Finding the Users Active Minutes Solution In C++/Java/Python/Javascript
Problem Description
You are given an 2D integer matrix logs , where each entry consists of a pair [ID,time]. The ID represents a user who performed an action at a given time (in minutes).
A single user can perform multiple actions at the same minute.
Multiple users can perform actions simultaneously.
Your task is to compute a 1-indexed array answer of size k, where answer[j] represents the number of users who have exactly j unique active minutes (UAM). For example, if answer[2] = 3, it means that three users have exactly 2 unique active minutes.
We will start from the brute force approach and gradually optimize it to improve efficiency in solving the Finding the Users Active Minutes Leetcode solution.
What is a Unique Active Minute (UAM)?
The concept of "Unique Active Minute (UAM)." This refers to the number of different minutes during which a user was active. Even if the same user performs multiple actions in the same minute, that minute is counted only once.
Think of it this way—if you open a webpage at 10:00 AM and refresh it multiple times within that same minute, it’s still counted as 1 unique visit at 10:00 AM.
Real-world Example
Consider a user who logs into the LeetCode platform to practice coding problems. As they interact with the website—solving problems, viewing solutions, and engaging with discussions—the system needs to track how much time the user spends actively participating. For instance, whenever the user is actively solving a problem or reading through a tutorial, we count those minutes as "active minutes." The platform can use this data to track engagement, offer personalized recommendations, or reward users with achievements based on the total time spent actively coding. This is similar to how fitness trackers measure active time, providing a clear picture of how engaged the user is with the platform over a period.
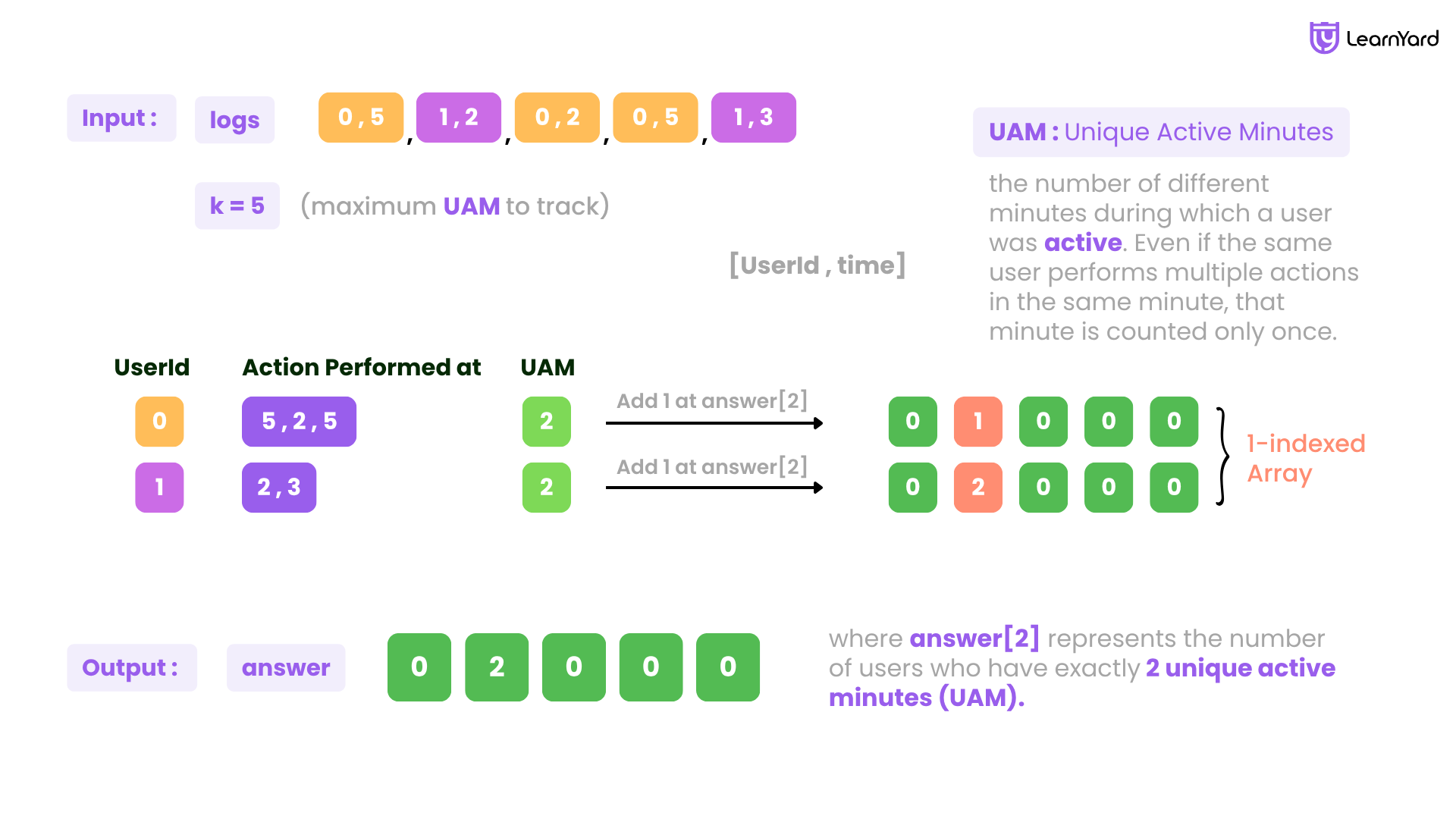
Finding the Users Active Minutes Example
Input: logs = [[0,5], [1,2], [0,2], [0,5], [1,3]], k = 5
Output: [0, 2, 0, 0, 0]
Explanation: UserId: 0, who performed actions three times at minutes [5, 2, 5]. You can see that at minute 5, User ID 0 performed actions twice. We can ignore the duplicate action and count it as a single action at minute 5, resulting in a UAM of 2.
let’s take User ID 1, who performed actions at minutes [2, 3]. Both actions occurred at unique minutes, so there are no duplicates to remove. This results in a UAM of 2 for User ID 1.
Both User ID 0 and User ID 1 have a UAM of 2. Therefore, answer[2] = 2, and all other positions in the array remain 0.
Constraints
1 <= logs.length <= 10^4
0 <= IDi <= 10^9
1 <= timei <= 10^5
k is in the range [The maximum UAM for a user, 10^5].
The goal here is to determine how many users have a specific number of unique active minutes (UAM) based on their activity logs. Since a user can perform multiple actions at the same time, we need to track only the distinct minutes for each user. Once we have this information, we count how many users fall into each UAM category to construct the final answer array. Let’s break it down and find an efficient way to solve the Finding the Users Active Minutes problem.
Brute Force Approach
Intuition
To solve the problem of Finding the Users Active Minutes solution, let’s start with the simplest way to approach it. Imagine we don’t care about efficiency for now and just want to figure out how many unique minutes each user was active. To do this, we could go through every log and manually keep track of the minutes a user was active, one at a time.
For each user, we could collect all their active minutes in a list and then remove duplicates to find the unique active minutes. This would give us the UAM for each user. Once we know the UAM for all users, the next step is to count how many users fall into each UAM category (e.g., how many users have 1 UAM, 2 UAMs, etc.). To do this, we can go through all the users’ UAM values and update an array where each index represents a specific UAM count.
However, there’s a challenge. Storing all the minutes in lists for each user and then removing duplicates for every user could be slow, especially when there are many logs or users. However, as a starting point, this approach is simple to understand and ensures we correctly compute the UAM for all users. It forms the foundation for thinking about better and more efficient methods later. If you're looking for an optimized Finding the Users Active Minutes solution, you might explore using hash table for better efficiency instead of lists.
Approach
Step 1: Initialize Data Structures
We begin by creating two main structures: a mapping to track the minutes each user was active and an output array of size k initialized to zero. The mapping will store each user’s ID as the key and a list of all the minutes they were active as the value. The output array will store the final count of users for each UAM.
This approach forms the foundation of an efficient Finding the Users Active Minutes solution, ensuring we accurately track and categorize user activity.
Step 2: Populate the Mapping
Next, we traverse through the logs matrix. For each entry [ID, time], we check if the user ID already exists in the mapping. If not, we create a new entry for that user, we then add the minute (time) to the user’s list of active minutes. At this stage, duplicates are not removed; we simply collect all minutes for each user.
Step 3: Calculate Unique Active Minutes (UAM)
Once all logs have been processed, we iterate through the mapping. For each user, we take their list of active minutes and remove duplicates to calculate their UAM. This can be done by converting the list of minutes into a collection that only keeps unique values.
Step 4: Update the Output Array
For each user, after calculating their UAM, we update the output array. If a user has j unique active minutes, we increment the value at index j - 1 in the output array (because it’s 1-indexed).
Step 5: Return the Result
Once all users UAM values have been processed, the output array contains the count of users for each UAM. This array is returned as the final result.
Let us understand this with a video,
Finding the Users Active Minutes-Brute-Force-Approach
Dry Run for Finding the Users Active Minutes
Input:
Logs: [[0, 5], [0, 2], [0, 5], [1, 2], [1, 3]] k = 5 (maximum UAM to track)
Step 1: Group Logs by User
We group the logs by user IDs to keep track of the minutes they were active:
- Start with an empty record to store user IDs and the minutes they were active.
- Process each log entry [user ID, minute] one by one:
- For the first log [0, 5]:
- User ID 0 does not exist in the record. Add a new entry for User ID 0 with an empty list.
- Add minute 5 to User ID 0's list.Record: {0: [5]}
- For the second log [0, 2]:
- User ID 0 exists in the record.
- Add minute 2 to User ID 0's list.Record: {0: [5, 2]}
- For the third log [0, 5]:
- User ID 0 exists in the record.
- Add minute 5 to User ID 0's list (duplicates are allowed at this step).Record: {0: [5, 2, 5]}
- For the fourth log [1, 2]:
- User ID 1 does not exist in the record. Add a new entry for User ID 1 with an empty list.
- Add minute 2 to User ID 1's list.Record: {0: [5, 2, 5], 1: [2]}
- For the fifth log [1, 3]:
- User ID 1 exists in the record.
- Add minute 3 to User ID 1's list.Record: {0: [5, 2, 5], 1: [2, 3]}
Step 2: Calculate Unique Active Minutes for Each User
Now, for each user in the record, calculate the number of unique minutes they were active:
- User ID 0:
- Active minutes: [5, 2, 5]
- Remove duplicates: {5, 2}
- Number of unique minutes = 2
- User ID 1:
- Active minutes: [2, 3]
- Remove duplicates: {2, 3}
- Number of unique minutes = 2
Unique Active Minutes (UAM): User 0 → 2 User 1 → 2
Step 3: Count Users by UAM
Create a list to count how many users have a specific number of unique active minutes. This list will have k slots, one for each possible UAM value (1 to k):
- Start with an empty list of size k, initialized to zero: counts = [0, 0, 0, 0, 0]
- For each user, update the count of their UAM:
- User 0 has 2 unique minutes → Increment the second slot (counts[1] because it’s 1-indexed): counts = [0, 1, 0, 0, 0]
- User 1 has 2 unique minutes → Increment the second slot again: counts = [0, 2, 0, 0, 0]
Step 4: Final Output
The counts list now contains the results for each UAM:
- counts[0] = 0: No users have 1 unique active minute.
- counts[1] = 2: Two users have 2 unique active minutes.
- counts[2] = 0: No users have 3 unique active minutes.
- counts[3] = 0: No users have 4 unique active minutes.
- counts[4] = 0: No users have 5 unique active minutes.
Final Result:
[0, 2, 0, 0, 0]
Code for All Languages
C++
//Finding the Users Active Minutes solution in cpp
vector<int> findingUsersActiveMinutes(vector<vector<int>>& logs, int k) {
unordered_map<int, vector<int>> userMinutes; // map to store all minutes for each user
vector<int> result(k, 0); // Result array of size k initialized to zero
// Traverse through logs and collect all active minutes for each user
for (auto& log : logs) {
userMinutes[log[0]].push_back(log[1]);
}
// For each user, remove duplicates and calculate their unique active minutes (UAM)
for (auto& entry : userMinutes) {
sort(entry.second.begin(), entry.second.end());
entry.second.erase(unique(entry.second.begin(), entry.second.end()), entry.second.end()); // Remove duplicates
int uam = entry.second.size(); // The number of unique active minutes for this user
if (uam <= k) {
result[uam - 1]++; // Increment the count of users with this UAM
}
}
return result;
}Java
//Finding the Users Active Minutes solution in java
public class UAMCalculator {
public static List<Integer> findingUsersActiveMinutes(int[][] logs, int k) {
Map<Integer, List<Integer>> userMinutes = new HashMap<>(); // Map to store all minutes for each user
List<Integer> result = new ArrayList<>(Collections.nCopies(k, 0)); // Result list initialized to zero
// Traverse through logs to populate the userMinutes map
for (int[] log : logs) {
userMinutes.putIfAbsent(log[0], new ArrayList<>());
userMinutes.get(log[0]).add(log[1]); // Collect all active minutes for the user
}
// For each user, remove duplicates and calculate their unique active minutes (UAM)
for (List<Integer> minutes : userMinutes.values()) {
Set<Integer> uniqueMinutes = new HashSet<>(minutes); // Remove duplicates by converting to set
int uam = uniqueMinutes.size(); // The number of unique active minutes for this user
if (uam <= k) {
result.set(uam - 1, result.get(uam - 1) + 1); // Increment the count of users with this UAM
}
}
return result;
}Python
//Finding the Users Active Minutes solution in python
def finding_users_active_minutes(logs, k):
from collections import defaultdict
user_minutes = defaultdict(list) # Dictionary to store all minutes for each user
# Traverse through logs to populate the user_minutes dictionary
for user_id, minute in logs:
user_minutes[user_id].append(minute) # Collect all active minutes for the user
result = [0] * k # Result list initialized to zero
# For each user, remove duplicates and calculate their unique active minutes (UAM)
for minutes in user_minutes.values():
unique_minutes = set(minutes) # Remove duplicates by converting to set
uam = len(unique_minutes) # The number of unique active minutes for this user
if uam <= k:
result[uam - 1] += 1 # Increment the count of users with this UAM
return resultJavascript
//Finding the Users Active Minutes solution in javaScript
function findingUsersActiveMinutes(logs, k) {
let userMinutes = new Map(); // Map to store unique minutes for each user
// Traverse through logs to populate the userMinutes map
for (let [user, minute] of logs) {
if (!userMinutes.has(user)) {
userMinutes.set(user, new Set());
}
userMinutes.get(user).add(minute); // Insert the minute into the set for the user
}
let result = new Array(k).fill(0); // Result array initialized to zero
// For each user, calculate their unique active minutes (UAM) and update the result array
for (let minutes of userMinutes.values()) {
let uam = minutes.size; // The number of unique minutes for this user
if (uam <= k) {
result[uam - 1]++; // Increment the count of users with this UAM
}
}
return result;
}Complexity Analysis of the Problem
Time Complexity: O(n * m)
The time complexity of this approach is O(n * m). In the first phase, we iterate through all the n logs to populate the data structure. For each log entry, we perform an insertion operation into a set, which takes constant time on average. Since we're iterating over all n logs, this phase contributes O(n) to the time complexity.
In the second phase, we process each user’s list of unique minutes. The size of each user's list can be up to m minutes, where m is the maximum number of unique active minutes any user can have. We perform constant-time operations for each unique minute, and since we process each user’s set, the total time complexity is influenced by both the number of users and the number of unique minutes. Therefore, the overall time complexity is O(n * m), reflecting the need to handle both the number of logs and the number of unique minutes efficiently.
Space Complexity: O(n)
In this approach, the primary contributor to space complexity is the mapping structure that associates each user with their set of unique active minutes. For each log entry, the user ID is mapped to a collection of their distinct activity times. In the worst-case scenario, where all n log entries correspond to different users and different timestamps, this mapping will store n users, each with their unique activity time. This leads to O(n) space usage. Even if multiple logs belong to the same user, only unique activity times are stored, ensuring that space usage grows linearly with the number of logs in the worst case.
Additionally, the approach uses an array of size k to store the count of users based on their Unique Active Minutes (UAM). This array has a fixed size, determined by k, which is independent of the number of log entries n. Since k is a constant relative to the input size, it contributes O(k) space. However, because k does not scale with the input size, it is considered negligible in the overall space analysis. Therefore, the total space complexity is dominated by the user-to-activity mapping, resulting in an overall O(n) space complexity.
Why isn't the result array included in space complexity?
The space allocated for storing the result is not included in the space complexity because it is necessary for returning the final output of the function. When analyzing space complexity, we focus on the extra memory used during computation, excluding the memory required for the result itself. Since this output is essential and must be returned by the function, it doesn't count as additional space. Additionally, the size of this output is based on k, which is typically a fixed value and does not scale with the size of the input, making its impact on space complexity minimal.
Bridge between Brute force and Optimized Approach
The brute force approach gathers all user activities in collections and removes duplicates afterward, resulting in higher time complexity due to the extra step of duplicate removal. The optimized approach, however, uses collections that automatically store only unique values, eliminating the need for post-processing. This reduces unnecessary operations and improves overall efficiency. Furthermore, using mapping structures for direct lookups enhances performance by allowing faster data access, making it a more effective for Finding the Users Active Minutes.
Optimized Approach
Intuition
The intuition behind the optimized approach is to avoid the need for post-processing, such as removing duplicates, by leveraging sets directly during the data collection phase. Instead of storing all the activity minutes in a list for each user, we store only the unique minutes using a set. This ensures that each user's active minutes are automatically deduplicated as we process the logs. Additionally, by using a map to track the unique minutes per user, we allow for fast lookups and efficient storage. This approach minimizes redundant operations, leading to an overall improvement in time complexity. Finally, once the data is collected, the result is computed by simply counting the number of users in each unique active minute (UAM) category, making the process more streamlined and efficient.
In various programming languages, we can use specific implementations like unordered sets in C++, hash sets in Java, sets in Python, or Set objects in JavaScript to achieve the same behavior.
How does a set work?
A set is a collection of unique elements, meaning it does not allow duplicate values. When you add an item to a set, it checks if the item already exists. If it does, it won't be added again; if not, the item is inserted. This ensures that all elements in the set are distinct.
The underlying structure often uses hashing or other algorithms to ensure that adding, removing, and checking for existence of elements are done efficiently, typically in constant time (O(1)) on average. This makes sets ideal for scenarios where uniqueness is important and where quick lookups are needed.
Approach
Step 1: Initialize Data Structures
We start by creating two main structures:
- A map to track the unique minutes each user was active. This map will use the user's ID as the key, and each key will point to an unordered set of minutes (since sets inherently handle uniqueness).
- A result array of size k, initialized to zero, to store the count of users for each possible UAM (Unique Active Minutes).
Step 2: Populate the Mapping
We then loop through the logs, and for each entry, we check the user ID. If the user ID doesn't already exist in the map, we create a new entry for that user. Then, we insert the minute (time) from the log into the set of active minutes for that user. This ensures that duplicate minutes for the same user are automatically handled by the set.
Step 3: Calculate Unique Active Minutes (UAM)
Once all the logs are processed, we traverse the map to calculate the UAM for each user. The UAM is simply the size of the set of minutes for each user, as the set only contains unique minutes.
Step 4: Update the Output Array
For each user, after calculating their UAM, we update the output array. If a user has j unique active minutes, we increment the value at index j-1 in the result array, because the UAM values are 1-indexed. This keeps track of how many users have a specific UAM.
Step 5: Return the Result
Finally, we return the result array, which contains the count of users for each UAM.
Let us understand this with a video,
Finding the Users Active Minutes-Optimal-Approach
Dry Run for Finding the Users Active Minutes
Input:
Logs: [[0, 5], [0, 2], [0, 5], [1, 2], [1, 3]]
k = 5 (maximum UAM to track)
Step 1: Group Logs by User
We group the logs by user IDs to keep track of the minutes they were active:
- Start with an empty record to store user IDs and the minutes they were active.
Process each log entry [user ID, minute] one by one:
- Log entry [0, 5]:
- User ID 0 does not exist in the record.
- Add a new entry for User ID 0 with an empty list.
- Add minute 5 to User ID 0's list.
Record: {0: [5]}
- Log entry [0, 2]:
- User ID 0 exists in the record.
- Add minute 2 to User ID 0's list.
Record: {0: [5, 2]}
- Log entry [0, 5]:
- User ID 0 exists in the record.
- Attempt to insert 5 (already exists, no change)
Record: {0: [5, 2]}
- Log entry [1, 2]:
- User ID 1 does not exist in the record.
- Add a new entry for User ID 1 with an empty list.
- Add minute 2 to User ID 1's list.
Record: {0: [5, 2], 1: [2]}
- Log entry [1, 3]:
- User ID 1 exists in the record.
- Add minute 3 to User ID 1's list.
Record: {0: [5, 2], 1: [2, 3]}
Step 2: Count Users by Unique Active Minutes (UAM) Iterate through userMinutes:
1. User 0's Entry: [5, 2]
Unique minutes are detected: 5, 2
Count of unique minutes: 2
Action: Increment result[1] (index for 2 unique minutes)
Current result: [0, 1, 0, 0, 0]
- User 1's Entry: [2, 3]
Unique minutes are detected: 2, 3
Count of unique minutes: 2
Action: Increment result[1] (index for 2 unique minutes)
Updated result: [0, 2, 0, 0, 0]
Breakdown of the Process:
- Both User 0 and User 1 have 2 unique minutes
- For each user, the count at index 1 (representing 2 unique minutes) is incremented
- First, User 0 increments result[1] to [0, 1, 0, 0, 0]
- Then, User 1 further increments result[1] to [0, 2, 0, 0, 0]
Final Output: [0, 2, 0, 0, 0]
Code for All Languages
C++
//Finding the Users Active Minutes solution in cpp
vector<int> findingUsersActiveMinutes(vector<vector<int>>& logs, int k) {
unordered_map<int, unordered_set<int>> userMinutes;
vector<int> result(k, 0);
// Step 1: Populate the mapping (user -> unique minutes)
for (auto& log : logs) {
int user = log[0], time = log[1];
userMinutes[user].insert(time);
}
// Step 2: Count users by their Unique Active Minutes (UAM)
for (auto& [user, minutes] : userMinutes) {
int uam = minutes.size();
if (uam <= k) result[uam - 1]++;
}
return result;
}Java
//Finding the Users Active Minutes solution in java
public int[] findingUsersActiveMinutes(int[][] logs, int k) {
Map<Integer, Set<Integer>> userMinutes = new HashMap<>();
int[] result = new int[k];
// Step 1: Populate the mapping (user -> unique minutes)
for (int[] log : logs) {
int user = log[0], time = log[1];
userMinutes.computeIfAbsent(user, x -> new HashSet<>()).add(time);
}
// Step 2: Count users by their Unique Active Minutes (UAM)
for (Set<Integer> minutes : userMinutes.values()) {
int uam = minutes.size();
if (uam <= k) result[uam - 1]++;
}
return result;
}
Python
#Finding the Users Active Minutes solution in python
def findingUsersActiveMinutes(logs, k):
user_minutes = defaultdict(set)
result = [0] * k
# Step 1: Populate the mapping (user -> unique minutes)
for user, time in logs:
user_minutes[user].add(time)
# Step 2: Count users by their Unique Active Minutes (UAM)
for minutes in user_minutes.values():
uam = len(minutes)
if uam <= k:
result[uam - 1] += 1
return resultJavascript
//Finding the Users Active Minutes solution in javaScript
function findingUsersActiveMinutes(logs, k) {
let userMinutes = new Map();
let result = new Array(k).fill(0);
// Step 1: Populate the mapping (user -> unique minutes)
for (let [user, time] of logs) {
if (!userMinutes.has(user)) userMinutes.set(user, new Set());
userMinutes.get(user).add(time);
}
// Step 2: Count users by their Unique Active Minutes (UAM)
for (let minutes of userMinutes.values()) {
let uam = minutes.size;
if (uam <= k) result[uam - 1]++;
}
return result;
}Complexity Analysis of the problem
Time Complexity: O(n)
In this optimized approach, the first step is to process the logs, where we insert the active minutes for each user into a data structure. For each log entry, inserting a minute into the set associated with a user takes constant time, O(1), on average. This operation ensures that duplicates are eliminated during the data collection phase, avoiding the need for any post-processing. Since we iterate over each log exactly once and perform constant-time insertions, this step contributes O(n) to the time complexity, where n is the number of logs.
After processing all logs, the next step is to count the number of users with each number of unique active minutes. This involves iterating through the map of unique active minutes for each user. For each user, we check the size of their active minutes set, which is a constant-time operation, O(1). Since there are at most n unique users, the total time spent here is proportional to the number of unique users, which is O(n). Combining both steps, the overall time complexity remains O(n), where n is the number of logs.
You might be wondering if the time complexity should be O(n * m) since we're iterating through a 2D array. However, each log only contains 2 columns (user ID and minute), making m a constant. Because of this, the time complexity simplifies to O(n).
Space Complexity: O(n)
The space complexity is primarily driven by the storage requirements of the data structures. First, we use a map to store each user and their corresponding set of unique active minutes. In the worst case, where each log belongs to a different user and each user has unique active minutes, the space required to store the map is proportional to the number of logs, O(n). The set for each user also takes space proportional to the number of unique active minutes for that user. Hence, the total space used by the map and sets is O(n) in the worst case.
Note: We are not including the space of the array where the result will be stored, as it is mandatory to return an array.
Similar Problems
Now we have successfully tackled this problem, let's try these similar problems.
Number of Good Pairs
Count pairs of indices with equal elements.
Given a list of strings words and a string pattern, return a list of words[i] that match pattern.