Substring with Concatenation of All Words
Problem Description
You are given a string s and an array of strings words. All the strings of words are of the same length.
A concatenated string is a string that exactly contains all the strings of any permutation of words concatenated.
For example, if words = ["ab","cd","ef"], then "abcdef", "abefcd", "cdabef", "cdefab", "efabcd", and "efcdab" are all concatenated strings. "acdbef" is not a concatenated string because it is not the concatenation of any permutation of words.
Return an array of the starting indices of all the concatenated substrings in s. You can return the answer in any order.
What is a Substring?
A substring is a contiguous sequence of characters within a string. For a string s = "abcdef", a substring must consist of characters that appear consecutively in the original string.
Single-character substrings:
"a", "b", "c", "d", "e", "f"
Two-character substrings:
"ab", "bc", "cd", "de", "ef"
Three-character substrings:
"abc", "bcd", "cde", "def"
Four-character substrings:
"abcd", "bcde", "cdef"
Five-character substrings:
"abcde", "bcdef"
Six-character substring (the whole string itself):
"abcdef"
Invalid Substrings (Non-contiguous sequences):
"acd", "ace", "bac", etc., are not substrings because they skip over characters or mix up the order of characters in s.
What is a Permutation ?
In the given problem statement, a permutation refers to any possible ordering of all the words in the array of words.
words[] = ["foo", "bar"]
Permutations of words:
- "foobar" (["foo", "bar"])
- "barfoo" (["bar", "foo"])
Example
Input: s = "barfoothefoobarman", words = ["foo","bar"]
Output: [0,9]
Explanation: The substring starting at 0 is "barfoo". It is the concatenation of ["bar", "foo"] which is a permutation of words.
The substring starting at 9 is "foobar". It is the concatenation of ["foo", "bar"] which is a permutation of words.
Input: s = "wordgoodgoodgoodbestword", words = ["word","good","best","word"]
Output: []
Explanation: There is no concatenated substring.
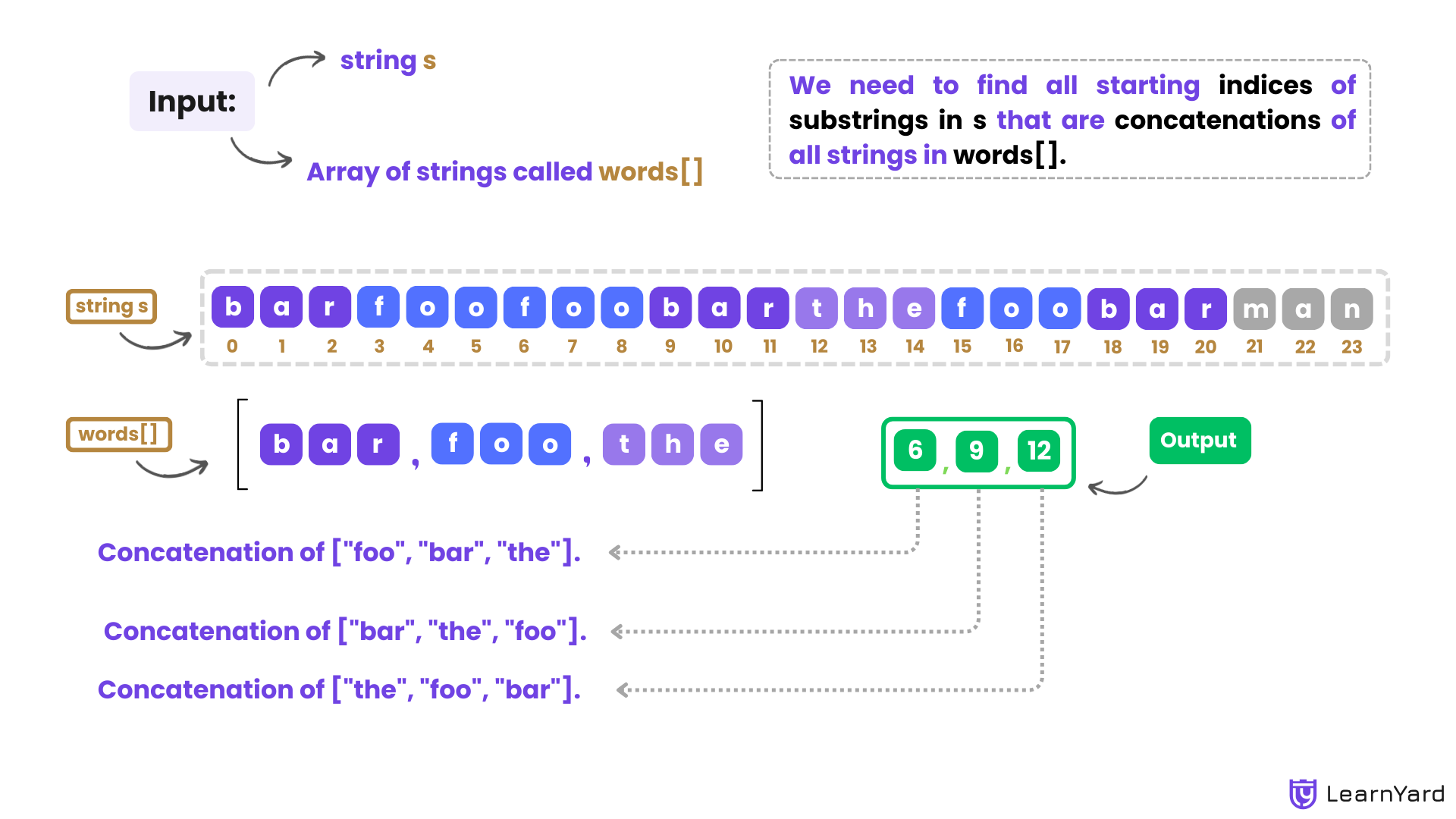
Input: s = "barfoofoobarthefoobarman", words = ["bar","foo","the"]
Output: [6,9,12]
Explanation: The substring starting at 6 is "foobarthe". It is the concatenation of ["foo", "bar", "the"].
The substring starting at 9 is "barthefoo". It is the concatenation of ["bar", "the", "foo"].
The substring starting at 12 is "thefoobar". It is the concatenation of ["the", "foo", "bar"].
Constraints
- 1 <= s.length <= 10^4
- 1 <= words.length <= 5000
- 1 <= words[i].length <= 30
- s and words[i] consist of lowercase English letters.
The problem statement involves solving with different approaches such as using String Matching, Sliding Window/Two pointer, etc. Each approach has its own benefits and challenges in terms of how fast it works and how much memory it uses.
Brute Force Approach
Intuition
We are given a String s and an array words[] of Strings with all the strings of the same length inside it.
The brute force approach that we imagine is by directly generating all permutations of the given list of words and checking every substring of s to see if it matches any of these permutations.
How to generate Permutations of an array of Strings ?
To generate every possible permutation of an array of strings, we can use backtracking. This approach systematically explores all possible arrangements by swapping elements and backtracking after recursive calls.
Algorithm:
- Fix One Element:
Start with the first element and consider it fixed. - Recurse on Remaining Elements:
For each position in the array, recursively generate permutations of the remaining elements. - Backtrack:
Undo swaps to restore the original array state and explore other possibilities. - Base Case:
When the recursion reaches the end of the array (all elements are fixed), store the current arrangement as a valid permutation.
Input:
words = ["foo", "bar", "baz"]
Output:
Permutations generated:
- ["foo", "bar", "baz"]
- ["foo", "baz", "bar"]
- ["bar", "foo", "baz"]
- ["bar", "baz", "foo"]
- ["baz", "foo", "bar"]
- ["baz", "bar", "foo"]
Next, we check every possible substring of s of length equal to the total length of all words combined.
- Let total_length = len of words array * length of each string of the array.
- For each starting index i in s, extract the substring s[i:i+total_length] and check if it matches any of the permutations generated in step 1.
If a substring matches a permutation, store the starting index i in the result.
Dry-Run
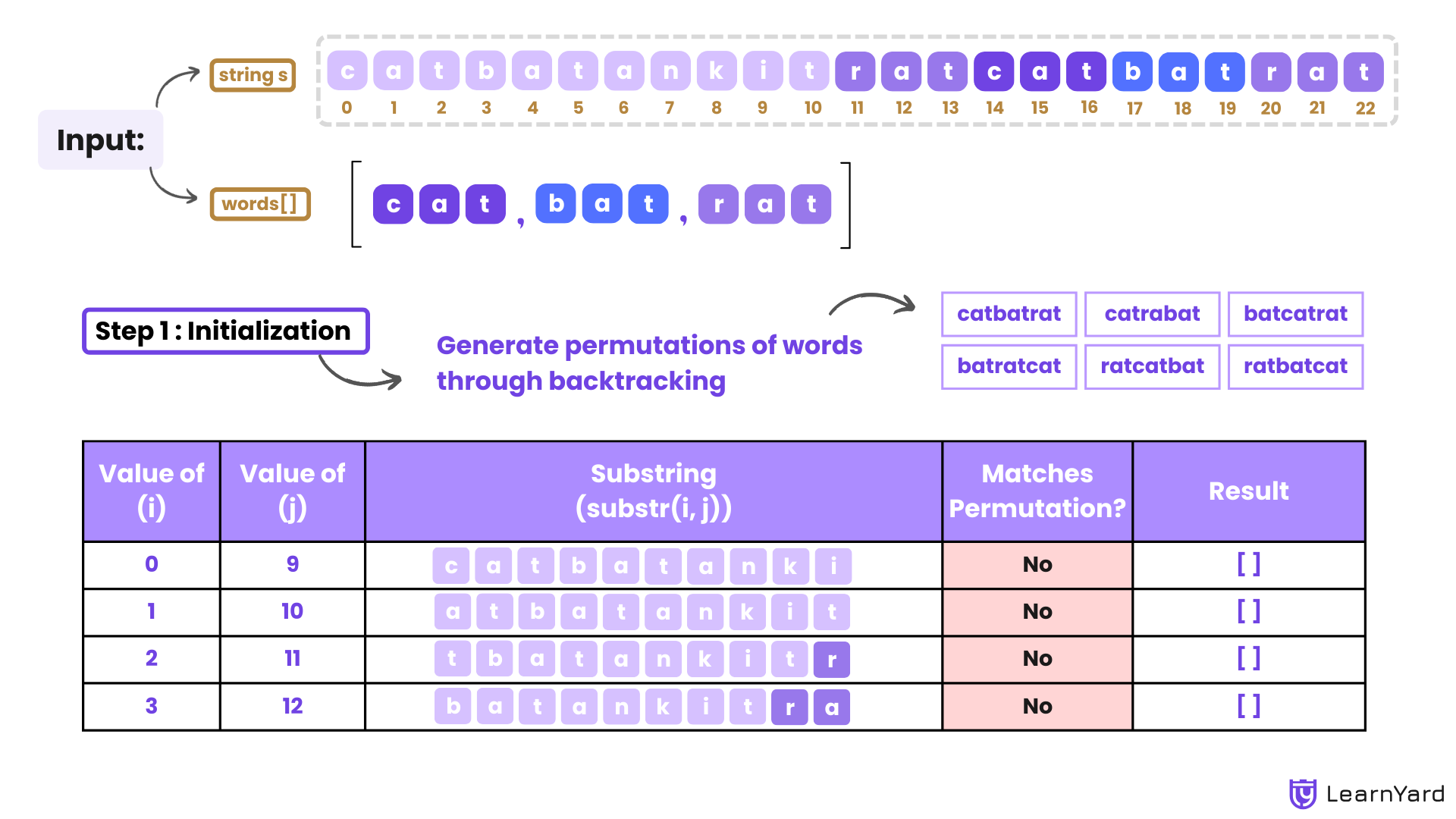
String s = "catbatankitratcatbatrat";
String[] words = {"cat", "bat", "rat"};
Answer: [11,14]
Explanation: "ratcatbat" and "catbatrat" is a permutation of words which occurs in indices 11 and 14.
Step 1: Initialization
- Words: ["cat", "bat", "rat"]
- Word Length: 3 (all words have the same length).
- Total Length of Concatenated Substring: 3×3=9
- Permutations of words:
- "catbatrat"
- "catrabat"
- "batcatrat"
- "batratcat"
- "ratcatbat"
- "ratbatcat"
Iterations:
- i = 0:
- Substring: s[0:9] = "catbatank"
- Matches no permutation.
- i = 1:
- Substring: s[1:10] = "atbatanki"
- Matches no permutation.
- i = 2:
- Substring: s[2:11] = "tbatankit"
- Matches no permutation.
- i = 3:
- Substring: s[3:12] = "batankitr"
- Matches no permutation.
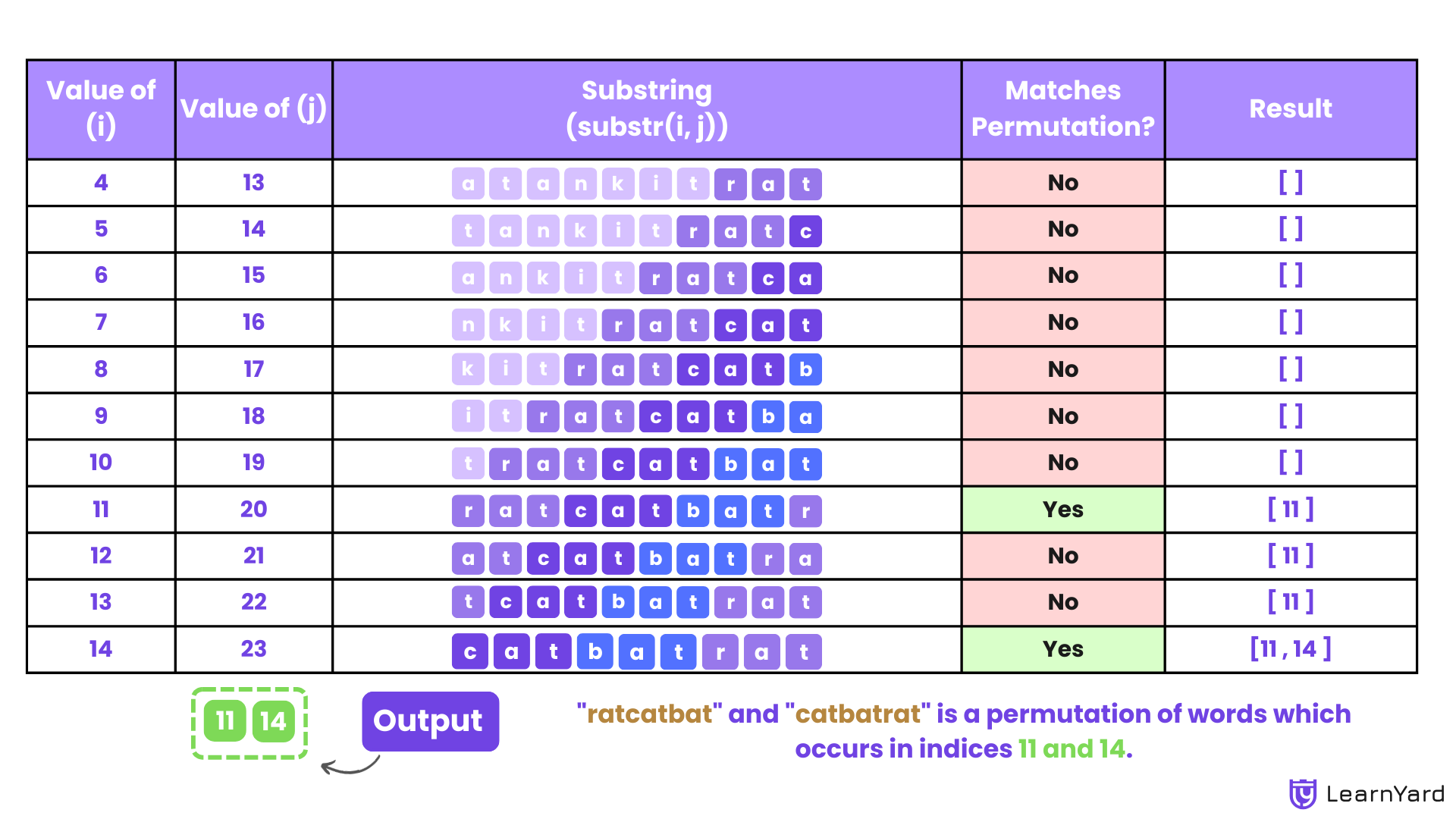
- i = 4:
- Substring: s[4:13] = "atankitrat"
- Matches no permutation.
- i = 5:
- Substring: s[5:14] = "tankitrat"
- Matches no permutation.
- i = 6:
- Substring: s[6:15] = "ankitratc"
- Matches no permutation.
- i = 7:
- Substring: s[7:16] = "nkitratca"
- Matches no permutation.
- i = 8:
- Substring: s[8:17] = "kitratcat"
- Matches no permutation.
- i = 9:
- Substring: s[9:18] = "itratcatb"
- Matches no permutation.
- i = 10:
- Substring: s[10:19] = "tratcatba"
- Matches no permutation.
- i = 11:
- Substring: s[11:20] = "ratcatbat"
- Matches "ratcatbat" (Permutation #5).
Add index 11 to the result list.
- i = 12:
- Substring: s[12:21] = "atcatbatr"
- Matches no permutation.
- i = 13:
- Substring: s[13:22] = "tcatbatr"
- Matches no permutation.
- i = 14:
- Substring: s[14:23] = "catbatrat"
- Matches "catbatrat" (Permutation #1).
Add index 14 to the result list.
Step 3: Result:
The matching starting indices are [11, 14].
Brute Force Code in all Languages
1. C++ Try on Compiler
class Solution {
public:
void generatePermutations(vector<string>& words, int index, vector<string>& permutations) {
if (index == words.size()) {
string concatenated;
for (const string& word : words) {
concatenated += word;
}
permutations.push_back(concatenated);
return;
}
for (int i = index; i < words.size(); i++) {
swap(words[index], words[i]);
generatePermutations(words, index + 1, permutations);
swap(words[index], words[i]); // backtrack
}
}
// Helper function to check if a substring matches any permutation
bool matchesAnyPermutation(const string& s, const vector<string>& permutations) {
for (const string& permutation : permutations) {
if (s == permutation) {
return true;
}
}
return false;
}
// Function to find all starting indices of substrings in `s` that are concatenations of all words in `words`
vector<int> findSubstring(string s, vector<string>& words) {
vector<int> result;
// Return empty result if input is invalid
if (s.empty() || words.empty()) {
return result;
}
// Generate all permutations of words
vector<string> permutations;
generatePermutations(words, 0, permutations);
// Total length of concatenated string
int wordLength = words[0].length();
int totalLength = wordLength * words.size();
// Slide through the string and check substrings
for (int i = 0; i <= s.length() - totalLength; i++) {
string substring = s.substr(i, totalLength);
if (matchesAnyPermutation(substring, permutations)) {
result.push_back(i);
}
}
return result;
}
};2. Java Try on Compiler
class Solution {
public static List<Integer> findSubstring(String s, String[] words) {
List<Integer> result = new ArrayList<>();
// Return empty list if inputs are null or invalid
if (s == null || words == null || words.length == 0) {
return result;
}
// Step 1: Generate all permutations of words
List<String> permutations = new ArrayList<>();
generatePermutations(words, 0, permutations);
// Step 2: Total length of concatenated string
int wordLength = words[0].length();
int totalLength = wordLength * words.length;
// Step 3: Slide through the string and check substrings
for (int i = 0; i <= s.length() - totalLength; i++) {
String substring = s.substring(i, i + totalLength);
if (permutations.contains(substring)) {
result.add(i);
}
}
return result;
}
// Helper method to generate permutations of words
private static void generatePermutations(String[] words, int index, List<String> permutations) {
if (index == words.length) {
permutations.add(String.join("", words));
return;
}
for (int i = index; i < words.length; i++) {
swap(words, i, index);
generatePermutations(words, index + 1, permutations);
swap(words, i, index); // backtrack
}
}
// Helper method to swap elements in the array
private static void swap(String[] words, int i, int j) {
String temp = words[i];
words[i] = words[j];
words[j] = temp;
}
}3. Python Try on Compiler
class Solution:
def findSubstring(self, s: str, words: List[str]) -> List[int]:
result = []
# Return empty result if input is invalid
if not s or not words:
return result
# Step 1: Generate all permutations of words manually
permutations = set()
def generate_permutations(arr, start):
if start == len(arr):
permutations.add(''.join(arr))
return
for i in range(start, len(arr)):
arr[start], arr[i] = arr[i], arr[start] # Swap
generate_permutations(arr, start + 1)
arr[start], arr[i] = arr[i], arr[start] # Swap back
generate_permutations(words, 0)
# Step 2: Total length of concatenated string
word_length = len(words[0])
total_length = word_length * len(words)
# Step 3: Slide through the string and check substrings
for i in range(len(s) - total_length + 1):
substring = s[i:i + total_length]
if substring in permutations:
result.append(i)
return result4. JavaScript Try on Compiler
/**
* @param {string} s
* @param {string[]} words
* @return {number[]}
*/
var findSubstring = function(s, words) {
let result = [];
// Return empty result if input is invalid
if (!s || !words || words.length === 0) return result;
// Step 1: Generate all permutations of words
let permutations = new Set();
function generatePermutations(arr, start) {
if (start === arr.length) {
permutations.add(arr.join(''));
return;
}
for (let i = start; i < arr.length; i++) {
[arr[start], arr[i]] = [arr[i], arr[start]]; // Swap
generatePermutations(arr, start + 1);
[arr[start], arr[i]] = [arr[i], arr[start]]; // Swap back
}
}
generatePermutations(words, 0);
// Step 2: Total length of concatenated string
const wordLength = words[0].length;
const totalLength = wordLength * words.length;
// Step 3: Slide through the string and check substrings
for (let i = 0; i <= s.length - totalLength; i++) {
let substring = s.slice(i, i + totalLength);
if (permutations.has(substring)) {
result.push(i);
}
}
return result;
};Time Complexity: O((n!) . (n+m) . (word_length))
Generating Permutations:
- Generating permutations of words (length n) involves O(n!) operations since there are n! permutations in total.
- Each permutation generation involves O(n) swaps and joins (for string concatenation).
- Total time for generating permutations = O(n! • n).
Sliding Window over String s:
- Length of the string S is m, and we slide overm — total_length + 1 positions.
- For each position, we extract a substring of length total_length = n • word_length, which takes O(n • word_length).
- For m - total_length + 1 positions, this part of the algorithm takes O(m • n • word_length).
Overall Time Complexity:
O(n! • n + m • n • word_length)
Space Complexity: O(n!⋅(L+m))
The auxiliary space complexity refers to the extra space used by the algorithm, excluding input and output storage. Here's the breakdown for this code:
Recursive Call Stack: The generatePermutations method uses recursion with a depth of O(n), where n is the number of words.
The space complexity of the code is primarily due to:
- Storing Permutations: All permutations of the words array are stored, requiring O(n!⋅L), where L is the total length of concatenated words (n×wordLength).
- Recursive Call Stack: The recursion for generating permutations has a depth of O(n).
- Result List: Storing indices of matching substrings takes O(m), where m is the length of the string.
Overall Space Complexity
The dominant factor is storing permutations, making the total space complexity: O(n!⋅L+m)
The Brute Force approach involved a lot of memory space and took a lot of runtime. The approach is inefficient and we need to figure out a solution which is efficient for the problem constraints.
Why the Brute Force fails ?
The brute force approach tries all permutations of the words and compares each with substrings of length wordLength×words.length. This is highly inefficient because:
- Too many permutations:
If there are n words, there are n! permutations. This grows very fast and becomes infeasible for larger inputs. - Redundant Checks:
The same substrings are often checked multiple times for different permutations. - Mismatch with Problem Structure:
The brute force approach doesn’t leverage the structure of the problem:
- Words are of the same length.
- Order doesn’t matter, only the count of words in the substring matters.
Optimal Approach
Intuition
Before moving into the optimal approach, let's gather some insight about the problem constraint.
From the problem constraints, we gather these insights:
Fixed-Length Substring
- Each valid substring has a fixed length wordLength×words.length.
- We don't need to check substrings of other lengths.
Focus on Word Count, Not Permutations
- Instead of comparing substrings with all permutations, we just need to verify:
- Does the substring contain all words exactly as they appear in the words array?
- A frequency map is perfect for this.
Overlap Between Substrings
When sliding through s, substrings overlap. For example:
- For s = "barfoothefoo", we compare:
- "barfoo" (index 0)
- "arfoot" (index 1)
- "rfooth" (index 2), etc.
- But we notice that "arfoot" mostly overlaps with "barfoo".
- Instead of starting fresh, we can reuse the work done for the previous substring.
The third insight tells us that
We have to reuse something !! . What comes in your minds when we say "reuse" ?
Yes, we will be using a sliding window for this. What will be the nature of the sliding window?
The sliding window will be static in nature since the length of all strings inside the array will be equal.
By using a sliding window, we process only the parts of the string relevant to the word length, reducing unnecessary computations.
As the window slides we will add the new word entering the window and remove the word exiting the window.
Since , we have figured out the sliding window, let's now figure out the algorithm, it should follow !!
The sliding of the window will be chunk based, why ?
Because all words have the same length, we can move the window by wordLength (length of each word) steps instead of sliding character by character, further reducing unnecessary computations.
Before, we move forward to the optimal algorithm, we need to initialize necessary
- Divide the String to chunks since all words are of the same length.
Example: For s = "barfoothefoo" and wordLength = 3, split into:
["bar", "foo", "the", "foo"]. - After we divide the string to chunks, we have to store the frequencies of each chunk .
Example: For words = ["foo", "bar"], wordFrequency = {"foo": 1, "bar": 1}.
How can we track the frequency of each substring?, we can use a Hash-Map to store each substring.
What is a HashMap/Map ?
HashMap is a data structure that stores key-value pairs.
If any duplicate Key enters the map, it just updates the value of that particular key to the newly entered value.
The Map data structure exactly aligns with our needs.
Operations we can perform on a map are:-
- Insertion
- Updation
- Search
- Removal
After the initialization, when will the window slide ?
The window have two ends, the left end and the right end.
We expand the window by moving the right pointer by wordLength(length of each word) to include a new word and then add this word to a temporary frequency map.
Why are we adding it to a temporary map ?
The goal is to check whether the current window contains exactly the same words and frequencies as the target map, which is derived from the words array.
We will shrink when the window exceeds the required size (too many words), move the left pointer by wordLength(length of each word) to remove the leftmost word from the window.
After each iteration, we will compare both the frequency maps i.e the original frequency map and the temporary map.
If they are equal , we can add the left index to our answer.
Approach
Initialization:
- Create a map targetCounts to store the frequency of each word in words.
- Initialize:
- wordLength → the length of a single word.
- windowSize → the total length of all words combined (wordLength * number of words).
Outer Loop:
- For each starting position start from 0 to wordLength - 1:
- Initialize a currentCounts map to track word frequencies in the current window.
- Set two pointers:
- left → marks the start of the current window.
- right → marks the end of the current window.
Inner Loop:
- While right is within bounds of the string:
- Extract the next word from the substring starting at right and spanning wordLength.
- Move right forward by wordLength.
Check Validity:
- If the extracted word is not in targetCounts:
- Clear the currentCounts map.
- Move left to right (reset the window).
- Otherwise:
- Add the word to currentCounts.
- If the count of this word in currentCounts exceeds its count in targetCounts:
- Shrink the window from the left by removing words until the counts match.
Valid Window:
If the size of the current window matches windowSize:
Add the left pointer (start of the window) to the result list.
Repeat:
Continue sliding the window and updating the maps until all possible starting positions have been checked.
Output:
Return the list of starting indices where valid substrings were found.
Let's Visualize with a Video
Dry-Run
String s = "catbatankitratcatbatrat";
String[] words = {"cat", "bat", "rat"};
Answer: [11,14]
Explanation: "ratcatbat" and "catbatrat" is a permutation of words which occurs in indices 11 and 14.
Initialization:
stringLength = 23 (length of s).
wordCount = 3 (length of words).
wordLength = 3 (length of any word in words since all are the same length).
wordFrequency = {"cat": 1, "bat": 1, "rat": 1} (frequency map of words).
1st Iteration (start = 0):
Initialization:
left = 0, currentWindowWords = {}, currWordCount = 0.
Inner Loop (right increments by wordLength):
right = 0:
Extract currentWord = "cat".
Add currentWord to currentWindowWords = {"cat": 1}.
Increment currWordCount = 1.
right = 3:
Extract currentWord = "bat".
Add currentWord to currentWindowWords = {"cat": 1, "bat": 1}.
Increment currWordCount = 2.
right = 6:
Extract currentWord = "ank".
Not in wordFrequency. Reset currentWindowWords = {}, currWordCount = 0.
Move left = 9.
right = 9:
Extract currentWord = "itr".
Not in wordFrequency. Reset currentWindowWords = {}, currWordCount = 0.
Move left = 12.
right = 12:
Extract currentWord = "atc".
Not in wordFrequency. Reset currentWindowWords = {}, currWordCount = 0.
Move left = 15.
right = 15:
Extract currentWord = "atb".
Not in wordFrequency. Reset currentWindowWords = {}, currWordCount = 0.
Move left = 18.
right = 18:
Extract currentWord = "atr".
Not in wordFrequency. Reset currentWindowWords = {}, currWordCount = 0.
Move left = 21.
2nd Iteration (start = 1):
Initialization:
left = 1, currentWindowWords = {}, currWordCount = 0.
Inner Loop (right increments by wordLength):
right = 1:
Extract currentWord = "atb".
Not in wordFrequency. Reset currentWindowWords = {}, currWordCount = 0.
Move left = 4.
right = 4:
Extract currentWord = "ata".
Not in wordFrequency. Reset currentWindowWords = {}, currWordCount = 0.
Move left = 7.
right = 7:
Extract currentWord = "nki".
Not in wordFrequency. Reset currentWindowWords = {}, currWordCount = 0.
Move left = 10.
right = 10:
Extract currentWord = "tra".
Not in wordFrequency. Reset currentWindowWords = {}, currWordCount = 0.
Move left = 13.
right = 13:
Extract currentWord = "tca".
Not in wordFrequency. Reset currentWindowWords = {}, currWordCount = 0.
Move left = 16.
right = 16:
Extract currentWord = "tba".
Not in wordFrequency. Reset currentWindowWords = {}, currWordCount = 0.
Move left = 19.
3rd Iteration (start = 2):
Initialization:
left = 2, currentWindowWords = {}, currWordCount = 0.
Inner Loop (right increments by wordLength):
right = 2:
Extract currentWord = "tba".
Not in wordFrequency. Reset currentWindowWords = {}, currWordCount = 0.
Move left = 5.
right = 5:
Extract currentWord = "tan".
Not in wordFrequency. Reset currentWindowWords = {}, currWordCount = 0.
Move left = 8.
right = 8:
Extract currentWord = "kit".
Not in wordFrequency. Reset currentWindowWords = {}, currWordCount = 0.
Move left = 11.
right = 11:
Extract currentWord = "rat".
Add currentWord to currentWindowWords = {"rat": 1}.
Increment currWordCount = 1.
right = 14:
Extract currentWord = "cat".
Add currentWord to currentWindowWords = {"rat": 1, "cat": 1}.
Increment currWordCount = 2.
right = 17:
Extract currentWord = "bat".
Add currentWord to currentWindowWords = {"rat": 1, "cat": 1, "bat": 1}.
Increment currWordCount = 3.
Now, currWordCount == wordCount and currentWindowWords.equals(wordFrequency).
Add left = 11 to the result: result = [11].
right = 20:
Extract currentWord = "rat".
Add currentWord to currentWindowWords = {"rat": 2, "cat": 1, "bat": 1}.
Increment currWordCount = 4.
Since currWordCount > wordCount, shrink the window:
Remove the word at left = 11: "rat".
Update currentWindowWords = {"rat": 1, "cat": 1, "bat": 1}.
Decrement currWordCount = 3.
Move left = 14.
Now, currWordCount == wordCount and currentWindowWords.equals(wordFrequency).
Add left = 14 to the result: result = [11, 14].
Final Output:
The result list contains [11, 14], which are the starting indices of the substrings in s that concatenate all words in words in any order.
Optimal Code in all Languages
1. C++ Try on Compiler
class Solution {
public:
vector<int> findSubstring(string s, vector<string>& words) {
vector<int> result;
int stringLength = s.length();
int wordCount = words.size();
int wordLength = words[0].length();
// Create a frequency map for the words in the array
unordered_map<string, int> wordFrequency;
for (const string& word : words) {
wordFrequency[word]++;
}
// Loop through the string in chunks of the word length
for (int start = 0; start < wordLength; start++) {
unordered_map<string, int> currentWindowWords;
int currWordCount = 0;
int left = start;
// Move the right pointer in steps of word length
for (int right = start; right + wordLength <= stringLength; right += wordLength) {
string currentWord = s.substr(right, wordLength);
if (wordFrequency.find(currentWord) != wordFrequency.end()) {
currentWindowWords[currentWord]++;
currWordCount++;
// Shrink the window if the frequency exceeds the required count
while (currentWindowWords[currentWord] > wordFrequency[currentWord]) {
string wordToRemove = s.substr(left, wordLength);
currentWindowWords[wordToRemove]--;
currWordCount--;
left += wordLength;
}
// Check if the window contains all words
if (currWordCount == wordCount) {
result.push_back(left);
}
} else {
// Reset if the word is invalid
currentWindowWords.clear();
currWordCount = 0;
left = right + wordLength;
}
}
}
return result;
}
};2. Java Try on Compiler
class Solution {
public List<Integer> findSubstring(String s, String[] words) {
List<Integer> result = new ArrayList<>();
int stringLength = s.length();
int wordCount = words.length;
int wordLength = words[0].length();
// Create a frequency map for the words in the array
HashMap<String, Integer> wordFrequency = new HashMap<>();
for (String word : words) {
wordFrequency.put(word, wordFrequency.getOrDefault(word, 0) + 1);
}
// Loop through the string in chunks of the word length
for (int start = 0; start < wordLength; start++) {
HashMap<String, Integer> currentWindowWords = new HashMap<>();
int currWordCount = 0;
int left = start;
// Move the right pointer in steps of word length
for (int right = start; right + wordLength <= stringLength; right += wordLength) {
// Extract a word of size `wordLength` from the string
String currentWord = s.substring(right, right + wordLength);
// Add the word to the temporary frequency map
currentWindowWords.put(currentWord, currentWindowWords.getOrDefault(currentWord, 0) + 1);
currWordCount++;
// Shrink the window if it exceeds the required number of words
while (currWordCount > wordCount) {
String wordToRemove = s.substring(left, left + wordLength);
if (currentWindowWords.containsKey(wordToRemove)) {
if (currentWindowWords.get(wordToRemove) > 1) {
currentWindowWords.put(wordToRemove, currentWindowWords.get(wordToRemove) - 1);
} else {
currentWindowWords.remove(wordToRemove);
}
}
currWordCount--;
left += wordLength; // Move the left pointer
}
if (!wordFrequency.containsKey(currentWord)) {
currentWindowWords.clear();
currWordCount = 0;
left = right + wordLength; // Move left pointer to the next word after the invalid one
continue;
}
// Check if the current window matches the original word frequency
if (currWordCount == wordCount && currentWindowWords.equals(wordFrequency)) {
result.add(left);
}
}
}
return result;
}
}
3. Python Try on Compiler
class Solution:
def findSubstring(self, s: str, words: List[str]) -> List[int]:
result = []
string_length = len(s)
word_count = len(words)
word_length = len(words[0])
# Create a frequency map for the words
word_frequency = Counter(words)
# Loop through the string in chunks of the word length
for start in range(word_length):
current_window_words = Counter()
curr_word_count = 0
left = start
# Move the right pointer in steps of word length
for right in range(start, string_length - word_length + 1, word_length):
current_word = s[right:right + word_length]
if current_word in word_frequency:
current_window_words[current_word] += 1
curr_word_count += 1
# Shrink the window if the frequency exceeds the required count
while current_window_words[current_word] > word_frequency[current_word]:
word_to_remove = s[left:left + word_length]
current_window_words[word_to_remove] -= 1
curr_word_count -= 1
left += word_length
# Check if the window contains all words
if curr_word_count == word_count:
result.append(left)
else:
# Reset if the word is invalid
current_window_words.clear()
curr_word_count = 0
left = right + word_length
return result
4. JavaScript Try on Compiler
/**
* @param {string} s
* @param {string[]} words
* @return {number[]}
*/
var findSubstring = function(s, words) {
const result = [];
const stringLength = s.length;
const wordCount = words.length;
const wordLength = words[0].length;
// Create a frequency map for the words
const wordFrequency = {};
for (const word of words) {
wordFrequency[word] = (wordFrequency[word] || 0) + 1;
}
// Loop through the string in chunks of the word length
for (let start = 0; start < wordLength; start++) {
const currentWindowWords = {};
let currWordCount = 0;
let left = start;
// Move the right pointer in steps of word length
for (let right = start; right + wordLength <= stringLength; right += wordLength) {
const currentWord = s.substring(right, right + wordLength);
if (wordFrequency[currentWord] !== undefined) {
currentWindowWords[currentWord] = (currentWindowWords[currentWord] || 0) + 1;
currWordCount++;
while (currentWindowWords[currentWord] > wordFrequency[currentWord]) {
const wordToRemove = s.substring(left, left + wordLength);
currentWindowWords[wordToRemove]--;
currWordCount--;
left += wordLength;
}
if (currWordCount === wordCount) {
result.push(left);
}
} else {
for (const key in currentWindowWords) delete currentWindowWords[key];
currWordCount = 0;
left = right + wordLength;
}
}
}
return result;
};Time Complexity: O(n x m)
n = stringLength
m= wordCount
The time complexity is O(stringLength X wordCount). This arises because the algorithm slides a window across the string, which takes O(stringLength), and processes up to wordCount words in each window for frequency comparisons and updates.
The outer loop runs wordLength times, but as wordLength is constant, it does not affect asymptotic complexity.
Thus, the overall time complexity is O(string length X word count).
Space Complexity: O(n)
Auxiliary space refers to additional memory used beyond input storage:
Frequency maps:
- wordFrequency: Stores wordCount key-value pairs.
O(wordCount). - currentWindowWords: Can grow to at most wordCount pairs (if all words are in the window). O(wordCount).
Thus, auxiliary space complexity is: O(wordCount)
Total Space Complexity
Total space includes auxiliary space and input storage:
Input storage:
- String s: O(stringLength).
- Array words: Contains wordCount words of wordLength each. O(wordCount×wordLength).
Auxiliary space: As computed above, O(wordCount).
The total space complexity is therefore: O(stringLength+wordCount×wordLength)
If wordLength is constant, the total space complexity is: O(stringLength+wordCount)
Learning Tip
Given two strings s and t of lengths m and n respectively, return the minimum window substring of s such that every character in t (including duplicates) is included in the window. If there is no such substring, return the empty string "".
The testcases will be generated such that the answer is unique.
You are given an array of integers nums, there is a sliding window of size k which is moving from the very left of the array to the very right. You can only see the k numbers in the window. Each time the sliding window moves right by one position.
Return the max sliding window.