Count the Number of Good Partitions Solution In C++/Python/Java/Javascript
Problem Description:
You are given a 0-indexed array nums consisting of positive integers.
A partition of an array into one or more contiguous subarrays is called good if no two subarrays contain the same number.
Return the total number of good partitions of nums.
Since the answer may be large, return it modulo 10⁹ + 7.
Examples:
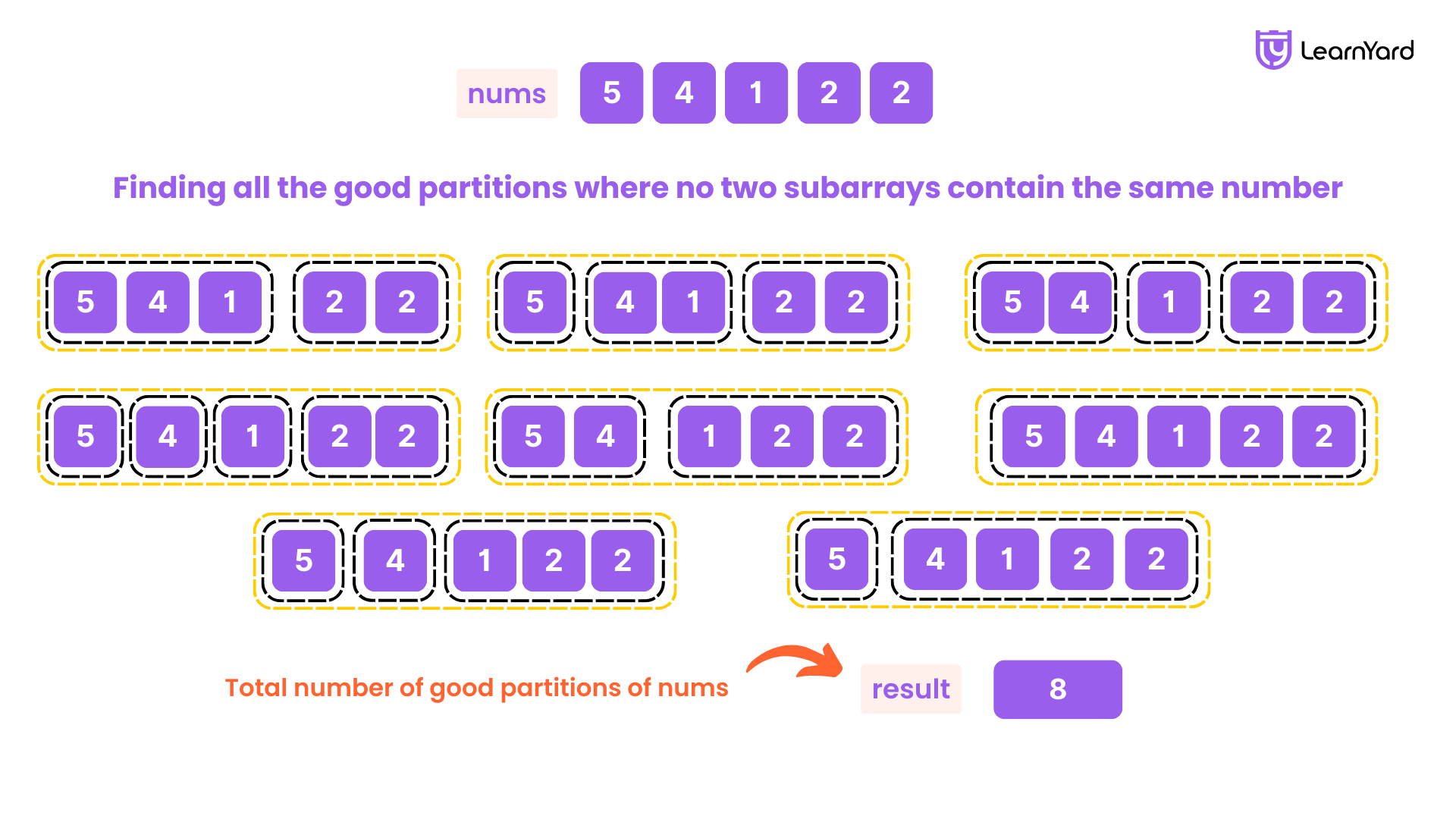
Input: nums = [1,2,3,4]
Output: 8
Explanation: The 8 possible good partitions are: ([1], [2], [3], [4]), ([1], [2], [3,4]), ([1], [2,3], [4]), ([1], [2,3,4]), ([1,2], [3], [4]), ([1,2], [3,4]), ([1,2,3], [4]), and ([1,2,3,4]).
Input: nums = [1,1,1,1]
Output: 1
Explanation: The only possible good partition is: ([1,1,1,1]).
Input: nums = [1,2,1,3]
Output: 2
Explanation: The 2 possible good partitions are: ([1,2,1], [3]) and ([1,2,1,3]).
Constraints:
1 ≤ nums.length ≤ 10⁵
1 ≤ nums[i] ≤ 10⁹
Brute Force Approach
When we read the problem statement, the first idea that comes to mind is simple:
To find the number of good partitions, the straightforward approach is to generate all possible partitions and evaluate each one to determine if it is good.
A partition is considered good if no number is repeated in any two of its subsets. In other words, all subsets of the partition must be disjoint in terms of their elements.
After generating all the partitions, we can simply check each one, count the good partitions, and return the total number of such partitions.
Note: The brute force implementation can be quite complex and highly inefficient, especially with larger inputs.
How to do it?
To solve the problem, we follow these steps:
- Generate All Possible Partitions:
For each element in the array, there are two possibilities:- It can be added to an existing subset, continuing from where the previous element is placed.
- It can start a new subset of its own.
Using this recursive approach, we can systematically generate all possible partitions of the array.
- Count Good Partitions:
Once all partitions are generated, we need to count the ones that are "good."- For each partition, we maintain a hash set to track the elements that have been included.
- For every subset within the partition, we check if any element already exists in the hash set. If so, the partition is invalid, and we discard it.
- Otherwise, we add all the elements of the current subset to the hash set and proceed to the next subset.
- If the entire partition is validated without duplicates, we increment the count of good partitions.
- Return the Answer:
After evaluating all partitions, the final count of good partitions is returned as the result.
This approach ensures that we efficiently generate and validate all partitions while adhering to the condition of no duplicate elements across subsets.
Let's understand with an example:
Input: nums = [1, 2, 1, 3]
- Generate all partitions:
Possible partitions include:
[[1, 2, 1, 3]]
[[1], [2, 1, 3]]
[[1, 2], [1, 3]]
[[1], [2], [1, 3]]
[[1, 2, 1], [3]]
[[1], [2, 1], [3]]
[[1, 2], [1], [3]]
[[1], [2], [1], [3]] - Check for "good partitions":
A "good partition" ensures no number repeats across subsets.
[[1, 2, 1, 3]]: Good, no repeats
[[1], [2, 1, 3]]: Not good, 1 repeats.
[[1, 2], [1, 3]]: Not good, 1 repeats.
[[1], [2], [1, 3]]: Not good, 1 repeats.
[[1, 2, 1], [3]]: Good, no repeats.
[[1], [2, 1], [3]]: Not good, 1 repeats.
[[1, 2], [1], [3]]: Not good, 1 repeats.
[[1], [2], [1], [3]]: Not good, 1 repeats. - Count valid partitions:
Result: Valid partitions count = 2.
How to code it up?
Here are the concise steps to code the solution for counting "good partitions":
- Define the Modulo Constant:
Set a constant MODULO to 1e9 + 7 for handling large results. - Generate All Partitions:
Create a helper function generatePartitions that will recursively explore all ways to partition the array.
For each element, either add it to an existing subset or start a new subset, and repeat the process for the remaining elements. - Create the Partitioning Function:
Use the generatePartitions function to generate all possible partitions of the input array.
This function will return all possible partitions as a list of lists of subsets. - Check for Good Partitions:
For each partition, initialize a set<int> to keep track of unique elements seen across subsets.
Traverse each subset of the partition and check if any element repeats in different subsets.
If any duplicate element is found, discard the partition; otherwise, it's valid. - Count Valid Partitions:
For every valid partition (no duplicates), increment the count of good partitions.
Apply MODULO to the final result to prevent overflow. - Return the Count:
After processing all partitions, return the total count of good partitions modulo MODULO.
Code Implementation
1. C++ Try on Compiler
class Solution {
// Constant for modulo operation to handle large numbers
const int MODULO = 1e9 + 7;
// Helper function to recursively generate all possible partitions of the array
void generatePartitions(int startIndex, const vector<int>& inputArray, vector<vector<int>>& currentPartition, vector<vector<vector<int>>>& allPartitions) {
// Base case: when we've processed all elements, add the current partition to the result
if (startIndex == inputArray.size()) {
allPartitions.push_back(currentPartition);
return;
}
// Loop over possible end indexes for the current subset
for (int endIndex = startIndex; endIndex < inputArray.size(); ++endIndex) {
// Create a new subset from startIndex to endIndex
vector<int> subset(inputArray.begin() + startIndex, inputArray.begin() + endIndex + 1);
// Add the new subset to the current partition
currentPartition.push_back(subset);
// Recursively generate partitions starting from the next index
generatePartitions(endIndex + 1, inputArray, currentPartition, allPartitions);
// Backtrack: remove the last subset to explore other partition options
currentPartition.pop_back();
}
}
// Function to generate all partitions of the input array
vector<vector<vector<int>>> partitionArray(const vector<int>& inputArray) {
// Stores all possible partitions
vector<vector<vector<int>>> allPartitions;
// Stores the current partition being built
vector<vector<int>> currentPartition;
// Start generating partitions from the first element
generatePartitions(0, inputArray, currentPartition, allPartitions);
return allPartitions;
}
public:
// Function to count the number of "good" partitions
int numberOfGoodPartitions(vector<int>& inputArray) {
// Generate all possible partitions of the input array
vector<vector<vector<int>>> allPartitions = partitionArray(inputArray);
// Counter for good partitions
int validPartitionCount = 0;
// Loop over each generated partition to check if it's "good"
for (const auto& partition : allPartitions) {
// Set to track unique elements across all subsets in the partition
set<int> uniqueElements;
// Flag to mark if the partition has any duplicates
bool isInvalidPartition = false;
// Loop over each subset in the partition
for (const auto& subset : partition) {
// Flag to check if there is any duplicate within the current subset
bool hasDuplicate = false;
// Check if any element in the subset has already appeared in previous subsets
for (int element : subset) {
if (uniqueElements.count(element)) {
hasDuplicate = true;
break;
}
}
// If there is a duplicate, mark this partition as invalid and break
if (hasDuplicate) {
isInvalidPartition = true;
break;
}
// Add all elements of the current subset to the uniqueElements set
for (int element : subset) {
uniqueElements.insert(element);
}
}
// If no duplicates were found, increment the count of valid partitions
if (!isInvalidPartition)
validPartitionCount = (validPartitionCount + 1) % MODULO;
// Clear the uniqueElements set for the next partition
uniqueElements.clear();
}
// Return the count of good partitions
return validPartitionCount;
}
};
2. Java Try on Compiler
class Solution {
// Constant for modulo operation to handle large numbers
final int MODULO = 1000000007;
// Helper function to recursively generate all possible partitions of the array
void generatePartitions(int startIndex, int[] inputArray,
List<List<List<Integer>>> allPartitions, List<List<Integer>> currentPartition) {
// Base case: when we've processed all elements, add the current partition to the result
if (startIndex == inputArray.length) {
allPartitions.add(new ArrayList<>(currentPartition));
return;
}
// Loop over possible end indexes for the current subset
for (int endIndex = startIndex; endIndex < inputArray.length; ++endIndex) {
// Create a new subset from startIndex to endIndex
List<Integer> subset = new ArrayList<>();
for (int i = startIndex; i <= endIndex; i++) {
subset.add(inputArray[i]);
}
// Add the new subset to the current partition
currentPartition.add(subset);
// Recursively generate partitions starting from the next index
generatePartitions(endIndex + 1, inputArray, allPartitions, currentPartition);
// Backtrack: remove the last subset to explore other partition options
currentPartition.remove(currentPartition.size() - 1);
}
}
// Function to generate all partitions of the input array
public int numberOfGoodPartitions(int[] inputArray) {
List<List<List<Integer>>> allPartitions = new ArrayList<>();
List<List<Integer>> currentPartition = new ArrayList<>();
generatePartitions(0, inputArray, allPartitions, currentPartition);
int validPartitionCount = 0; // Counter for good partitions
// Loop over each generated partition to check if it's "good"
for (List<List<Integer>> partition : allPartitions) {
Set<Integer> uniqueElements = new HashSet<>(); // Set to track unique elements across all subsets in the partition
boolean isInvalidPartition = false; // Flag to mark if the partition has any duplicates
// Loop over each subset in the partition
for (List<Integer> subset : partition) {
boolean hasDuplicate = false; // Flag to check if there is any duplicate within the current subset
// Check if any element in the subset has already appeared in previous subsets
for (int element : subset) {
if (uniqueElements.contains(element)) {
hasDuplicate = true;
break;
}
}
// If there is a duplicate, mark this partition as invalid and break
if (hasDuplicate) {
isInvalidPartition = true;
break;
}
// Add all elements of the current subset to the uniqueElements set
uniqueElements.addAll(subset);
}
// If no duplicates were found, increment the count of valid partitions
if (!isInvalidPartition) {
validPartitionCount = (validPartitionCount + 1) % MODULO;
}
}
return validPartitionCount; // Return the count of good partitions
}
}
3. Python Try on Compiler
class Solution:
# Constant for modulo operation to handle large numbers
MODULO = 10**9 + 7
# Helper function to recursively generate all possible partitions of the array
def generatePartitions(self, startIndex, inputArray, currentPartition, allPartitions):
# Base case: when we've processed all elements, add the current partition to the result
if startIndex == len(inputArray):
allPartitions.append(currentPartition[:])
return
# Loop over possible end indexes for the current subset
for endIndex in range(startIndex, len(inputArray)):
# Create a new subset from startIndex to endIndex
subset = inputArray[startIndex:endIndex + 1]
# Add the new subset to the current partition
currentPartition.append(subset)
# Recursively generate partitions starting from the next index
self.generatePartitions(endIndex + 1, inputArray, currentPartition, allPartitions)
# Backtrack: remove the last subset to explore other partition options
currentPartition.pop()
# Function to generate all partitions of the input array
def numberOfGoodPartitions(self, inputArray):
allPartitions = []
currentPartition = []
self.generatePartitions(0, inputArray, currentPartition, allPartitions)
validPartitionCount = 0 # Counter for good partitions
# Loop over each generated partition to check if it's "good"
for partition in allPartitions:
uniqueElements = set() # Set to track unique elements across all subsets in the partition
isInvalidPartition = False # Flag to mark if the partition has any duplicates
# Loop over each subset in the partition
for subset in partition:
hasDuplicate = False # Flag to check if there is any duplicate within the current subset
# Check if any element in the subset has already appeared in previous subsets
for element in subset:
if element in uniqueElements:
hasDuplicate = True
break
# If there is a duplicate, mark this partition as invalid and break
if hasDuplicate:
isInvalidPartition = True
break
# Add all elements of the current subset to the uniqueElements set
uniqueElements.update(subset)
# If no duplicates were found, increment the count of valid partitions
if not isInvalidPartition:
validPartitionCount = (validPartitionCount + 1) % self.MODULO
return validPartitionCount # Return the count of good partitions
4. Javascript Try on Compiler
/**
* @param {number[]} nums
* @return {number}
*/
// Constant for modulo operation to handle large numbers
const MODULO = 1e9 + 7;
// Helper function to recursively generate all possible partitions of the array
var generatePartitions = function (startIndex, nums, currentPartition, allPartitions) {
// Base case: when we've processed all elements, add the current partition to the result
if (startIndex === nums.length) {
allPartitions.push([...currentPartition]);
return;
}
// Loop over possible end indexes for the current subset
for (let endIndex = startIndex; endIndex < nums.length; endIndex++) {
// Create a new subset from startIndex to endIndex
let subset = nums.slice(startIndex, endIndex + 1);
// Add the new subset to the current partition
currentPartition.push(subset);
// Recursively generate partitions starting from the next index
generatePartitions(endIndex + 1, nums, currentPartition, allPartitions);
// Backtrack: remove the last subset to explore other partition options
currentPartition.pop();
}
}
var numberOfGoodPartitions = function (nums) {
let allPartitions = [];
let currentPartition = [];
generatePartitions(0, nums, currentPartition, allPartitions); // Fixed variable name here
let validPartitionCount = 0; // Counter for good partitions
// Loop over each generated partition to check if it's "good"
for (let partition of allPartitions) {
// Set to track unique elements across all subsets in the partition
let uniqueElements = new Set();
// Flag to mark if the partition has any duplicates
let isInvalidPartition = false;
// Loop over each subset in the partition
for (let subset of partition) {
// Flag to check if there is any duplicate within the current subset
let hasDuplicate = false;
// Check if any element in the subset has already appeared in previous subsets
for (let element of subset) {
if (uniqueElements.has(element)) {
hasDuplicate = true;
break;
}
}
// If there is a duplicate, mark this partition as invalid and break
if (hasDuplicate) {
isInvalidPartition = true;
break;
}
// Add all elements of the current subset to the uniqueElements set
for (let element of subset) {
uniqueElements.add(element);
}
}
// If no duplicates were found, increment the count of valid partitions
if (!isInvalidPartition) {
validPartitionCount = (validPartitionCount + 1) % MODULO;
}
}
// Return the count of good partitions
return validPartitionCount;
};
Time Complexity: O(2ⁿ * n²)
The time complexity of the brute force approach is as follows:
- Generating all possible partitions:
When generating all partitions of an array, for each element, there are two primary choices:
The element can stay in the existing subset where the previous element is located.
Alternatively, the element can start a new subset of its own.
Thus, for each element, you have two choices, leading to 2ⁿ different partitions.
Why 2ⁿ?:
This exponential growth occurs because:
For each of the n elements in the array, you have the choice of either placing it in an existing subset or starting a new one.
The number of ways to make these choices across all n elements is 2 × 2 × ... × 2 (n times), which is 2ⁿ. - Checking each partition:
After generating all partitions, we need to check whether each partition is "good."
To check if a partition is good, we iterate through each subset in the partition and ensure there are no duplicates.
For each partition, the time complexity to check duplicates is proportional to the number of subsets and the number of elements in those subsets.
In the worst case, checking a partition takes O(n²) time, where n is the number of elements in the array, because there could be n subsets, and checking each subset involves checking n elements.
Overall Time Complexity:
- Generating all partitions takes O(2ⁿ) time.
- Checking each partition takes O(n²) time.
Thus, the overall time complexity is O(2ⁿ * n²), where:
- 2ⁿ represents the number of possible partitions.
- n² represents the time required to check each partition for duplicates.
Space Complexity: O(2ⁿ * n²)
Auxiliary Space Complexity: O(n²)
Recursive Call Stack: The recursion depth is at most n, where n is the size of the input array.
Space due to recursion: O(n).
Current Partition Storage:
The currentPartition vector stores the subsets being constructed at each level of recursion. Each subset can have up to n elements, and in the worst case, there can be n subsets in a partition.
Space due to currentPartition: O(n²).
Set for Uniqueness Check:
The uniqueElements set can hold at most n elements during validation.
Space due to uniqueElements: O(n).
Total Space Complexity: O(2ⁿ * n²)
All Partitions Storage:
The number of partitions of an array corresponds to 2ⁿ, as each element can independently start a new subset or join an existing one. Each partition can have up to n subsets, and each subset can contain up to n elements.
Space due to allPartitions: O(2ⁿ * n² ).
Thus, the total space complexity is: O(2ⁿ * n²) + O(n²) = O(2ⁿ * n²)
Will Brute Force Work Against the Given Constraints?
The current solution has a time complexity of O(2ⁿ.n²) and a space complexity of O(2ⁿ.n²). This is not suitable for n ≤ 10⁵, as the number of operations for the worst-case scenario would be astronomically large due to the exponential growth of 2ⁿ.
The algorithm generates all possible partitions of the array, which corresponds to 2ⁿ. For n=10⁵, the total number of partitions exceeds 10³⁰, making it computationally infeasible to generate and process all partitions.
For each partition, the algorithm performs O(n²) operations, which involves processing subsets and validating their elements. This results in an overwhelming number of operations, far exceeding feasible limits for competitive programming.
The solution explicitly stores all partitions, requiring O(2ⁿ.n²) space to handle the subsets and their elements. This leads to Memory Limit Exceeded (MLE) errors as the storage requirements grow exponentially with n.
For n=10⁵, the time complexity O(2ⁿ.n²) results in a minimum of 10³⁰ operations, leading to Time Limit Exceeded (TLE) errors. Similarly, the space complexity O(2ⁿ.n²) results in unmanageable memory usage, leading to MLE errors.
Conclusion:
This solution, with its O(2ⁿ.n²) time and space complexity, is unsuitable for n=10⁵. It will lead to TLE errors due to excessive operations and MLE errors due to exponential memory requirements, making it impractical for competitive programming or large-scale inputs.
Can we optimize it?
Yes, of course!
We can definitely optimize it—let's do it!
In the previous approach, we checked all possible partitions of the array nums to see if they were good. A good partition means all subsets are disjoint and don't contain any repeated numbers. However, this resulted in O(2ⁿ.n²) time and space complexity, which becomes infeasible for large values of n.
Now, let's see how we can optimize this approach!
Observation 1:
The main thing we need to ensure is that an element doesn't appear in more than one subset. If it does, the partition is not a good partition. To make sure this doesn't happen, we can do something simple:
Whenever we encounter an element, we can make the subset include all the occurrences of that element until its last occurrence in the array nums. This will guarantee that each element appears in only one subset, and no subsets share common elements.
For example, if nums = [1, 2, 1, 3], we would create the subset [1, 2, 1], meaning all occurrences of 1 must stay in the same subset.
Observation 2:
For each element, we have two choices:
- Keep the element in the same subset as the previous one.
- Start a new subset with the current element.
In the brute-force approach, every element had these two choices, which led to 2ⁿ partitions.
But for a good partition, an element should only be in one subset. So, combining both observations:
Once we find a good subset (where no element repeats), we have two choices:
- Expand the current subset by adding more elements.
- Conclude the current subset and start a new one ahead.
For example, if nums = [1, 2, 1, 3], we find one good subset as [1, 2, 1]. Now we have two choices:
- Conclude the subset as [1, 2, 3], and start a new subset [3].
- Expand the subset by adding 3 to it: [1, 2, 1, 3].
Now, let’s break this down step by step in simple words. Starting with the array nums = [1, 2, 1, 3, 4, 5, 6], we know that all occurrences of the same number must be contained within the same subset. This means the first subset must include [1, 2, 1] because the number 1 appears at indices 0 and 2, so we can’t split it into different subsets.
Now, for the next number, 3, we have two choices:
- Add 3 to the existing subset, making it [1, 2, 1, 3].
- Start a new subset from 3, making it [1, 2, 1][3].
When we move to the next number, 4, we again have two options for 4 for each of the previous choices of 3:
- Add 4 to the last subset of the previous option, giving [1, 2, 1, 3, 4] and [1, 2, 1][3, 4].
- Start a new subset from 4, giving [1, 2, 1, 3][4] and [1, 2, 1][3][4].
So now we have 4 total options. When we get to 5, we will again have 2 choices for each of the 4 previous options, leading to 8 total options. Similarly, for 6, we’ll have 16 options, as each valid subset choice doubles the total possibilities.
The doubling happens because, at each step, we have two choices for the next element:
- Add it to the last subset (continue the previous group).
- Start a new subset (make a new group starting with this element).
For every option we already have, these two choices create two new possibilities. For example, if we already have 4 ways to group the elements so far, adding the next element will give us 2 new options for each of those 4 ways, resulting in 8 total options.
So, we will maintain a count and multiply it by 2 whenever we encounter a valid point. This multiplication accounts for the two choices available at each step—either adding the current element to the last subset or starting a new subset. By doing so, we efficiently calculate all possible ways to partition the array into "good subsets."
This optimized approach avoids the exponential growth of partitions and makes the solution more efficient.
How to do it?
Here's the approach with the steps:
Step 1: Store Last Occurrence of Each Element
- First, we need to store the last index or last occurrence of each element in the array nums by using a hashmap. This will help us ensure that each element appears in only one subset, preventing any overlap between subsets.
Step 2: Traverse the Array and Calculate Partitions
- Once we have the last occurrence of each element, we can begin traversing the array. For each element, we update our partition boundary to ensure that no element appears in more than one subset.
- As we encounter each element, we will adjust our partition boundary to be the maximum of the current boundary and the last occurrence of the current element. This ensures that all occurrences of the current element remain within the same subset.
Step 3: Track Number of Valid Partitions
- For each element, if we reach a point where the current index exceeds the partition boundary, we know that a valid partition can be made at that point. For each valid partition, we multiply our result by 2, as we have two choices: either extend the current subset or start a new subset.
Step 4: Return the Result
- After processing all elements, the value we have stored in our result variable will represent the total number of valid partitions that can be formed.
Let's understand with an example:
Consider the array nums = [1, 2, 3, 4].
- Initialization:
- n = 4
- ans = 1
- mp = {1: 0, 2: 1, 3: 2, 4: 3} (last occurrence indices of each element)
- Traversal:
- Start with j = 0 (last occurrence of nums[0]).
- For i = 0 (element = 1), j = max(0, 0) = 0. No update to ans.
- For i = 1 (element = 2), j = max(0, 1) = 1. Since i > j, we update ans = ans * 2 = 2.
- For i = 2 (element = 3), j = max(1, 2) = 2. Since i > j, we update ans = ans * 2 = 4.
- For i = 3 (element = 4), j = max(2, 3) = 3. Since i > j, we update ans = ans * 2 = 8.
- Final Result:
- The final value of ans is 8, which represents the total number of valid partitions.
- Output: 8
How to code it up:
Here are the steps to code it up:
- Initialize Data Structures:
Create a map (unordered_map) to store the last occurrence index of each element in the array nums.
Initialize ans = 1 to store the number of valid partitions. - Store Last Occurrence:
Loop through the array nums and populate the map with each element's last occurrence index. - Set Initial Partition Boundary:
Initialize partitionBoundary = map[nums[0]] to store the last occurrence of the first element as the initial partition boundary. - Traverse Array:
Loop through the array and for each element nums[i]:
Update partitionBoundary = max(partitionBoundary, map[nums[i]]) to adjust the partition boundary.
If i > partitionBoundary, multiply ans by 2 (indicating a valid partition at this point). - Return Result:
After traversing the array, return ans, which contains the total number of valid partitions.
Code Implementation
1. C++ Try on Compiler
class Solution {
const int mod = 1e9 + 7;
public:
int numberOfGoodPartitions(vector<int>& nums) {
int n = nums.size();
int ans = 1;
// Map to store the last occurrence index of each element
unordered_map<int, int> lastOccurrence;
for (int i = 0; i < n; i++) {
lastOccurrence[nums[i]] = i;
}
// Initial partition boundary based on the first element's last occurrence
int partitionBoundary = lastOccurrence[nums[0]];
// Traverse through the array and compute valid partitions
for (int i = 0; i < n; i++) {
// If current index is greater than the partition boundary, multiply ans by 2
if (i > partitionBoundary) {
ans = (ans * 2) % mod;
}
// Update partition boundary
partitionBoundary = max(partitionBoundary, lastOccurrence[nums[i]]);
}
return ans;
}
};
2. Java Try on Compiler
class Solution {
// Modulo value for large numbers
final int mod = (int) 1e9 + 7;
public int numberOfGoodPartitions(int[] nums) {
int n = nums.length;
int ans = 1;
// Map to store the last occurrence index of each element
Map<Integer, Integer> lastOccurrence = new HashMap<>();
for (int i = 0; i < n; i++) {
lastOccurrence.put(nums[i], i);
}
// Initial partition boundary based on the first element's last occurrence
int partitionBoundary = lastOccurrence.get(nums[0]);
// Traverse through the array and compute valid partitions
for (int i = 0; i < n; i++) {
// If current index is greater than the partition boundary, multiply ans by 2
if (i > partitionBoundary) {
ans = (ans * 2) % mod;
}
// Update partition boundary
partitionBoundary = Math.max(partitionBoundary, lastOccurrence.get(nums[i]));
}
return ans;
}
}
3. Python Try on Compiler
class Solution:
# Modulo value for large numbers
mod = int(1e9 + 7)
def numberOfGoodPartitions(self, nums):
n = len(nums)
ans = 1
# Dictionary to store the last occurrence index of each element
last_occurrence = {}
for i in range(n):
last_occurrence[nums[i]] = i
# Initial partition boundary based on the first element's last occurrence
partition_boundary = last_occurrence[nums[0]]
# Traverse through the array and compute valid partitions
for i in range(n):
# If current index is greater than the partition boundary, multiply ans by 2
if i > partition_boundary:
ans = (ans * 2) % self.mod
# Update partition boundary
partition_boundary = max(partition_boundary, last_occurrence[nums[i]])
return ans
4. Javascript Try on Compiler
/**
* @param {number[]} nums
* @return {number}
*/
var numberOfGoodPartitions = function (nums) {
const n = nums.length;
const mod = 1e9 + 7;
let ans = 1;
// Map to store the last occurrence index of each element
const lastOccurrence = new Map();
for (let i = 0; i < n; i++) {
lastOccurrence.set(nums[i], i);
}
// Initial partition boundary based on the first element's last occurrence
let partitionBoundary = lastOccurrence.get(nums[0]);
// Traverse through the array and compute valid partitions
for (let i = 0; i < n; i++) {
// If current index is greater than the partition boundary, multiply ans by 2
if (i > partitionBoundary) {
ans = (ans * 2) % mod;
}
// Update partition boundary
partitionBoundary = Math.max(partitionBoundary, lastOccurrence.get(nums[i]));
}
return ans;
};Time Complexity: O(n)
The time complexity of the approach can be broken down into several steps:
- Building the lastOccurrence map (HashMap/Dictionary/Map):
We iterate over the array nums once to store the last occurrence of each element in the map. This takes O(n) time, where n is the number of elements in nums. - Traversing the array to calculate the result:
We traverse the array nums again once, updating the partitionBoundary and calculating the result. Each operation inside the loop (like comparing indices and updating values) takes constant time O(1).
Hence, this part of the code also takes O(n) time.
Therefore, the overall time complexity is O(n) + O(n) = O(n).
Space Complexity: O(n)
- Auxiliary Space Complexity: O(n)
Explanation: In this approach, the only extra space used is the lastOccurrence map (or dictionary/Map), which stores the last index of each unique element in the array nums.
Since this map will store at most n key-value pairs (where n is the number of unique elements in nums), the auxiliary space is O(n). - Total Space Complexity: O(n)
Explanation: The input data itself is the array nums, which takes O(n) space.
Therefore, the total space complexity is O(n), accounting for both the input array and the space used by the hashmap.
Learning Tip
Now we have successfully tackled this problem, let's try these similar problems.
1. Word Subsets
You are given two lists of words: words1 and words2.
A word from words2 is called a subset of a word in words1 if:All the letters in the word from words2 are present in the word from words1.
And each letter appears at least as many times in the word from words1 as it does in the word from words2.For example:
"wrr" is a subset of "warrior" (because "warrior" has at least 2 'r's and one 'w').
But "wrr" is not a subset of "world" (because "world" doesn’t have 2 'r's).A word from words1 is called universal if:
Every word in words2 is a subset of it.The goal is to return all the universal words from words1.
You are given an array of strings of the same length words.
In one move, you can swap any two even indexed characters or any two odd indexed characters of a string words[i].
Two strings words[i] and words[j] are special-equivalent if after any number of moves, words[i] == words[j].For example, words[i] = "zzxy" and words[j] = "xyzz" are special-equivalent because we may make the moves "zzxy" -> "xzzy" -> "xyzz".
A group of special-equivalent strings from words is a non-empty subset of words such that:
1. Every pair of strings in the group are special equivalent, and
2. The group is the largest size possible (i.e., there is not a string words[i] not in the group such that words[i] is special-equivalent to every string in the group).Return the number of groups of special-equivalent strings from words.