilder();
// Create a frequency map (hashtable) to store the count of each character in string s
int[] hashtable = new int[26];
// Traverse through string s to populate the frequency map
for (char c : s.toCharArray()) {
// Increment the count of the character c in the hashtable
hashtable[c - 'a']++;
}
// Traverse through the string order to process characters in the specified order
for (char o : order.toCharArray()) {
// If the character o exists in string s (frequency > 0)
if (hashtable[o - 'a'] > 0) {
// Append the character o to the result string as many times as it appears in s
for (int i = 0; i < hashtable[o - 'a']; i++) {
ans.append(o);
}
// Set the frequency of the character o to 0 to mark it as processed
hashtable[o - 'a'] = 0;
}
}
// Append any remaining characters from string s that are not in order
for (int i = 0; i < 26; i++) {
// If the character i ('a' + i) appears in string s (frequency > 0)
if (hashtable[i] > 0) {
// Append the remaining characters to the result string
for (int j = 0; j < hashtable[i]; j++) {
ans.append((char) ('a' + i));
}
}
}
// Return the final result string
return ans.toString();
}
}
3. Python Try on Compiler
class Solution:
def customSortString(self, order, s):
# Initialize the result string to store the final sorted string
ans = ""
# Create a frequency map (hashtable) to store the count of each character in string s
hashtable = [0] * 26
# Traverse through string s to populate the frequency map
for c in s:
# Increment the count of the character c in the hashtable
hashtable[ord(c) - ord('a')] += 1
# Traverse through the string order to process characters in the specified order
for o in order:
# If the character o exists in string s (frequency > 0)
if hashtable[ord(o) - ord('a')] > 0:
# Append the character o to the result string as many times as it appears in s
ans += o * hashtable[ord(o) - ord('a')]
# Set the frequency of the character o to 0 to mark it as processed
hashtable[ord(o) - ord('a')] = 0
# Append any remaining characters from string s that are not in order
for i in range(26):
# If the character i ('a' + i) appears in string s (frequency > 0)
if hashtable[i] > 0:
# Append the remaining characters to the result string
ans += chr(i + ord('a')) * hashtable[i]
# Return the final result string
return ans
4. Javascript Try on Compiler
/**
* @param {string} order
* @param {string} s
* @return {string}
*/
var customSortString = function(order, s) {
// Initialize the result string to store the final sorted string
let ans = "";
// Create a frequency map (hashtable) to store the count of each character in string s
let hashtable = new Array(26).fill(0);
// Traverse through string s to populate the frequency map
for (let c of s) {
// Increment the count of the character c in the hashtable
hashtable[c.charCodeAt(0) - 'a'.charCodeAt(0)]++;
}
// Traverse through the string order to process characters in the specified order
for (let o of order) {
// If the character o exists in string s (frequency > 0)
if (hashtable[o.charCodeAt(0) - 'a'.charCodeAt(0)] > 0) {
// Append the character o to the result string as many times as it appears in s
ans += o.repeat(hashtable[o.charCodeAt(0) - 'a'.charCodeAt(0)]);
// Set the frequency of the character o to 0 to mark it as processed
hashtable[o.charCodeAt(0) - 'a'.charCodeAt(0)] = 0;
}
}
// Append any remaining characters from string s that are not in order
for (let i = 0; i < 26; i++) {
// If the character i ('a' + i) appears in string s (frequency > 0)
if (hashtable[i] > 0) {
// Append the remaining characters to the result string
ans += String.fromCharCode('a'.charCodeAt(0) + i).repeat(hashtable[i]);
}
}
// Return the final result string
return ans;
};Time Complexity: O(n + m)
The time complexity of the approach is as follows:
We traverse each character of string s once to build the frequency map (hashtable). The length of s is n, so this step takes O(n) time.
We iterate through each character of order. The length of order is m, so this step takes O(m) time. For each character in order, we perform a constant-time lookup and update operation on the frequency map, which is O(1) per character in order.
We traverse all 26 letters of the alphabet and check if there are any remaining characters in the frequency map. This step always takes constant time because there are at most 26 characters to check, so it is O(1).
The total time complexity is the sum of all these steps:
O(n) for processing string s.
O(m) for processing string order.
O(1) for appending remaining characters.
Thus, the overall time complexity is: O(n + m)
Space Complexity: O(n + m)
Auxiliary Space Complexity: O(m)
Explanation: We use a vector of size 26 to store the frequency of each character in s. This vector only stores the counts for lowercase English letters, so its size is constant. Therefore, the auxiliary space for the hashtable is O(1).
The result string ans stores the sorted characters. The maximum length of this string can be m, where m is the length of string s. The space required for the result string is O(m).
The total auxiliary space is the space used by the hashtable and the result string, so it is O(m).
Total Space Complexity: O(n + m)
Explanation: The input strings order and s are given, so they contribute O(n) and O(m) space, respectively, where n is the length of order and m is the length of s.
The total space complexity is the sum of the input space and auxiliary space, which gives O(n + m).
Wait we have one more approach!
Okay, hold on! We’ve got one more approach.
Since we’re required to sort the string, is there another way we can do that?
Have you heard about custom comparators?
In sorting, a comparator is a tool used to define (or redefine) the order between two items of the same class or data type. Most programming languages allow the use of a custom comparator, which means we can define a rule that determines how an array (or string) is sorted and then leverage built-in sort functions with this custom rule.
So, can we use custom comparators here?
Absolutely! But how?
To sort the string s based on the custom order defined by order, we first need to find out where each character in s appears in order. This is important because order tells us the priority or position of each character. For example, if order is "bcafg", then b comes first, c second, a third, and so on. So, for each character in s, we will check its position in order. The characters in s that appear earlier in order will be placed earlier in the sorted string, while the ones that appear later in order will be placed later. If a character in s is not found in order, it will be treated as having the lowest priority and will be placed at the end of the sorted string or at the beginning. This way, the order of characters in s follows the custom sequence defined by order.
We can do this by using a comparator. A comparator is a tool that tells us how to compare two items to determine which should come first. In our case, it compares two characters at a time from s and decides which one should appear first based on their positions in order.
For example, imagine we have order = "bcafg" and s = "abcd". If the comparator compares the characters a and b, it looks at their positions in order. Since a appears at index 1 in order and b appears at index 0, the comparator will decide that b should come before a. So, b will appear earlier in the sorted string.
A comparator compares two characters at a time, checks their index in order, and returns the one with the lower index. This means that the comparator will give priority to the character that appears earlier in order, so the sorted string will contain the element that appears earlier in order first.
But what if a character in s doesn't exist in order, we can give it a large value or a small value like -1 (large value as equal to the length of string s, since no index will be greater than this or -1 since no index will be smaller than this). This way, any character not found in order will automatically be placed at the end of the sorted string or the start of the sorted string so that all elements are placed order-wise in the sorted string.
In programming languages like C++ and Python, the find() function returns the position of the element passed to it. If the element is not found, it returns npos (in C++) or -1 (in Python), which represents the end of the string and starting of the string respectively. npos is equivalent to n (the length of the string). A similar functionality is provided by indexOf in Java and JavaScript.
So, using this approach, we can ensure that all the characters from s appear in the exact order defined by order, and any characters from s that are not in order will appear either after all the others or before all the others.
Let's understand with an example:
Let's dry run our approach in,
Input: order = "bcafg", s = "abcd"
Step-by-Step Execution:
- Characters in s: ['a', 'b', 'c', 'd']
- Custom Comparator (using order.find(c)):
- 'b' → index 0 in order
- 'c' → index 1 in order
- 'a' → index 2 in order
- 'd' → not found in order, so assigned a large value (Infinity).
Sorting Based on Index in order:
- Sort by indices: b (0), c (1), a (2), d (Infinity).
Final Sorted String:
- Result: "bca" (from order) + "d" (remaining character not in order).
- Output: "bcad"
How to code it up?
Here are the concise steps to code the solution:
- Define a Custom Comparator:
Create a comparator function (or lambda) to compare two characters:
If both characters are in order: Compare their indices in order.
If a character is not in order: Assign it a large index to place it at the end or -1 to place it at the beginning. - Sort the String s:
Use the built-in sorting function of your programming language.
Pass the custom comparator to sort s based on the order defined in order. - Return the Sorted String:
Convert the sorted result to a string (if necessary) and return it as the final output.
Code Implementation
1. C++ Try on Compiler
class Solution {
public:
string customSortString(string order, string s) {
// Define the custom comparator as lambda
// here find() will return the first index of char c in order
sort(s.begin(), s.end(), [order](char c1, char c2) {
return order.find(c1) < order.find(c2);
});
return s;
}
};2. Java Try on Compiler
import java.util.*;
class Solution {
public String customSortString(String order, String s) {
// Convert the string to a character array for sorting
Character[] charArray = new Character[s.length()];
for (int i = 0; i < s.length(); i++) {
charArray[i] = s.charAt(i);
}
// Sort the character array using a custom comparator
Arrays.sort(charArray, (c1, c2) -> {
return order.indexOf(c1) - order.indexOf(c2);
});
// Convert the sorted character array back to a string
StringBuilder result = new StringBuilder();
for (char c : charArray) {
result.append(c);
}
return result.toString();
}
}
3. Python Try on Compiler
class Solution:
def customSortString(self, order: str, s: str) -> str:
# Use sorted with a custom key
sorted_s = sorted(s, key=lambda c: order.find(c))
return ''.join(sorted_s)
4. Javascript Try on Compiler
var customSortString = function(order, s) {
// Convert the string to an array for sorting
let sortedS = Array.from(s).sort((c1, c2) => {
return order.indexOf(c1) - order.indexOf(c2);
});
// Convert the sorted array back to a string
return sortedS.join('');
};
Time Complexity: O(n logn)
Sorting the String s:
The string s is sorted using a custom comparator.
Sorting typically takes O(n log n) time, where n is the length of the string s.
Custom Comparator Logic:
For each comparison between two characters in s, the comparator checks their index in order using the find() method (or equivalent).
The find() method takes O(m) time in the worst case, where m is the length of the string order.
Since m can be at most 26 (as the string order contains only lowercase English letters), m is a constant. Therefore, the find() operation takes O(1) time in practice, making the custom comparator logic contribute O(n log n) time.
Total Time Complexity:
The overall time complexity is O(n log n), where:
n = Length of string s.
Thus, the time complexity is effectively O(n log n).
Space Complexity: O(n)
Auxiliary Space Complexity: O(1)
Explanation: The custom comparator does not require any extra significant space other than what is already used for the string s.
The sorting operation is done in-place on the string s, meaning no additional storage is used for a new array or string.
Therefore, the auxiliary space used is O(1) (excluding the space for the input and output strings).
Total Space Complexity: O(n)
Explanation: The space required to store the input string s and the string order is O(n), where n is the length of string s.
Therefore, the total space complexity is O(n), where n is the length of string s.
Learning Tip
Now we have successfully tackled this problem, let's try these similar problems.
Given a list of non-negative integers nums, arrange them such that they form the largest number and return it.Since the result may be very large, so you need to return a string instead of an integer.
You are given a 0-indexed integer array mapping which represents the mapping rule of a shuffled decimal system. mapping[i] = j means digit i should be mapped to digit j in this system.
The mapped value of an integer is the new integer obtained by replacing each occurrence of digit i in the integer with mapping[i] for all 0 <= i <= 9.
You are also given another integer array nums.
Return the array nums sorted in non-decreasing order based on the mapped values of its elements.
Notes:
1. Elements with the same mapped values should appear in the same relative order as in the input.
2. The elements of nums should only be sorted based on their mapped values and not be replaced by them.