Find Words That Can Be Formed by Characters Solution In C++/Java/Python/Javascript
Problem Description
We are given a list of words and a string of characters chars.
A word is considered good if all its characters can be made using the characters in the given string, and each character in the string can only be used once.
Your task is to find the total length of all the good words in the list and return it.
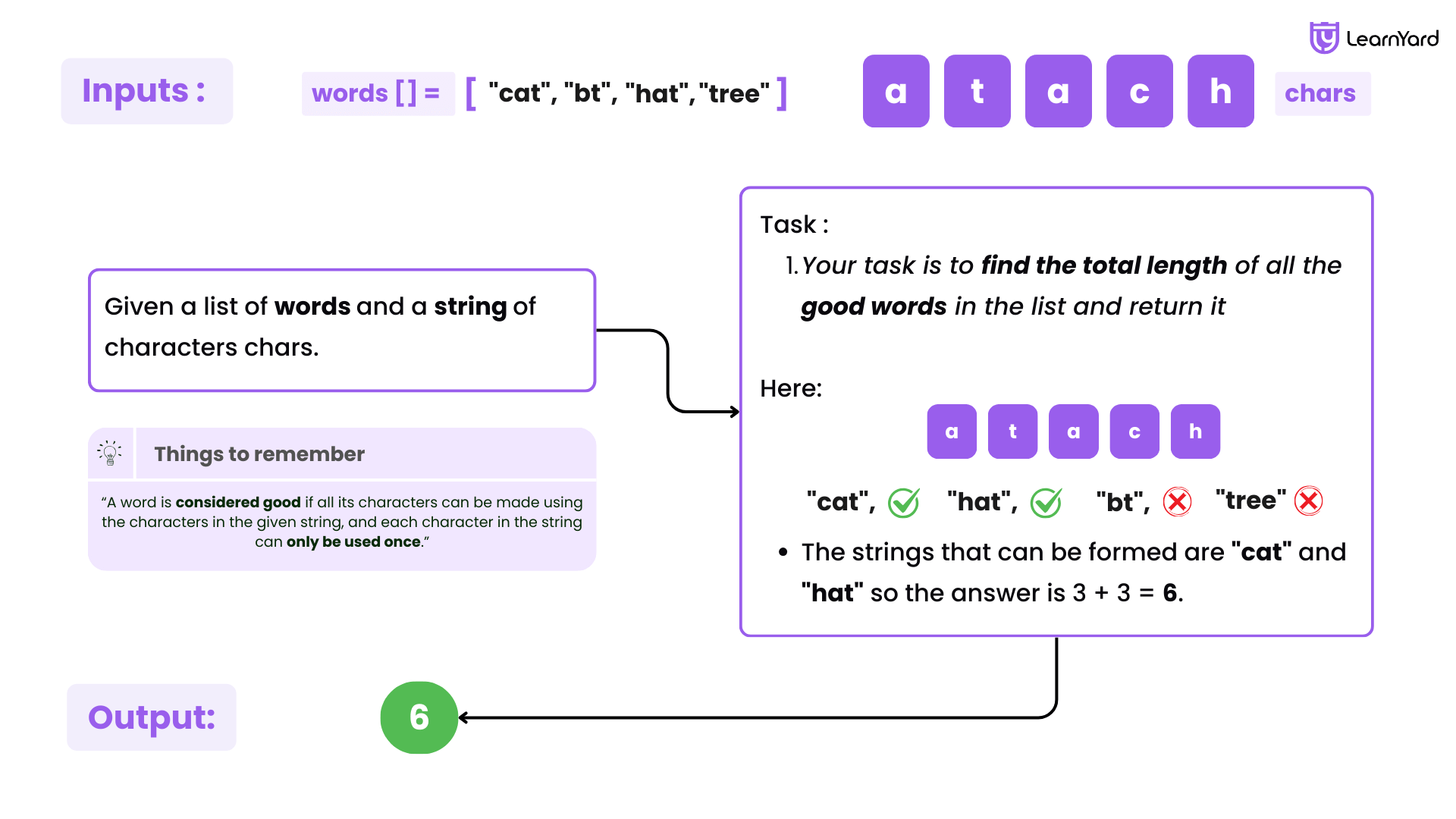
Examples:
Input: words = ["cat","bt","hat","tree"] chars = "atach"
Output: 6
Explanation: The strings that can be formed are "cat" and "hat" so the answer is 3 + 3 = 6.
Input: words = ["hello","world","leetcode"], chars = "welldonehoneyr"
Output: 10
Explanation: The strings that can be formed are "hello" and "world" so the answer is 5 + 5 = 10.
Constraints:
1 <= words.length <= 1000
1 <= words[i].length, chars.length <= 100
words[i] and chars consist of lowercase English letters.
Brute Force Approach:
The first thing that comes to mind after reading the problem is to check each word in words and see if it can be built from the letters in chars. For each word, we would verify if every letter in the word exists in chars and if there are enough occurrences of that letter in chars to match the word.
If a letter in the word cannot be matched due to insufficient frequency in chars, the word is not "good," and we skip it. If all letters of the word are matched successfully, it is considered "good," and we count the length of that word.
How do we do this?
To determine the sum of lengths of "good" strings in the list of words, we process each word in the words list one at a time. For every word, we iterate through each character and compare it with the characters in the chars string. For each character in the word, we count how many times it appears in the chars string and check if it is sufficient to form the word.
If any character in the word requires more occurrences than are available in chars, the word cannot be formed and is considered "not good". However, if all characters in the word are found in chars with sufficient occurrences, the word is "good". In this case, we add the length of the word to a running total. Once all words in the list have been processed, the total length of all "good" words is returned as the result. This approach uses nested loops to compare each word's characters with those in the chars string.
Let's walk through an example:
Dry run for Input: words = ["cat","bt","hat","tree"] chars = "atach"
Step-by-Step Dry Run:
- chars = "atach"
- Process each word:
- Word "cat":Check 'c': Found in chars → Remove 'c'.Remaining chars = "atah".Check 'a': Found in chars → Remove 'a'.Remaining chars = "tah".Check 't': Found in chars → Remove 't'.Remaining chars = "h".All characters matched. Add 3 to the total.
- Word "bt":Check 'b': Not found in chars.Word is not "good." Skip.
- Word "hat": Reset chars = "atach".Check 'h': Found in chars → Remove 'h'.Remaining chars = "atac".Check 'a': Found in chars → Remove 'a'.Remaining chars = "tac".Check 't': Found in chars → Remove 't'.Remaining chars = "c".All characters matched. Add 3 to the total.
- Word "tree":Reset chars = "atach".Check 't': Found in chars → Remove 't'.Remaining chars = "acah".Check 'r': Not found in chars.Word is not "good." Skip.
- Total length of "good" words: 6.
Output: 6
How to code it up:
- Iterate Over Each Word:
- For each word in the words list, we check if it can be constructed using the characters in chars.
- Match Each Character:
- For every character in the word, we loop through the characters in chars to see if it is present.
- If a match is found, the character is "used," and we remove it to ensure each character is used only once.
- Check If Word is "Good":
- If all characters of the word can be matched in chars without exceeding the available occurrences, the word is considered "good".
- Add the word's length to a running total.
- Return the Result:
- After processing all the words, return the total length of all "good" words.
Code Implementation
1. C++ Try on Compiler
class Solution {
public:
int countCharacters(vector<string>& words, string chars) {
int totalLength = 0;
// Step 1: Iterate over each word
for (const string& word : words) {
// Copy chars to use for matching
string availableChars = chars;
bool isGood = true;
// Step 2: Check each character in the word
for (char c : word) {
// Find the character in the availableChars
size_t pos = availableChars.find(c);
if (pos != string::npos) {
// Remove the character from availableChars (mark as used)
availableChars.erase(pos, 1);
} else {
// Character not found or insufficient
isGood = false;
break;
}
}
// Step 3: Add the length of "good" words
if (isGood) {
totalLength += word.size();
}
}
return totalLength;
}
};
2. Java Try on Compiler
class Solution {
public int countCharacters(String[] words, String chars) {
int totalLength = 0;
// Iterate over each word
for (String word : words) {
String availableChars = chars;
boolean isGood = true;
// Check each character in the word
for (char c : word.toCharArray()) {
int pos = availableChars.indexOf(c);
// Character found
if (pos != -1) {
availableChars = availableChars.substring(0, pos) + availableChars.substring(pos + 1);
} else {
isGood = false;
break;
}
}
// Add the length of "good" words
if (isGood) {
totalLength += word.length();
}
}
return totalLength;
}
};3. Python Try on Compiler
class Solution(object):
def countCharacters(self, words, chars):
# Initialize the total length of "good" words
total_length = 0
# Step 1: Iterate over each word in words
for word in words:
# Copy chars to use for matching
available_chars = list(chars)
is_good = True
# Step 2: Check each character in the word
for char in word:
if char in available_chars:
# Remove the character from available_chars (mark as used)
available_chars.remove(char)
else:
# Character not found or insufficient
is_good = False
break
# Step 3: Add the length of "good" words
if is_good:
total_length += len(word)
return total_length4. Javascript Try on Compiler
/**
* @param {string[]} words
* @param {string} chars
* @return {number}
*/
var countCharacters = function(words, chars) {
let totalLength = 0;
// Iterate over each word
for (const word of words) {
let availableChars = chars;
let isGood = true;
for (const c of word) {
// Check each character in the word
const pos = availableChars.indexOf(c);
if (pos !== -1) {
availableChars = availableChars.substring(0, pos) + availableChars.substring(pos + 1);
} else {
isGood = false;
break;
}
}
// Add the length of "good" words
if (isGood) {
totalLength += word.length;
}
}
return totalLength;
};
Time Complexity: O(n*m*k)
- Outer Loop Over Words:
- The outer loop iterates through each word in the words vector.
- If the number of words is denoted as n, this loop runs O(n) times.
- Inner Loop Over Characters in Each Word:
- For each word, the inner loop iterates through each character of the word.
- Let m represent the average length of the words.
- Therefore, the inner loop contributes O(m) operations per word.
- Finding a Character in availableChars:
- Inside the inner loop, the find function searches for the character in availableChars, which has a worst-case time complexity of O(k), where k is the length of the chars string.
- Since we remove characters from availableChars, its size decreases with each successful match.In the worst case, where every word is "good" and matches entirely:
- k starts at the initial length of chars and decreases over iterations.
- However, this does not exceed O(k) for all operations across one word.
Overall Time Complexity
For n words of average length m, with k characters in chars, the total time complexity is: O(n*m*k)
The overall time complexity is: O(n*m*k)
Space Complexity: O(n)
Auxiliary Space Complexity: O(1)
Explanation: The algorithm uses a constant amount of additional space for temporary variables such as: The size of available is equal to the length of the chars string, which is constant for all words.
Isgood (a boolean flag to determine if a word is good).
These temporary variables and the logic do not grow with the input size, so the auxiliary space complexity remains O(1).
Total Space Complexity: O(n+k)
The input list words and the string chars occupy space proportional to their lengths.
Let's denote:
n as the total number of characters in all words combined.
k as the length of the chars string.
So, the total space complexity will be O(n+k).(since O(k) is negligible for large n ) = O(n)
Will the Brute Force Approach Work Within the Given Constraints?
Let’s consider if the brute force method will work with the constraints we’re given.
The problem specifies that the maximum number of words (n) in the input list can go up to 1,000, and the maximum length of each word (m) or the chars string can go up to 100.
Using a brute force approach, for each word, we would count its characters and compare them against the available characters in chars. Now, if n=1000 and m=100 the total number of operations would be around 10⁵, which is manageable within typical time limits for competitive programming problems.
However, if either n or m grows significantly, this approach would quickly become impractical due to the quadratic growth in complexity.
For the given constraints, while the brute force method would technically work and provide the correct result, it is far from optimal .when dealing with larger input sizes and can’t handle the upper limits of the constraints.
Can we optimize it?
The brute force approach for the given problem, involves iterating through each word and checking each character against the available characters in the string chars.
The core issue lies in its repeated character checks and modifications to the chars string within the nested loops. For each character in every word, the code searches for the character within the chars string, which can have a time complexity of O(k) in the worst case, where k is the length of the chars string.
To overcome the limitation of brute force that involves checking every character in chars. we need a more efficient strategy that minimizes redundant operations. By precomputing and storing the frequency of each character in chars, we can eliminate the need for repeated checks and modifications.
We need a data structure that allows us to know the frequency of elements in constant time, so we can instantly determine how many times an element is present without having to go through the entire list. This significantly improves the efficiency of the process.
Which data structure can be found useful here?
Yes, you’re right! We could use something like a hash table to store the count of each element as we go through the array.
What is a hash table?
A hash table can be thought of as an auxiliary array where each index stores data linked to a specific key. The hash function computes the index in this auxiliary array for a given key, allowing direct access to the stored value. This structure ensures fast operations since accessing an index in an array is an O(1) operation.
We can use an array-based approach. Instead of repeatedly searching and removing characters, we can count the frequency of each character in chars using a fixed-size array of size 26 (for lowercase English letters). Similarly, we count the frequency of characters in each word.
By comparing these frequency arrays, we can determine if a word can be formed using the available characters.
This approach reduces the complexity significantly to O(n*m), as checking the frequencies becomes a constant-time operation for each character.
Here’s how we do it:
1.Precompute Character Frequencies in chars:
Count Character Occurrences: Determine how many times each character appears in the chars string. This can be efficiently done using an array to store the frequency of each character.
2. Iterate Through Words:
- For each word in the words list:
- Count Character Frequencies in Word: Determine the frequency of each character within the current word.
- Compare Frequencies: Compare the frequency of each character in the word with its frequency in the chars string. If the word requires more occurrences of any character than are available in chars, the word is invalid.
3.Calculate Total Length: If a word is determined to be valid (i.e., all its characters can be formed using the available characters in chars), add the length of that word to a running total.
4.Return Total Length: After processing all words in the words list, return the total length of all valid words.
Let’s take an example to make this clearer.
Dry run for Input:
words = ["cat","bt","hat","tree"] chars = "atach"
Step-by-Step Dry Run:
1. Count Character Frequencies in chars:
- Create a counter for each lowercase letter (a-z).
- Count the occurrences of each letter in the string "atach".
- 'a' occurs twice
- 't' occurs once
- 'c' occurs once
- 'h' occurs once
2. Process Each Word:
- "cat":
- Count the occurrences of each letter in "cat".
- Compare the counts:'c': 1 occurrence in "cat", 1 occurrence available in chars (valid).'a': 1 occurrence in "cat", 2 occurrences available in chars (valid).'t': 1 occurrence in "cat", 1 occurrence available in chars (valid)
- Since all characters in "cat" can be formed using the available characters in chars, add the length of "cat" (3) to the total length.
- "bt":
- Count the occurrences of each letter in "bt".
- Compare the counts:'b': 1 occurrence in "bt", 0 occurrences available in chars (invalid).
- Since 'b' is not available in chars, the word "bt" is invalid.
- "hat":
- Count the occurrences of each letter in "hat".
- Compare the counts:'h': 1 occurrence in "hat", 1 occurrence available in chars (valid)'a': 1 occurrence in "hat", 2 occurrences available in chars (valid)'t': 1 occurrence in "hat", 1 occurrence available in chars (valid)
- Since all characters in "hat" can be formed using the available characters in chars, add the length of "hat" (3) to the total length.
- "tree":
- Count the occurrences of each letter in "tree".
- Compare the counts:'t': 1 occurrence in "tree", 1 occurrence available in chars (valid)'r': 1 occurrence in "tree", 0 occurrences available in chars (invalid)
- Since 'r' is not available in chars, the word "tree" is invalid.
3. Return Result:
- The total length of valid words ("cat" and "hat") is 6.
Output:6
How to code it up:
- Create an array CharCount of size 26 and initialize it to 0.
- For each character c in chars, increment counts[c - 'a'].
- Initialize ans = 0 to store the total length of valid words.
- For each word in words:
- Create a wordCount array of size 26 and compute character frequencies for the word.
- Set good = true.
- Check if wordCount[i] > Charcounts[i] for any i (0 to 25). If true, set good = false and break.
- If good is true, add the word’s length to ans.
- Return ans.
Code Implementation
1. C++ Try on Compiler
class Solution {
public:
int countCharacters(vector<string>& words, string chars) {
// Create CharCount array to store frequency of characters in chars
vector<int> CharCount(26, 0);
for (char c : chars) {
CharCount[c - 'a']++;
}
// Initialize total length of valid words
int ans = 0;
// Process each word in words
for (string word : words) {
// Frequency array for current word
vector<int> wordCount(26, 0);
for (char c : word) {
wordCount[c - 'a']++;
}
// Check if the word is valid
bool good = true;
for (int i = 0; i < 26; i++) {
if (wordCount[i] > CharCount[i]) {
good = false;
break;
}
}
// Add word length to ans if valid
if (good) {
ans += word.size();
}
}
// Return the total length
return ans;
}
};
2. Java Try on Compiler
class Solution {
public int countCharacters(String[] words, String chars) {
// Create CharCount array to store frequency of characters in chars
int[] CharCount = new int[26];
for (char c : chars.toCharArray()) {
CharCount[c - 'a']++;
}
//Initialize total length of valid words
int ans = 0;
// Process each word in words
for (String word : words) {
// Frequency array for current word
int[] wordCount = new int[26];
for (char c : word.toCharArray()) {
wordCount[c - 'a']++;
}
// Check if the word is valid
boolean good = true;
for (int i = 0; i < 26; i++) {
if (wordCount[i] > CharCount[i]) {
good = false;
break;
}
}
// Add word length to ans if valid
if (good) {
ans += word.length();
}
}
// Return the total length
return ans;
}
};3. Python Try on Compiler
class Solution(object):
def countCharacters(self, words, chars):
# Step 1: Create CharCount array to store frequency of characters in chars
CharCount = [0] * 26
for c in chars:
CharCount[ord(c) - ord('a')] += 1
ans = 0 # Step 2: Initialize total length of valid words
# Step 3: Process each word in words
for word in words:
wordCount = [0] * 26
for c in word:
wordCount[ord(c) - ord('a')] += 1
# Step 4: Check if the word is valid
good = True
for i in range(26):
if wordCount[i] > CharCount[i]:
good = False
break
if good:
# Add word length to ans if valid
ans += len(word)
return ans # Return the total length4. Javascript Try on Compiler
/**
* @param {string[]} words
* @param {string} chars
* @return {number}
*/
var countCharacters = function (words, chars) {
// Create CharCount array to store frequency of characters in chars
const charCount = new Array(26).fill(0);
for (const char of chars) {
charCount[char.charCodeAt(0) - 'a'.charCodeAt(0)]++;
}
// Initialize total length of valid words
let ans = 0;
// Process each word in words
for (const word of words) {
// Frequency array for current word
const wordCount = new Array(26).fill(0);
for (const char of word) {
wordCount[char.charCodeAt(0) - 'a'.charCodeAt(0)]++;
}
// Check if the word is valid
let good = true;
for (let i = 0; i < 26; i++) {
if (wordCount[i] > charCount[i]) {
good = false;
break;
}
}
// Add word length to ans if valid
if (good) {
ans += word.length;
}
}
// Return the total length
return ans;
};
Time Complexity: O(n * m)
Let's walk through the time complexity:
Precomputing Character Frequencies in chars:
- Creating the frequency array counts takes O(26) = O(1) because it has a fixed size for lowercase English letters.
- Iterating over chars to populate counts takes O(k), where k is the length of chars.
Processing Each Word in words:
- For each word, creating and populating the wordFreq array takes O(m), where m is the length of the word.
- Comparing the wordFreq array with counts also takes O(26) = O(1) since the array size is fixed.
For all n words, this results in a time complexity of O(n * m).
Final Complexity:
- Adding everything together, the overall time complexity is: O(k) + O(n * m) ≈ O(n * m)(since O(k) is negligible for large n * m)
Space Complexity: O(n)
Auxiliary Space Complexity: O(1)
Explanation: We use two arrays: CharCount and wordCount.Both arrays have a fixed size of 26, representing the count of each lowercase letter in the English alphabet.
The size of these arrays does not depend on the input string size (length of chars or the length of any individual word in words).
Therefore, the space used by these arrays is constant, resulting in O(1) auxiliary space complexity.
These temporary variables and the logic do not grow with the input size, so the auxiliary space complexity remains O(1).
Total Space Complexity: O(n)
The input list words and the string chars occupy space proportional to their lengths. Let's denote:
n as the total number of characters in all words combined.
k as the length of the chars string.
So, the total space complexity will be O(n+k). (since O(k) is negligible for large n, since it can be at most 26 ) = O(n)
Learning Tip
Now we have successfully tackled this problem, let's try these similar problems.
We are given two strings s, and t, and we need to figure out if they are isomorphic. Two strings s and t are isomorphic if we can replace characters in string s in such a way that it becomes string t.Here are the key points to understand, for strings to be isomorphic:
- Each character in s should map to one and only one character in t.
- No two characters from s can map to the same character in t (though a character can map to itself).
Given a string s, partition the string into one or more substrings such that the characters in each substring are unique. That is, no letter appears in a single substring more than once.Return the minimum number of substrings in such a partition.Note that each character should belong to exactly one substring in a partition.