Reconstruct Original Digits from English Solution In C++/Java/Python/Javascript
Problem Description
You are given a string S that contains letters representing scrambled English words for digits (0-9). Your task is to decode the string and return the digits in ascending order.
Examples:
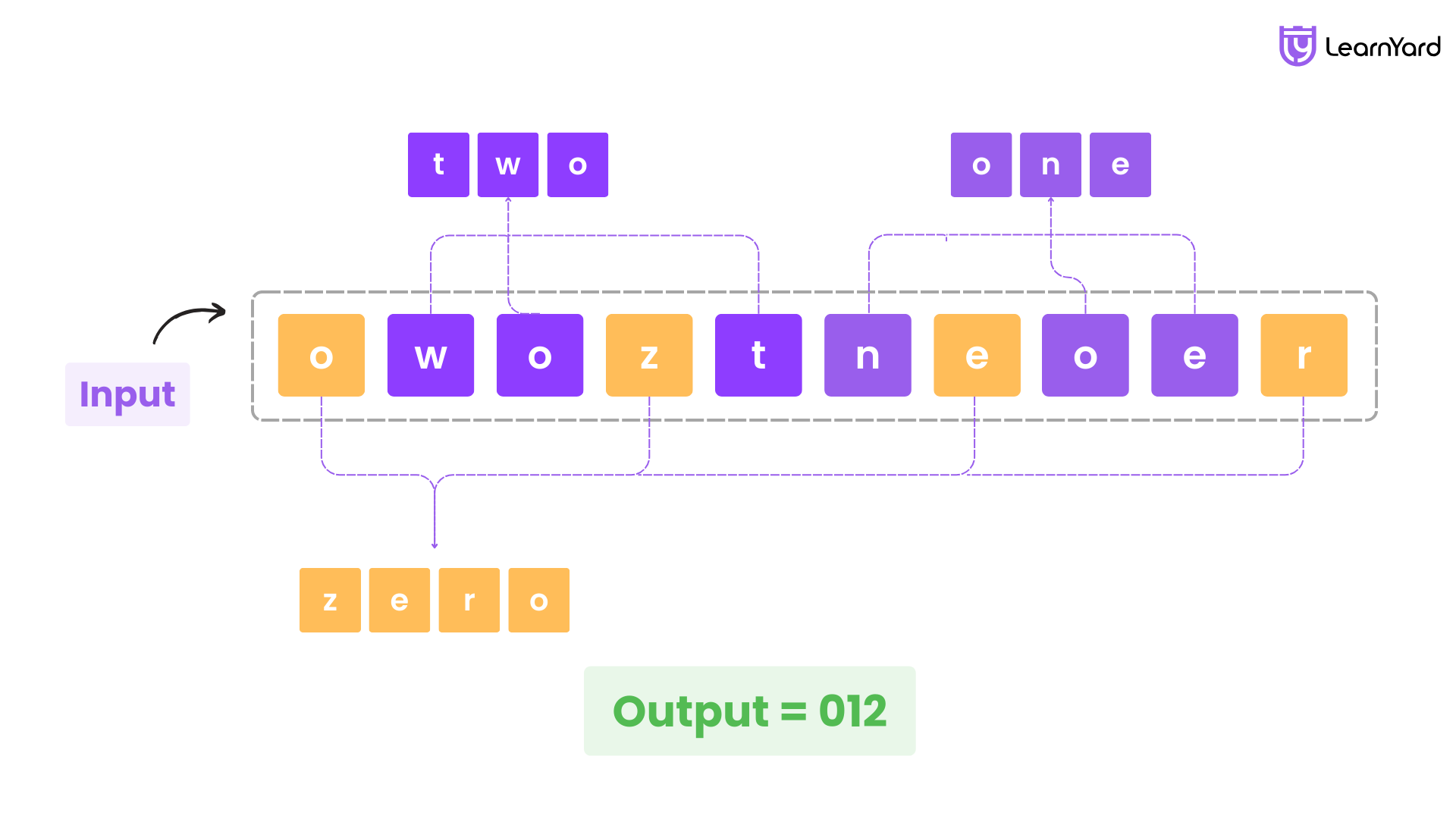
Input: S = “owoztneoer”
Output: “012”
Explanation: string "owoztneoer" contains the letters needed to form the words "zero" (0), "one" (1), and "two" (2), which are sorted to produce the output "012"..
Input: S = “fviefuro”
Output: “45”
Explanation: string "fviefuro" contains the letters needed to form the words "four" (4) and "five" (5), which are sorted to produce the output "45".
Constraints:
1<= S.length <=*10⁵.
S[i] is one of characters [“e”,”g”,”f”’,”i”,”h”,”o”,”n”,”s”’,”r”’,”u”,”t”,”w”,”v”,”x”’,”z”’] S is guaranteed to be valid.
Brute Force Approach
Okay, so here's the thought process:
We need to identify and reconstruct the digits (0-9) that can be formed using the letters present in the given string S.
To identify the digits from the string, we use unique characters that appear specifically in their English representation. For example,
1."z" is unique to "zero”.
2."w" is unique to "two".
3."u" is unique to "four”.
4." x" is unique to "six".
5."g" is unique to "eight".
After finding digits with unique letters, we handle the digits that share letters:
- We use "o" to find "one" as we already checked for "zero," "two," and "four".
- used "h" to find "three" as we already checked for "eight."
- used "f" to find "five" as we already checked for "four."
- use "s" to find "seven" as we already checked for "six."
- We use "i" to find "nine" as we already checked for "five" "six" and "eight."
We process the digits in this order to handle any overlaps correctly. For each unique letter, we check if the digit’s word is in the string. If a digit's word is present, we remove all characters of the corresponding digit’s word and add the digit to the result.
Finally, we sort the digits to ensure they are in ascending order and return the sorted result.
How to do It:
- Identify Unique Characters:
- Each digit (0-9) has a unique characteristic (a letter that appears exclusively in its English representation). For instance:
- "z" uniquely identifies "zero".
- "w" uniquely identifies "two".
- "u" uniquely identifies "four".
- " x" is unique to "six".
- "g" is unique to "eight".
- Process digits based on their unique letter identifiers:
- For each unique digit identifier (like "z" for "zero"), check if it exists in the string S.
- If the word corresponding to the digit is found, remove all characters of the word from the string and append the digit to the result.
- Count and Removal:
Use helper functions to count occurrences of a character, check for the presence of the word, and remove its characters from the string. - Sorting:
After extracting all digits, sort the result string to ensure the digits are in ascending order. - Return Result:
Return the sorted string containing the digits.
Let's walk through an example
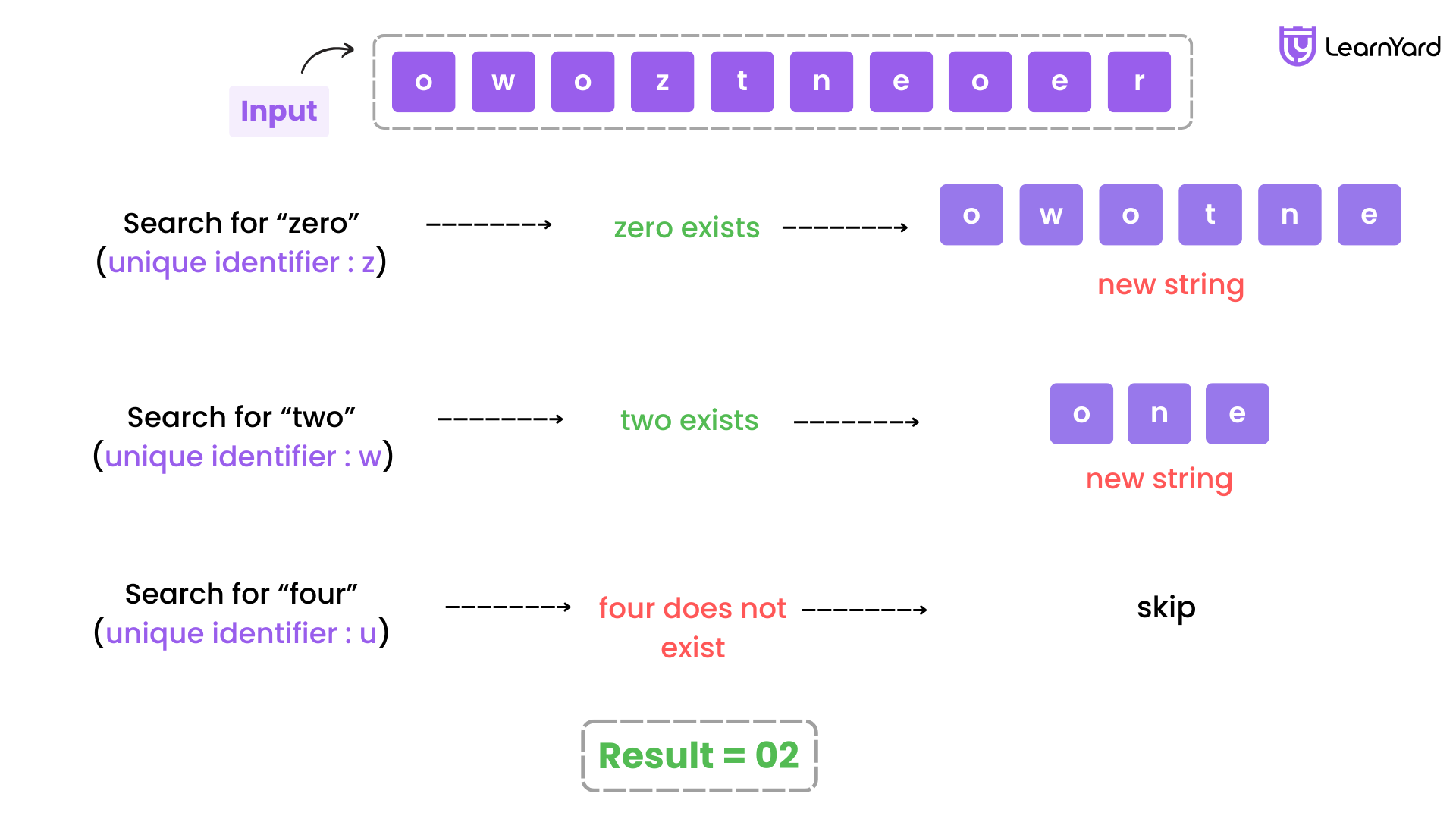
Dry Run for Input:
S = "owoztneoer"
Step-by-Step Execution:
- Initialize result = "".
- Process digits in the order of unique identifiers:
a. "zero" (unique identifier: 'z'):
- Check if "zero" is in S.
- Yes, "zero" exists.
- Remove "zero" → S = "owotne".
- Append "0" to result → result = "0".
b. "two" (unique identifier: 'w'): Check if "two" is in S.
- Yes, "two" exists.
- Remove "two" → S = "one".
- Append "2" to result → result = "02".
c. "four" (unique identifier: 'u'): Check if "four" is in S.
- No, "four" does not exist.
- Skip.
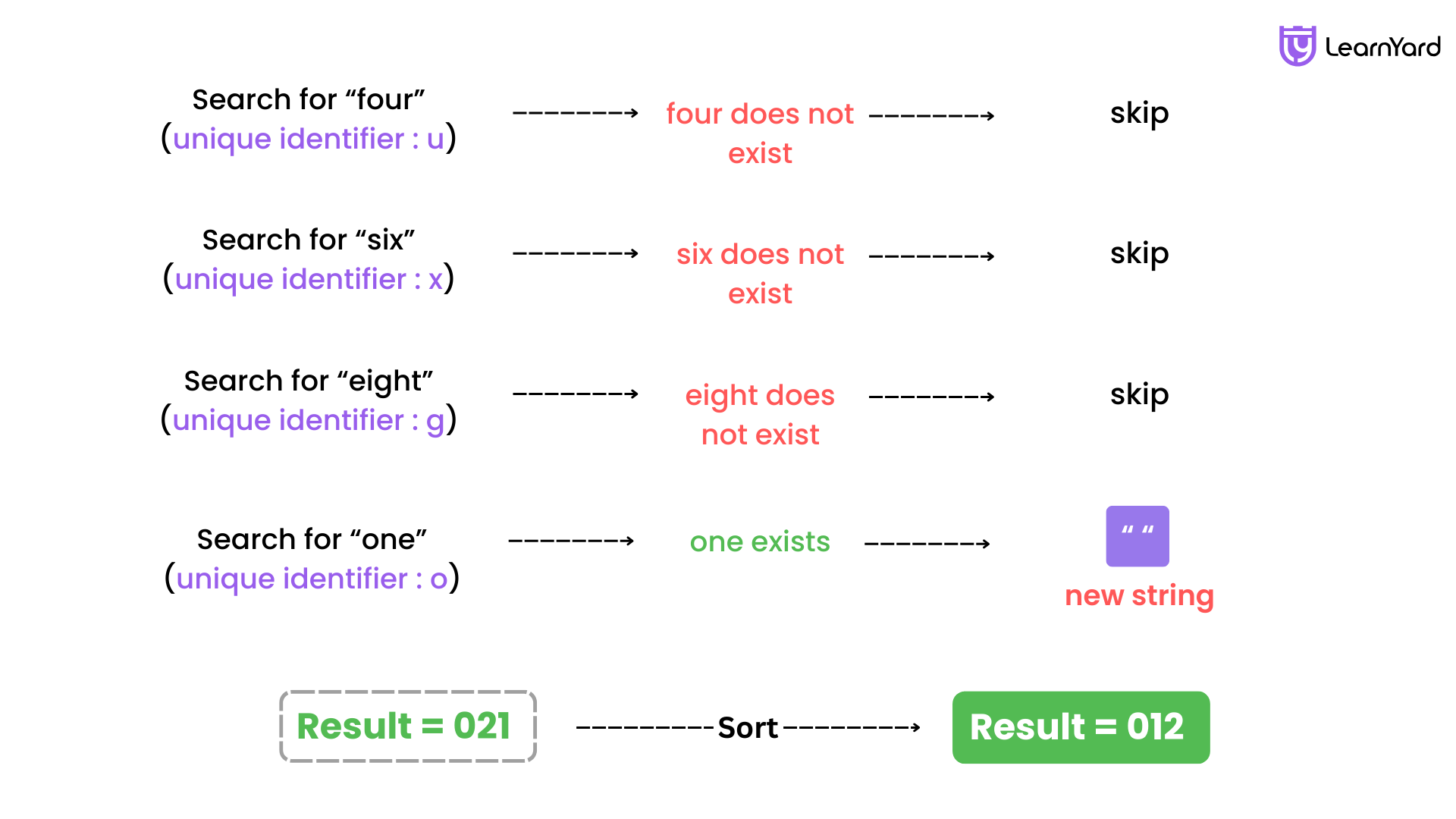
d. "six" (unique identifier: 'x'):Check if "six" is in S.
- No, "six" does not exist.
- Skip.
e. "eight" (unique identifier: 'g'):
- Check if "eight" is in S.
- No, "eight" does not exist.
- Skip.
f. "one" (unique identifier: 'o'):
- Check if "one" is in S.
- Yes, "one" exists.
- Remove "one" → S = "".
- Append "1" to result → result = "021".
g. "three", "five", "seven", "nine":
- None of their unique identifiers ('t', 'f', 's', 'n') exist in S Skip all.
- Sorting:
- result = "012" (already sorted).
- Output:
- Return "012".
How to code it up:
1. Initialize Result: Start with an empty string result.
2. Define Helper Functions:
- Create a function containsWord to check if a word exists in s.
- Create a function removeWord to remove all characters of a word from s.
3. Iterate Over Unique Identifiers:
- Use a specific order of processing digits based on their unique letters:
- "z" for "zero"
- "w" for "two"
- "u" for "four"
- " x" for "six".
- "g" for "eight".
- Append the corresponding digit to result each time the word is found.
4. Sort the Result:
- Use sort to arrange digits in ascending order.
5. Return Result:
- Output the sorted string.
Code Implementation
1. C++ Try on Compiler
class Solution {
private:
// Check if all characters of a word are present in the string
bool containsWord(const std::string& s, const std::string& word) {
for (char c : word) {
if (countChar(s, c) < countChar(word, c)) {
return false;
}
}
return true;
}
// Remove all characters of a word from the string
void removeWord(std::string& s, const std::string& word) {
for (char c : word) {
removeChar(s, c);
}
}
// Count the number of occurrences of a character in a string
int countChar(const std::string& s, char c) {
int count = 0;
for (char ch : s) {
if (ch == c) {
count++;
}
}
return count;
}
// Remove a single occurrence of a character from the string
void removeChar(std::string& s, char c) {
for (size_t i = 0; i < s.size(); ++i) {
if (s[i] == c) {
s.erase(i, 1);
return;
}
}
}
public:
string originalDigits(string s) {
std::string result = "";
// Process digits in the order of unique identifiers
while (containsWord(s, "zero")) {
removeWord(s, "zero");
result += "0";
}
while (containsWord(s, "two")) {
removeWord(s, "two");
result += "2";
}
while (containsWord(s, "four")) {
removeWord(s, "four");
result += "4";
}
while (containsWord(s, "six")) {
removeWord(s, "six");
result += "6";
}
while (containsWord(s, "eight")) {
removeWord(s, "eight");
result += "8";
}
while (containsWord(s, "one")) {
removeWord(s, "one");
result += "1";
}
while (containsWord(s, "three")) {
removeWord(s, "three");
result += "3";
}
while (containsWord(s, "five")) {
removeWord(s, "five");
result += "5";
}
while (containsWord(s, "seven")) {
removeWord(s, "seven");
result += "7";
}
while (containsWord(s, "nine")) {
removeWord(s, "nine");
result += "9";
}
// Sort the result to ensure digits are in ascending order
std::sort(result.begin(), result.end());
return result;
}
};
2. Java Try on Compiler
class Solution {
private boolean containsWord(String s, String word) {
for (char c : word.toCharArray()) {
if (countChar(s, c) < countChar(word, c)) {
return false;
}
}
return true;
}
private int countChar(String s, char c) {
int count = 0;
for (char ch : s.toCharArray()) {
if (ch == c) {
count++;
}
}
return count;
}
private String removeChar(String s, char c) {
int index = s.indexOf(c);
if (index != -1) {
return s.substring(0, index) + s.substring(index + 1);
}
return s;
}
private String removeWord(String s, String word) {
for (char c : word.toCharArray()) {
s = removeChar(s, c);
}
return s;
}
public String originalDigits(String s) {
StringBuilder result = new StringBuilder();
// Process digits in the order of unique identifiers
while (containsWord(s, "zero")) {
s = removeWord(s, "zero");
result.append("0");
}
while (containsWord(s, "two")) {
s = removeWord(s, "two");
result.append("2");
}
while (containsWord(s, "four")) {
s = removeWord(s, "four");
result.append("4");
}
while (containsWord(s, "six")) {
s = removeWord(s, "six");
result.append("6");
}
while (containsWord(s, "eight")) {
s = removeWord(s, "eight");
result.append("8");
}
while (containsWord(s, "one")) {
s = removeWord(s, "one");
result.append("1");
}
while (containsWord(s, "three")) {
s = removeWord(s, "three");
result.append("3");
}
while (containsWord(s, "five")) {
s = removeWord(s, "five");
result.append("5");
}
while (containsWord(s, "seven")) {
s = removeWord(s, "seven");
result.append("7");
}
while (containsWord(s, "nine")) {
s = removeWord(s, "nine");
result.append("9");
}
char[] arr = result.toString().toCharArray();
Arrays.sort(arr);
return new String(arr);
}
}
3. Python Try on Compiler
class Solution(object):
def originalDigits(self, s):
# Helper function to count occurrences of a character in a string
def countChar(s, char):
return s.count(char)
# Helper function to check if all characters of a word are present in the string
def containsWord(s, word):
for char in word:
if countChar(s, char) < word.count(char):
return False
return True
# Helper function to remove all characters of a word from the string
def removeWord(s, word):
s_list = list(s)
for char in word:
if char in s_list:
s_list.remove(char)
return ''.join(s_list)
# Process digits in the order of unique identifiers
result = []
while containsWord(s, "zero"):
s = removeWord(s, "zero")
result.append("0")
while containsWord(s, "two"):
s = removeWord(s, "two")
result.append("2")
while containsWord(s, "four"):
s = removeWord(s, "four")
result.append("4")
while containsWord(s, "six"):
s = removeWord(s, "six")
result.append("6")
while containsWord(s, "eight"):
s = removeWord(s, "eight")
result.append("8")
while containsWord(s, "one"):
s = removeWord(s, "one")
result.append("1")
while containsWord(s, "three"):
s = removeWord(s, "three")
result.append("3")
while containsWord(s, "five"):
s = removeWord(s, "five")
result.append("5")
while containsWord(s, "seven"):
s = removeWord(s, "seven")
result.append("7")
while containsWord(s, "nine"):
s = removeWord(s, "nine")
result.append("9")
# Sort the result to ensure digits are in ascending order
return ''.join(sorted(result))
4. Javascript Try on Compiler
/**
* @param {string} s
* @return {string}
*/
var originalDigits = function(s) {
// Helper function to count occurrences of a character in a string
const countChar = (str, char) => {
let count = 0;
for (let ch of str) {
if (ch === char) count++;
}
return count;
};
// Helper function to check if all characters of a word are present in the string
const containsWord = (str, word) => {
for (let char of word) {
if (countChar(str, char) < countChar(word, char)) {
return false;
}
}
return true;
};
// Helper function to remove all characters of a word from the string
const removeWord = (str, word) => {
let arr = str.split('');
for (let char of word) {
let index = arr.indexOf(char);
if (index !== -1) arr.splice(index, 1);
}
return arr.join('');
};
// Process digits in the order of unique identifiers
let result = "";
while (containsWord(s, "zero")) {
s = removeWord(s, "zero");
result += "0";
}
while (containsWord(s, "two")) {
s = removeWord(s, "two");
result += "2";
}
while (containsWord(s, "four")) {
s = removeWord(s, "four");
result += "4";
}
while (containsWord(s, "six")) {
s = removeWord(s, "six");
result += "6";
}
while (containsWord(s, "eight")) {
s = removeWord(s, "eight");
result += "8";
}
while (containsWord(s, "one")) {
s = removeWord(s, "one");
result += "1";
}
while (containsWord(s, "three")) {
s = removeWord(s, "three");
result += "3";
}
while (containsWord(s, "five")) {
s = removeWord(s, "five");
result += "5";
}
while (containsWord(s, "seven")) {
s = removeWord(s, "seven");
result += "7";
}
while (containsWord(s, "nine")) {
s = removeWord(s, "nine");
result += "9";
}
// Sort the result to ensure digits are in ascending order
return result.split('').sort().join('');
};
Time Complexity: O(n²)
Let's walk through the time complexity:
countChar(s, c): This function iterates through the entire string S once. Therefore, its time complexity is O(|s|), where |s| is the length of the string.
removeChar(s, c): This function also iterates through the string S to find and remove the first occurrence of the character c. In the worst case, it needs to iterate through the entire string. Therefore, its time complexity is also O(|s|).
removeWord(s, word): This function calls removeChar(s, c) for each character in the word. Therefore, its time complexity is O(|word| * |s|), where |word| is the length of the word.
containsWord(s, word): This function calls countChar(s, c) for each character in the word. Therefore, its time complexity is also O(|word| * |s|).
originalDigits(s):
- Contains a series of while loops for each digit (0-9).
- Each while loop calls containsWord(s, word) and removeWord(s, word).
- In the worst case, each while loop can iterate up to the number of occurrences of the corresponding digit in the string.
Overall Time Complexity: The dominant factor in the time complexity is the nested iterations within containsWord and removeWord. Therefore, the overall time complexity of this approach is O(n²), where n is the length of the input string S.
Space Complexity: O(n)
Auxiliary Space Complexity: O(1)
Explanation: The algorithm uses a constant amount of extra space for temporary variables like c, index, etc., in helper functions.
Total Space Complexity: O(n)
Explanation: The input string word itself occupies O(n) space, where n is the length of the string.
So, the total space complexity will be O(n).
Will the Brute Force Approach Work Within the Given Constraints?
Let’s analyze the problem with respect to the given constraints:
For the current solution, the time complexity is O(n²), which is not suitable for n ≤ 10⁵. This means that for each test case, where the length of the string S is at most 10⁵, the solution might not execute within the given time limits.
Since O(n²) results in a maximum of 10¹⁰ operations (for n =10⁵), the solution is not expected to work well for larger test cases. In most competitive programming environments, problems can handle up to 10⁶ operations per test case, meaning that for n ≤ 10⁵, the solution with 10¹⁰ operations is not efficient enough.
When multiple test cases are involved, the total number of operations could easily exceed this limit and approach 10¹⁰ operations.
Thus, while the solution meets the time limits for a single test case O(n²) time complexity poses a risk for Time Limit Exceeded (TLE).
Can we optimize it?
Yes, of course!
We can definitely optimize it—let's do it!
In the previous approach. The frequent use of the countChar function iterates through the entire input string S for each character in the word during the containsWord check. This leads to redundant character counting.
The removeChar function modifies the input string by erasing the character at the found index.
String modifications in many programming languages (like C++) can be expensive.
- When a character is removed from the middle of a string, the remaining characters need to be shifted to fill the gap.
- This shifting operation can be time-consuming, especially for long strings
But how can we do this in an optimized way?
To avoid counting characters multiple times, we can first count the occurrences of all characters in the input string once and store them in a data structure. This allows us to efficiently retrieve the count of any character in constant time, avoiding redundant counting.
Instead of modifying the string, we can simply decrement the character counts in the frequency array as we process each digit. This avoids the costly string manipulation operations (insertions, deletions, and shifting) that are typically associated with string modifications.
By directly constructing the result string in sorted order, we can eliminate the need for a separate sorting step at the end, further improving the efficiency of the algorithm.
We need a data structure that allows us to add or retrieve data in constant time, so we can instantly determine whether an element is present without having to go through the entire list. This significantly improves the efficiency of the process.
Can you think of a technique that allows us to access elements in constant time?
Yes, exactly! Hashing is one of the easiest and most effective ways to speed up this process, especially when we need to perform multiple lookups.
What are Hashmaps?
Hash maps are a powerful data structure that store key-value pairs, allowing for fast access to values using their keys. They are used to determine where to store each pair, enabling average-case time complexities of O(1) for insertion, search, and deletion.
How to do it:
To do this, count the occurrences of each letter in the string S using a Hashmap. Digits are identified uniquely based on specific letters in their English representation, such as 'z' for zero, 'w' for two, 'u' for four, 'x' for six, and 'g' for eight.
After handling these unique digits, the remaining digits are calculated by adjusting for the letters already used.
For instance, 'o' determines one after accounting for zero, two, and four; 't' determines three after removing contributions from two and eight; and similar logic applies to 'f', 's', and 'i' for ,five,seven and nine, respectively.
The result is constructed by repeating each digit according to its count and appending them in ascending order. Finally, the sorted string of digits is returned as the output.
reconstruct-original-digits-from-english - Optimal Animation
Let's walk through an example:
Input: s = "owoztneoer"
Step1: Frequency Map:
create a frequency map to store the count of each character in the input string.['o': 3, 'w': 1, 'z': 1, 't': 1, 'n': 1, 'e': 2, 'r': 1]
Step 2: Digit Counts:
nums Array: This array is used to store the count of each digit (0-9).
nums[0] = 1:The digit '0' is uniquely represented by the letter 'z'.
Since 'z' appears once in the string, nums[0] is set to 1.
nums[2] = 1:The digit '2' is uniquely represented by the letter 'w'.
Since 'w' appears once in the string, nums[2] is set to 1.
nums[4] = 0:The digit '4' is uniquely represented by the letter 'u'.
Since 'u' does not appear in the string, nums[4] remains 0.
nums[6] = 0:The digit '6' is uniquely represented by the letter 'x'.
Since 'x' does not appear in the string, nums[6] remains 0.
nums[8] = 0:
The digit '8' is uniquely represented by the letter 'g'.
Since 'g' does not appear in the string, nums[8] remains 0.
nums[1] = 1:The letter 'o' appears in multiple digits (zero, one, two, four).
nums[1] is calculated as:
- mp['o'] (total occurrences of 'o')
- minus the occurrences of 'o' in "zero", "two", and "four"
= 3 - nums[0] - nums[2] - nums[4] = 3 - 1 - 1 - 0 = 1
nums[3] = 0:
- The letter 'h' appears only in "three".
- nums[3] is calculated as:
- mp['h'] - nums[8] (since 'h' is also present in "eight")
- Since neither 'h' nor 'g' appears in the string, nums[3] remains 0.
nums[5] = 0:
- The letter 'f' appears only in "five".
- nums[5] is calculated as:
- mp['f'] - nums[4] (since 'f' is also present in "four")
- Since neither 'f' nor 'u' appears in the string, nums[5] remains 0.
nums[7] = 0:
- The letter 'v' appears only in "seven".
- nums[7] is calculated as:
- mp['v'] - nums[5]
- Since neither 'v' nor 'f' appears in the string, nums[7] remains 0.
nums[9] = 0:
- The letter 'i' appears in "nine", "five", "six", and "eight".
- nums[9] is calculated as:
- mp['i'] - nums[5] - nums[6] - nums[8]
- Since 'i' does not appear in the string, nums[9] remains 0.
Step 3: Result Construction:
The code iterates through the nums array.
For each digit with a non-zero count:
It appends the digit to the ans string the corresponding number of times.
In this case, nums[0] = 1, nums[1] = 1, and nums[2] = 1.
Therefore, ans becomes "012".
ans = "012" (based on counts in `nums`)
Output: "012"
How to code it up:
1. Frequency Count with Hash Map:
- Use an unordered_map(mp) to store the frequency of each character in the input string S.
- Iterate through the string S and increment the count of each character in the map.
- Unique Character Identification:
- Certain digits have unique characters that are only present in their English representation. These unique characters directly determine the count of their corresponding digits:
- 'z' → "zero" → digit 0
- 'w' → "two" → digit 2
- 'u' → "four" → digit 4
- 'x' → "six" → digit 6
- 'g' → "eight" → digit 8
- Dependent Characters for Other Digits:
- After determining the counts of digits with unique characters, calculate the counts of remaining digits by subtracting contributions from already identified digits:
- 'o' → Present in "one", "zero", "two", and "four". Count for 1 is calculated as:nums[1] = mp['o'] - nums[2] - nums[4] - nums[0];
- 'h' → Present in "three" and "eight". Count for 3 is calculated as:nums[3] = mp['h'] - nums[8];
'f' → Present in "five" and "four". Count for 5 is calculated as:nums[5] = mp['f'] - nums[4];
'v' → Present in "seven" and "five". Count for 7 is calculated as:nums[7] = mp['v'] - nums[5];
'i' → Present in "nine", "five", "six", and "eight". Count for 9 is calculated as:nums[9] = mp['i'] - nums[5] - nums[6] - nums[8];
- Constructing the Result String:
Create a string ans to store the final result.
- For each digit from 0 to 9, append its count to ans as many times as determined in the nums array.
- Use string(nums[i], '0' + i) to repeat the character corresponding to the digit i the required number of times.
- Return the Result:
- Return the constructed string ans, which contains the digits in ascending order.
Code Implementation
1. C++ Try on Compiler
class Solution {
public:
string originalDigits(string s) {
// use Hashmap to map unique letter to digits
unordered_map<char,int>mp;
for(auto it:s)mp[it]++;
//Create a vector nums to store the count of each digit (0 to 9).
vector<int>nums(10);
// Count digits based on unique characters in their English representation:
nums[0] = mp['z'];
nums[2] = mp['w'];
nums[4] = mp['u'];
nums[6] = mp['x'];
nums[8] = mp['g'];
nums[1] = mp['o']-nums[2]-nums[4]-nums[0];
nums[3] = mp['h']-nums[8];
nums[5] = mp['f']-nums[4];
nums[7] = mp['v']-nums[5];
nums[9] = mp['i']-nums[5]-nums[6]-nums[8];
// Initialize an empty string to store the final result.
string ans="";
// Iterate over each digit from 0 to 9.
for(int i=0;i<10;i++){
if(nums[i]!=0)ans+=string(nums[i],'0'+i);
}
return ans;
}
};
2. Java Try on Compiler
class Solution {
public String originalDigits(String s) {
// Use a HashMap to map unique letters to digits
Map<Character, Integer> mp = new HashMap<>();
for (char c : s.toCharArray()) {
mp.put(c, mp.getOrDefault(c, 0) + 1); }
// Create an array to store the count of each digit (0 to 9)
int[] nums = new int[10];
// Count digits based on unique characters in their English representation:
nums[0] = mp.getOrDefault('z', 0);
nums[2] = mp.getOrDefault('w', 0);
nums[4] = mp.getOrDefault('u', 0);
nums[6] = mp.getOrDefault('x', 0);
nums[8] = mp.getOrDefault('g', 0);
nums[1] = mp.getOrDefault('o', 0) - nums[2] - nums[4] - nums[0];
nums[3] = mp.getOrDefault('h', 0) - nums[8];
nums[5] = mp.getOrDefault('f', 0) - nums[4];
nums[7] = mp.getOrDefault('v', 0) - nums[5];
nums[9] = mp.getOrDefault('i', 0) - nums[5] - nums[6] - nums[8];
// Initialize an empty string to store the final result
StringBuilder ans = new StringBuilder();
// Iterate over each digit from 0 to 9
for (int i = 0; i < 10; i++) {
for (int j = 0; j < nums[i]; j++) {
ans.append(i);
}
}
return ans.toString();
}
}
3. Python Try on Compiler
class Solution(object):
def originalDigits(self, s):
from collections import Counter
counts = Counter(s)
# Array to store the count of each digit (0 to 9)
nums = [0] * 10
nums[0] = counts['z']
nums[2] = counts['w']
nums[4] = counts['u']
nums[6] = counts['x']
nums[8] = counts['g']
nums[1] = counts['o'] - nums[0] - nums[2] - nums[4]
nums[3] = counts['h'] - nums[8]
nums[5] = counts['f'] - nums[4]
nums[7] = counts['v'] - nums[5]
nums[9] = counts['i'] - nums[5] - nums[6] - nums[8]
# Build the result string
result = []
for i in range(10):
result.append(str(i) * nums[i])
return ''.join(result)
4. Javascript Try on Compiler
/**
* @param {string} s
* @return {string}
*/
var originalDigits = function(s) {
const map = {};
for (const char of s) {
map[char] = (map[char] || 0) + 1;
}
// Array to store the count of each digit (0 to 9)
const nums = new Array(10).fill(0);
nums[0] = map['z'] || 0;
nums[2] = map['w'] || 0;
nums[4] = map['u'] || 0;
nums[6] = map['x'] || 0;
nums[8] = map['g'] || 0;
nums[1] = (map['o'] || 0) - nums[0] - nums[2] - nums[4];
nums[3] = (map['h'] || 0) - nums[8];
nums[5] = (map['f'] || 0) - nums[4];
nums[7] = (map['v'] || 0) - nums[5];
nums[9] = (map['i'] || 0) - nums[5] - nums[6] - nums[8];
// Build the result string
let ans = '';
for (let i = 0; i < 10; i++) {
ans += i.toString().repeat(nums[i]);
}
return ans;
};
Time Complexity: O(n)
Let's walk through the time complexity:
1. Building the Character Frequency Map:
- The code iterates through each character in the input string s.
- For each character, it checks if it exists in the map and increments its count accordingly.
- This step has a time complexity of O(n), where n is the length of the string S.
2. Counting Digit Occurrences:
- This part involves a series of constant-time operations:
- Accessing and retrieving values from the map for specific characters ('z', 'w', 'u', 'x', 'g', 'o', 'h', 'f', 'v', 'i').
- Performing basic arithmetic operations (subtraction).
- Since these operations are constant time, this step has a time complexity of O(1).
3. Building the Result String:
- The code iterates through the nums array (which has a constant size of 10).
- For each digit, it appends the digit to the ans string nums[i] times.
- This step also has a time complexity of O(1) in the worst case, as the number of digits is constant.
Overall Time Complexity:
The most significant time-consuming part of the algorithm is building the character frequency map in the first step. Therefore, the overall time complexity of the code is O(n), where n is the length of the input string.
Space Complexity: O(n)
Auxiliary Space Complexity: O(1)
Explanation: The hashmap is used to store the frequency of each character in the input string. The size of this map depends on the number of unique characters in the string S. In the worst case, it could store all unique characters in the string, leading to a space complexity of O(1) as there are 26 unique letters in English alphabet.
Nums array stores the count of each digit (0-9). It has a fixed size of 10, so it uses constant space, which is O(1).
Total Space Complexity: O(n)
Explanation: The input string S itself occupies O(n) space, where n is the length of the string.
Learning Tip
Now we have successfully tackled this problem, let's try these similar problems.
You are given an array groupSizes, where groupSizes[i] represents the size of the group that person i belongs to. Each person has a unique ID from 0 to n - 1.
Your task is to divide all people into groups according to their specified sizes and return a list of groups.
- Each person must be in exactly one group.
- Every group must have the correct number of members based on the given groupSizes
You are given a list of logs containing users' actions on LeetCode and an integer k. Each log entry is in the format [userID, time], which means that the user with ID userID performed an action at the minute time.
Understanding the Problem:
- User Active Minutes (UAM):
For each user, the UAM is the number of unique minutes in which they performed actions. Even if a user performs multiple actions in the same minute, that minute is counted only once. - You need to create an array answer of size k, where:
- answer[j] represents the number of users whose UAM equals j (for 1 <= j <= k).
- If no users have a specific UAM, set that position in the array to 0.