Longest Repeating Character Replacement
Problem Description
You are given a string s with all Upper Case characters (‘A,’’ B,’….’Z’) and an integer k. You can choose any character of the string and change it to any other uppercase English character. You can perform this operation at most k times.
Return the length of the longest substring containing the same letter you can get after performing the above operations.
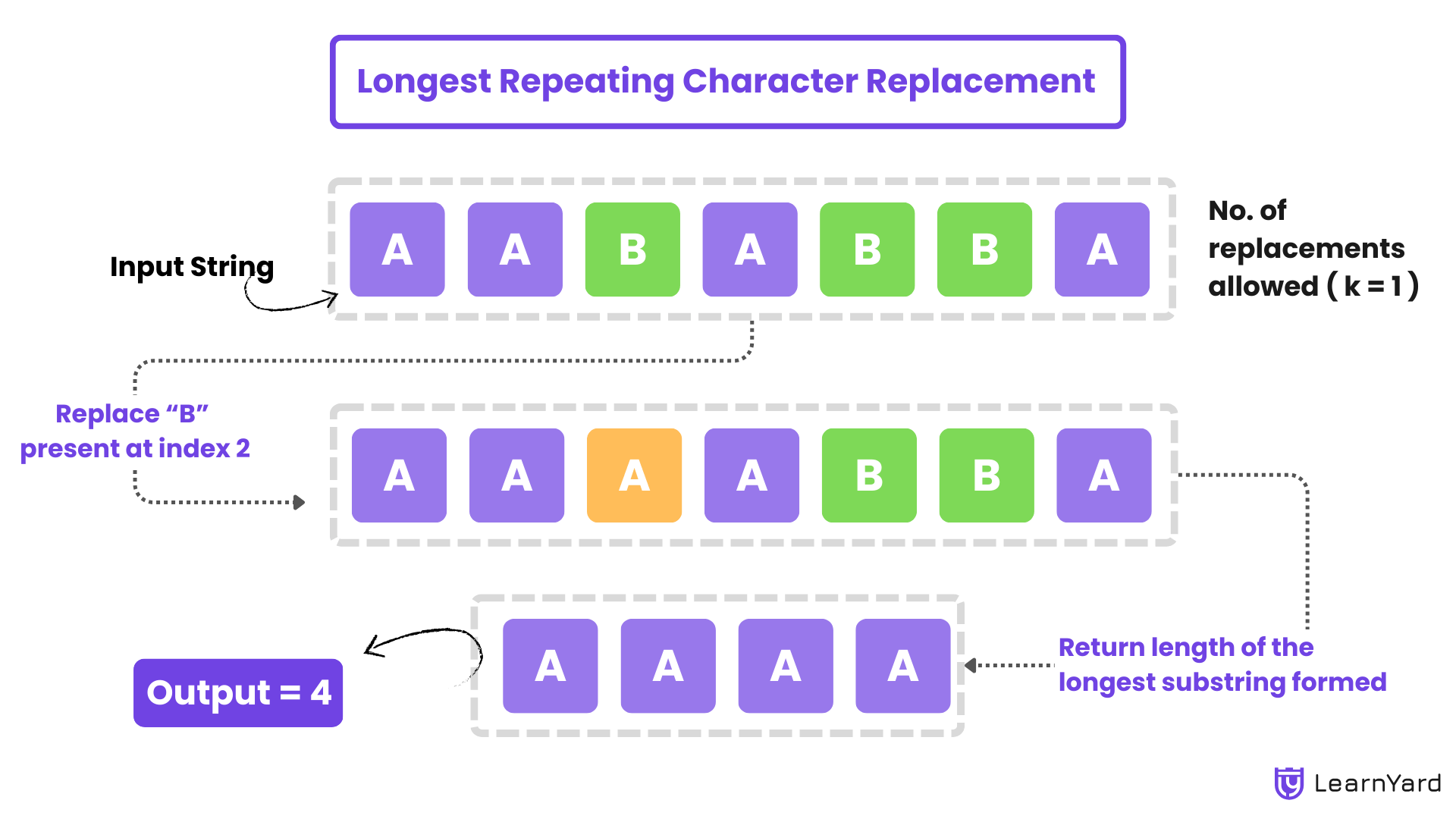
Explanation
You have a string made up of uppercase letters (like "A", "B", "C", etc.), and you're allowed to change up to k letters in that string to any other uppercase letter.
If k=3, we can change 1 ,2 or 3 letters in the string.
Your goal is to find the longest section of the string (called a substring) where all the letters are the same after you've made those changes.
Suppose s= “AABCAD” and k=2
We can replace any 1 or 2 characters to a new character in s.
We can clearly say that we will be changing the characters ‘B’ and ‘C’ present at indices 2 or 3 to ‘A’. Then the newly formed string is “AAAAAD”.
What is a Substring ?
A substring is a contiguous sequence of characters within a string. For a string s = "ABCDEF", a substring must consist of characters that appear consecutively in the original string.
Single-character substrings:"A", "B", "C", "D", "E", "F"
Two-character substrings:"AB", "BC", "CD", "DE", "EF"
Three-character substrings:"ABC", "BCD", "CDE", "DEF"
Four-character substrings:"ABCD", "BCDE", "CDEF"
Five-character substrings:"ABCDE", "BCDEF"
Six-character substring (the whole string itself):"ABCDEF"
Invalid substrings such as "ACD", "ACE", or "BAC" remain unchanged since they are not contiguous in the original string.
Example of Longest Repeating Character Replacement
Input: s = "ABAB", k = 2
Output: 4
Explanation: We can replace the ‘B’ present at index 1 with ‘A’ and the character ‘B’ present at index 3 with ‘A’. The new string becomes “AAAA” which has the longest repeating characters in a substring of length 4. We can also replace the character ‘A’ present at indices 0 and 2 with ‘B’ to form the new string as “B,” which becomes the longest substring with repeating characters of length 4.
Input: s = "AABABBA", k = 1
Output: 4
Explanation: We can replace the character ‘B’ present at the 2nd index with ‘A’. The new string formed will be “AAAABBA”. In the newly formed string, the substring “AAAA” is the longest substring of length 4 with repeating characters in it. We will not be replacing any characters in the string because k=1, which means that 1 or less than 1 replacements are available.
Constraints:
- 1 <= s.length <= 10^5
- s consists of only uppercase English letters.
- 0 <= k <= s.length
Although this problem might seem straightforward, there are different ways to solve it, like two pointers/sliding window algorithm,dynamic programming,etc. Each approach has its own benefits and challenges in terms of how fast it works and how much memory it uses
Brute Force Approach
Intuition
Since we want to find the longest substring (section of the string) where all characters are the same after changing up to k characters. So, in the brute force approach, we will try generating every possible substring of the string, and for each substring, we will count how many changes we can make to turn the substring into one with all the same letters. If the number of changes is less than or equal to k, we will compare it with the length of the longest valid substring found so far. Else we will not. In the end, the longest valid substring will be our answer.
How to generate the Substrings of s ?
To generate all substrings of s, we will be using two loops.
We begin at the first index (index 0) of the string and move through each index of the string one by one. For each index, this becomes the starting point of the substring.
At each starting index, we iterate through the next indices in the string. We continue this process until we reach the end of the string.
For each starting index, we consider every possible ending index. We ensure that the ending index is always greater than the starting index to form non-empty substrings.
For each pair of starting and ending indices, a substring is formed by selecting the characters between the starting index and one less than the ending index. This way, we build all possible substrings.
For example, for a string "ABCDEF":
Start at index 0:
Substrings: s[0 to 1] = "A", s[0 to 2] = "AB", s[0 to 3] = "ABC", ..., s[0 to 6] = "ABCDEF"
Start at index 1:
Substrings: s[1 to 2] = "B", s[1 to 3] = "BC", ..., s[1 to 6] = "BCDEF"
Continue with other indices until you cover all starting and ending points.
Each iteration forms a substring by slicing between the selected start and end indices.
For example if s = “ABCDE”,
The start point = 0
The end point = 1
The highlighted part is the substring formed in “ABCDE”.
Then the end point increments to the next index i.e end point = 2
The highlighted part is the substring formed in “ABCDE”.
Similarly, we will move the end point till the end of the substring.
Once the end point reaches the end of the substring. We will increment the start point and start the same procedure all again until our start point is equal to length of the substring.
When the start point =1
The end point = 2
The highlighted part is the substring formed , “ABCDE”
The next substring formed is the highlighted part in “ABCDE
Let’s visualize with an example
s = “ABCAABBC” , k=2
- Since we know how to generate a substring of s.
- The first substring we will be getting is the highlighted part in “ABCAABBC”.
- We will check which is the most appealing character in the substring “AB” ,
We come to know that both ‘A’ and ‘B’ appear once.
Since we have k=2, we can either change ‘B’ to ‘A’ so the newly formed string becomes “AA,” or we can change ‘A’ to ‘B’ to make the string “BB”. In both of the cases, the length of the longest substring is 2.
The next generated substring is the highlighted part in “ABCAABBC”.
Again calculating the common characters shows that ‘A’, ‘B’ and ‘C’ occur once.
Since k = 2, we can convert any two of the characters with the third.
i.e, either ‘B’ and ‘C’ to ‘A’ resulting in “AAA.”
Or ‘C’ and ‘A’ to ‘B’ resulting in “BBB”
Else ‘A’ and ‘B’ to ‘C’ resulting in “CCC”.
In all of the three cases, the maximum length obtained is 3.
Similarly moving to further substrings we encounter the substring “ABCA” of the string “ABCAABBC”.
In this substring, ‘A’ occurs 3 times.
‘B’ occurs 1 time
‘C’ occur 1 time.
The character 'A' occurs most frequently, with a count of 3. The other two characters, 'B' and 'C', each appear only once.
Now, imagine we have a value k which represents the number of changes we can make in the substring. The goal is to transform the less frequent characters into the most frequent ones ('A' in this case) to maximize the length of the substring with repeating characters.
Since both 'B' and 'C' appear less frequently than 'A', we can change them into 'A' as long as k is at least 2 (because there are two characters to change). If k ≥ 2, we can transform 'B' and 'C' into 'A', resulting in the string "AAAAABC".
The new substring “AAAAA” has a maximum length of 5 with repeating 'A's. This demonstrates how changing less frequent characters can help extend the length of a repeating-character substring, provided we have enough changes (k) available to do so
But how can we track the frequencies of a given character?
We can use a hash table of size 26 to store the frequencies of each character.
Why Hash-Table of size 26 ?
Because there are 26 Upper Case characters .
How can we use the Hash-Table ?
But how can we use it?? It’s simple, we can create an array of size 26.
- The character 'A' has the ASCII code 65.
- The character 'B' has the ASCII code 66.
- The character 'C' has the ASCII code 67.
How to Insert , Update and Access data from Hash-Table ?
In the actual code, we can insert and update the elements with the basic syntax
freqTable[s.charAt(i)]++ in Java or freqTable[s[i]]++ in C++ or freqTable[ord(s[i])]+=1 in Python or freqTable[s.charCodeAt(i)]++ in JavaScript.
To access the value present in that index.
We write freqTable[s.charAt(i)] in Java or freqTable[s[i]]++ in C++ or freqTable[ord(s[i])]+=1 in Python or freqTable[s.charCodeAt(i)]++ in JavaScript.
Alternative to Hash-Table
Can we think of a data structure that stores the Character and its frequency together??
Yes, we can maintain it in the form of a register that records each character to it’s frequency i.e the no of occurrences of that particular character.
The data structure that meets our condition is a Map.
What is a HashMap/ Map ?
A Map stores Key-Value Pairs.
If any duplicate Key enters the map, it just updates the value of that particular key to the newly entered value.
This is what we want for our optimal algorithm. We will be storing the Character in the map and whenever we encounter a character again, the map will allow us to recognize that it is a duplicate. This way, we can quickly determine whether the characters in the current substring are unique. By tracking duplicates, we can effectively manage and update our substring to ensure it contains only unique characters.
Why is using a Hash-table better than using a Hash-Map ??
Performance !!
Accessing and updating an element in the hash-table has a constant time complexity, O(1).
In contrast, a HashMap can have an average case time complexity of O(1) but can degrade to
O(n) in worst-case scenarios due to collisions or rehashing.
This is particularly important in time-sensitive applications.
Approach
- We can solve the problem by using two nested loops to generate all possible substrings of the given string.
- For each substring, we will check if all characters in that substring are unique.
- To efficiently check for uniqueness, we can maintain a boolean array of size 26, which corresponds to all possible ASCII characters.
- We will also keep track of the maximum length of valid substrings (those with unique characters).
Dry-Run
String s= “ABCAABBC”
k=2
Answer= 5
Explanation:- Changing the characters ‘B’ and ‘C’ to ‘A’ makes the newly formed string “AAAAABBC” where the substring “AAAAA” has the maximum length of 5.
Initial Variables:
maxLength = 0
Outer Loop: Iterate through each starting index i of the string s.
Inner Loop:
For each starting index i, iterate through each ending index j (from i to s.length() - 1) to get all substrings from i to j.
Check Each Substring:
Calculate changes needed to make the substring uniform by calling canMakeSameWithKChanges.
Update maxLength if the substring length can be made uniform with k or fewer changes.
Dry Run of Each Substring:
Substrings starting from index i = 0:
j = 0: Substring "A" — changesNeeded = 0 (already uniform), maxLength = 1
j = 1: Substring "AB" — changesNeeded = 1, maxLength = 2
j = 2: Substring "ABC" — changesNeeded = 2, maxLength = 3
j = 3: Substring "ABCA" — changesNeeded = 2, maxLength = 4
j = 4: Substring "ABCAA" — changesNeeded = 2, maxLength = 5
j = 5: Substring "ABCAAB" — changesNeeded = 3, not updated (exceeds k)
j = 6: Substring "ABCAABB" — changesNeeded = 3, not updated
j = 7: Substring "ABCAABBC" — changesNeeded = 4, not updated
Substrings starting from index i = 1:
j = 1: Substring "B" — changesNeeded = 0, maxLength = 5
j = 2: Substring "BC" — changesNeeded = 1, maxLength = 5
j = 3: Substring "BCA" — changesNeeded = 2, maxLength = 5
j = 4: Substring "BCAA" — changesNeeded = 2, maxLength = 5
j = 5: Substring "BCAAB" — changesNeeded = 3, not updated
j = 6: Substring "BCAABB" — changesNeeded = 3, not updated
j = 7: Substring "BCAABBC" — changesNeeded = 4, not updated
Substrings starting from index i = 2:
j = 2: Substring "C" — changesNeeded = 0, maxLength = 5
j = 3: Substring "CA" — changesNeeded = 1, maxLength = 5
j = 4: Substring "CAA" — changesNeeded = 1, maxLength = 5
j = 5: Substring "CAAB" — changesNeeded = 2, maxLength = 5
j = 6: Substring "CAABB" — changesNeeded = 2, maxLength = 5
j = 7: Substring "CAABBC" — changesNeeded = 3, not updated
Substrings starting from index i = 3:
j = 3: Substring "A" — changesNeeded = 0, maxLength = 5
j = 4: Substring "AA" — changesNeeded = 0, maxLength = 5
j = 5: Substring "AAB" — changesNeeded = 1, maxLength = 5
j = 6: Substring "AABB" — changesNeeded = 1, maxLength = 5
j = 7: Substring "AABBC" — changesNeeded = 2, maxLength = 5
Substrings starting from index i = 4:
j = 4: Substring "A" — changesNeeded = 0, maxLength = 5
j = 5: Substring "AB" — changesNeeded = 1, maxLength = 5
j = 6: Substring "ABB" — changesNeeded = 1, maxLength = 5
j = 7: Substring "ABBC" — changesNeeded = 2, maxLength = 5
Substrings starting from index i = 5:
j = 5: Substring "B" — changesNeeded = 0, maxLength = 5
j = 6: Substring "BB" — changesNeeded = 0, maxLength = 5
j = 7: Substring "BBC" — changesNeeded = 1, maxLength = 5
Substrings starting from index i = 6:
j = 6: Substring "B" — changesNeeded = 0, maxLength = 5
j = 7: Substring "BC" — changesNeeded = 1, maxLength = 5
Substrings starting from index i = 7:
j = 7: Substring "C" — changesNeeded = 0, maxLength = 5
Final Result:
After checking all substrings, the longest valid substring length is 5.
Brute Force Code for all languages.
1. C++ Try on Compiler
#include <iostream>
#include <string>
#include <vector>
#include <algorithm>
using namespace std;
// Function to check if we can make all characters in the substring the same with at most k changes
bool canMakeSameWithKChanges(const string &substring, int k) {
int charFrequency[26] = {0}; // Array to track the frequency of each uppercase character
int maxFrequency = 0; // To track the frequency of the most common character
// Count the frequency of each character in the substring
for (char c : substring) {
charFrequency[c - 'A']++; // Increment the count for character c
maxFrequency = max(maxFrequency, charFrequency[c - 'A']); // Track the most frequent character
}
// Calculate the number of changes needed to make the entire substring the same
int changesNeeded = substring.size() - maxFrequency;
// Return true if we can make the substring uniform with k or fewer changes
return changesNeeded <= k;
}
// Function to find the length of the longest substring with the same letter after at most k changes
int longestSubstring(const string &s, int k) {
int maxLength = 0; // Variable to store the length of the longest valid substring
// Try every possible substring
for (int i = 0; i < s.size(); i++) {
for (int j = i; j < s.size(); j++) {
// Get the current substring from index i to j
string substring = s.substr(i, j - i + 1);
// Check how many changes are needed to make all characters in this substring the same
if (canMakeSameWithKChanges(substring, k)) {
// If it's valid, update the maximum length
maxLength = max(maxLength, static_cast<int>(substring.size()));
}
}
}
return maxLength; // Return the length of the longest valid substring
}
2. Java Try on Compiler
import java.util.Scanner;
public class LongestSubstringWithSameLetter {
// Function to find the length of the longest substring with the same letter after at most k changes
public static int longestSubstring(String s, int k) {
int maxLength = 0; // Variable to store the length of the longest valid substring
// Try every possible substring
for (int i = 0; i < s.length(); i++) {
for (int j = i; j < s.length(); j++) {
// Get the current substring from index i to j
String substring = s.substring(i, j + 1);
// Check how many changes are needed to make all characters in this substring the same
if (canMakeSameWithKChanges(substring, k)) {
// If it's valid, update the maximum length
maxLength = Math.max(maxLength, substring.length());
}
}
}
return maxLength; // Return the length of the longest valid substring
}
// Function to check if we can make all characters in the substring the same with at most k changes
public static boolean canMakeSameWithKChanges(String substring, int k) {
int[] charFrequency = new int[26]; // Array to track the frequency of each uppercase letter
int maxFrequency = 0; // To track the frequency of the most common character
// Count the frequency of each character in the substring
for (char c : substring.toCharArray()) {
charFrequency[c - 'A']++; // Increment the count for character c (only uppercase letters)
maxFrequency = Math.max(maxFrequency, charFrequency[c - 'A']); // Track the most frequent character
}
// Calculate the number of changes needed to make the entire substring the same
int changesNeeded = substring.length() - maxFrequency;
// Return true if we can make the substring uniform with k or fewer changes
return changesNeeded <= k;
}
}
3. Python Try on Compiler
# Function to check if we can make all characters in the substring the same with at most k changes
def can_make_same_with_k_changes(substring, k):
char_frequency = [0] * 26 # Array to store frequencies for uppercase letters only
max_frequency = 0 # To track the maximum frequency of any character in the substring
# Calculate the frequency of each character in the substring
for char in substring:
index = ord(char) - ord('A') # Map 'A'-'Z' to 0-25
char_frequency[index] += 1
max_frequency = max(max_frequency, char_frequency[index])
# Calculate changes needed
changes_needed = len(substring) - max_frequency
return changes_needed <= k # Check if changes required are within allowed limit
# Function to find the length of the longest valid substring
def longest_substring(s, k):
max_length = 0
# Iterate over all possible substrings
for i in range(len(s)):
for j in range(i, len(s)):
substring = s[i:j+1] # Get substring
if can_make_same_with_k_changes(substring, k):
max_length = max(max_length, len(substring)) # Update max length
return max_length
4. JavaScript Try on Compiler
const readline = require('readline');
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout
});
function canMakeSameWithKChanges(substring, k) {
let charFrequency = new Array(26).fill(0); // Array to store frequencies for uppercase letters only
let maxFrequency = 0; // To track the maximum frequency of any character in the substring
// Calculate the frequency of each character in the substring
for (let i = 0; i < substring.length; i++) {
let index = substring.charCodeAt(i) - 'A'.charCodeAt(0); // Map 'A'-'Z' to 0-25
charFrequency[index]++;
maxFrequency = Math.max(maxFrequency, charFrequency[index]);
}
// Calculate changes needed
let changesNeeded = substring.length - maxFrequency;
return changesNeeded <= k; // Check if changes required are within allowed limit
}
function longestSubstring(s, k) {
let maxLength = 0;
// Iterate over all possible substrings
for (let i = 0; i < s.length; i++) {
for (let j = i; j < s.length; j++) {
let substring = s.substring(i, j + 1); // Get substring
if (canMakeSameWithKChanges(substring, k)) {
maxLength = Math.max(maxLength, substring.length); // Update max length
}
}
}
return maxLength;
}
Time Complexity : O(n^3)
The solution consists of two nested loops, iterating over all possible substrings of the input string. Inside the inner loop, there is a function that calculates the frequency of each character in the substring and checks if the substring can be made uniform with at most k changes.
The outer loop runs i from 0 to n-1, where n is the length of the string.
The inner loop runs j from i to n-1, making it quadratic in nature.
This simplifies to O(n^2), meaning the outer loops together contribute 𝑂(𝑛^2).
For each substring, the canMakeSameWithKChanges function counts the frequency of each character, which takes O(m),
where m is the length of the current substring.
The length of the substring varies from 1 to n, but in the worst case, it is O(n) for the longest substring.
Thus, in the worst case, each inner iteration takes O(n) for frequency calculation and comparison.
Overall Time Complexity:
Since we are iterating through O(n^2) substrings, and for each substring, we perform a frequency count in O(n),
the total time complexity is: O(n^3)
Space Complexity: O(n)
Auxiliary Space Complexity:
Auxiliary space is the extra space or temporary space used by the algorithm, not counting the input data.
In the canMakeSameWithKChanges function, we use a character frequency array of size 26, which requires O(26)=O(1) space.
No additional data structures are used beyond this array, except for some constant space variables like maxFrequency and changesNeeded.
Thus, the auxiliary space complexity is: O(1).
Total Space Complexity:
Total space complexity includes both the input space and the auxiliary space.
Input space: The input string requires O(n) space, where n is the length of the string.
Auxiliary space: As analyzed above, the auxiliary space complexity is O(1) due to the fixed-size frequency array.
Thus, the total space complexity is O(n).
This is extremely slow and not feasible within typical time limits (usually 1-2 seconds). Most programming environments allow around 10^8 operations per second, so 10^15 operations would take about 10 million seconds (over 115 days!), which is far too long.
The interviewer won’t be happy with your solution.
We have to optimize the Time Complexity to move further in the interview!
Optimized Approach
Intuition
The first key observation is that since the Brute Force Approach gives us a time complexity of O(n^3). So, we need to optimize it to either O(n^2), O(n) or O(logn).
Since, the the string size can 10^5, O(n^2) will also result in Time Limit Exceeded.
So, the optimal solution can be an O(n) solution, as we have to traverse the whole string to get the answer. Let's check it out !!
In the brute force approach, we generate all possible substrings and then check if we can change the less frequent characters to the most frequent ones based on the value of k.
Does this result in unnecessary computation? Let’s check it out !!
Can we check the k constraint before generating substrings?
Consider the example:
s = "AABCDE", k = 2
The first substring is "AAB". We can change 'B' to 'A', resulting in "AAA".
The next substring is "AABC". Here, we can change both 'B' and 'C' to 'A', resulting in "AAAA".
So far, generating these substrings makes sense, as we can convert them into valid uniform strings by using no more than k changes.
However, what about the next substring, "AABCD"?
We know we can only change at most 2 characters, but this substring has 3 distinct characters (B, C, and D) other than the most frequent character (A). Even if we use all k = 2 changes, we’ll still be left with one unchanged character.
Hence, there’s no point in checking this substring because it can never satisfy the condition of having all characters the same.
Key Insight:
Instead of generating substrings blindly, we should focus on the number of distinct characters in the substring other than the most frequent one. If this number exceeds k, there’s no point in continuing with that substring, as it cannot be made uniformly within the given limit of k changes.
We got our first insight !!
In the brute force approach, we generated every possible substring, checked if we could convert it into a uniform string with k changes, and computed the result. This was inefficient, as we repeatedly generated and processed substrings that couldn’t be converted.
Can we avoid generating substrings multiple times?
Yes! Instead of repeatedly generating substrings, we can establish a dynamic frame, where characters enter and exit the frame as we slide it across the string.
How will the Frame work ?
The frame is designed in such a way that it has two ends let’s call it the left end and the right end.
We will be maintaining a sliding frame, inside which characters can come and go. This frame will hold the characters that we're currently considering for conversion into a uniform string. The size of this frame dynamically adjusts based on the k constraint.
How do we manage this dynamic frame?
The sliding frame will only allow up to k characters that need to be changed to match the most frequent character in the current frame.
As long as the number of characters that need changing (i.e., the length of the frame minus the count of the most frequent character) is less than or equal to k, we can expand the frame i.e. we will increase the right end.
Once the number of characters that need changing exceeds k, we shrink the frame from the left to restore the condition, making sure that only valid substrings are considered.
This process ensures that we efficiently manage substrings without generating them repeatedly or performing redundant checks.
We were able to get our 2nd insight.
Let's summarize the insights we got
Check the value of k before considering a substring.
Instead of generating a substring, use a dynamic frame where we can push and remove characters.
In the above two insights,
We took O(1) runtime to check the value of k before generating the substring.
We took O(n) runtime to compute the substring.
Yes, it is an O(n) solution !!
Let us call the frame a window, and since the window is dynamic, it shrinks and expands according to our logic.
Let’s call this algorithm the Sliding Window Algorithm.
Since we got our Optimal Algorithm now visugiven video.
How Sliding Window Algorithm works for this particular solution.
Dry-Run
String s= “ABCAABBC” , k=2
Answer= 5
Explanation:- changing the characters ‘B’ and ‘C’ to ‘A’ makes the newly formed string “AAAAABBC” where the substring “AAAAA” has the maximum length of 5.
Initial Setup:
left = 0, right = 0
n = 8 (length of the string)
maxLen = 0, maxCount = 0
charFrequency = new int[26] (all initialized to 0)
Iteration 1: right = 0, curr = 'A'
charFrequency['A']++ → charFrequency['A'] = 1
Update maxCount = Math.max(maxCount, charFrequency['A']) → maxCount = 1
Check if the window is valid:
(right - left + 1) - maxCount > k → (0 - 0 + 1) - 1 > 2 → 0 > 2 (false)
Update maxLen = Math.max(maxLen, right - left + 1) → maxLen = 1
Current State:
charFrequency = [A: 1, others: 0]
maxLen = 1, maxCount = 1, left = 0
Iteration 2: right = 1, curr = 'B'
charFrequency['B']++ → charFrequency['B'] = 1
maxCount = Math.max(maxCount, charFrequency['B']) → maxCount = 1 (unchanged)
Check if the window is valid:
(1 - 0 + 1) - 1 > 2 → 1 > 2 (false)
Update maxLen = Math.max(maxLen, right - left + 1) → maxLen = 2
Current State:
charFrequency = [A: 1, B: 1, others: 0]
maxLen = 2, maxCount = 1, left = 0
Iteration 3: right = 2, curr = 'C'
charFrequency['C']++ → charFrequency['C'] = 1
maxCount = Math.max(maxCount, charFrequency['C']) → maxCount = 1 (unchanged)
Check if the window is valid:
(2 - 0 + 1) - 1 > 2 → 2 > 2 (false)
Update maxLen = Math.max(maxLen, right - left + 1) → maxLen = 3
Current State:
charFrequency = [A: 1, B: 1, C: 1, others: 0]
maxLen = 3, maxCount = 1, left = 0
Iteration 4: right = 3, curr = 'A'
charFrequency['A']++ → charFrequency['A'] = 2
maxCount = Math.max(maxCount, charFrequency['A']) → maxCount = 2
Check if the window is valid:
(3 - 0 + 1) - 2 > 2 → 2 > 2 (false)
Update maxLen = Math.max(maxLen, right - left + 1) → maxLen = 4
Current State:
charFrequency = [A: 2, B: 1, C: 1, others: 0]
maxLen = 4, maxCount = 2, left = 0
Iteration 5: right = 4, curr = 'A'
charFrequency['A']++ → charFrequency['A'] = 3
maxCount = Math.max(maxCount, charFrequency['A']) → maxCount = 3
Check if the window is valid:
(4 - 0 + 1) - 3 > 2 → 2 > 2 (false)
Update maxLen = Math.max(maxLen, right - left + 1) → maxLen = 5
Current State:
charFrequency = [A: 3, B: 1, C: 1, others: 0]
maxLen = 5, maxCount = 3, left = 0
Iteration 6: right = 5, curr = 'B'
charFrequency['B']++ → charFrequency['B'] = 2
maxCount = Math.max(maxCount, charFrequency['B']) → maxCount = 3 (unchanged)
Check if the window is valid:
(5 - 0 + 1) - 3 > 2 → 3 > 2 (true)
Window is invalid, move left to shrink the window:
Decrement charFrequency['A'] → charFrequency['A'] = 2
left++ → left = 1
Check if the window is valid again:
(5 - 1 + 1) - 3 > 2 → 2 > 2 (false)
Update maxLen = Math.max(maxLen, right - left + 1) → maxLen = 5
Current State:
charFrequency = [A: 2, B: 2, C: 1, others: 0]
maxLen = 5, maxCount = 3, left = 1
Iteration 7: right = 6, curr = 'B'
charFrequency['B']++ → charFrequency['B'] = 3
maxCount = Math.max(maxCount, charFrequency['B']) → maxCount = 3
Check if the window is valid:
(6 - 1 + 1) - 3 > 2 → 3 > 2 (true)
Window is invalid, move left to shrink the window:
Decrement charFrequency['B'] → charFrequency['B'] = 2
left++ → left = 2
Check if the window is valid again:
(6 - 2 + 1) - 3 > 2 → 2 > 2 (false)
Update maxLen = Math.max(maxLen, right - left + 1) → maxLen = 5
Current State:
charFrequency = [A: 2, B: 2, C: 1, others: 0]
maxLen = 5, maxCount = 3, left = 2
Iteration 8: right = 7, curr = 'C'
charFrequency['C']++ → charFrequency['C'] = 2
maxCount = Math.max(maxCount, charFrequency['C']) → maxCount = 3 (unchanged)
Check if the window is valid:
(7 - 2 + 1) - 3 > 2 → 3 > 2 (true)
Window is invalid, move left to shrink the window:
Decrement charFrequency['C'] → charFrequency['C'] = 1
left++ → left = 3
Check if the window is valid again:
(7 - 3 + 1) - 3 > 2 → 2 > 2 (false)
Update maxLen = Math.max(maxLen, right - left + 1) → maxLen = 5
Final State:
charFrequency = [A: 2, B: 2, C: 1, others: 0]
maxLen = 5, maxCount = 3, left = 3
The maximum length of the substring with repeating characters is 5.
Optimal Code for all languages
1. C++ Try on Compiler
#include <iostream>
#include <vector>
#include <algorithm>
using namespace std;
int longestSubstring(string s, int k) {
int left = 0;
int n = s.length();
int maxLen = 0;
int maxCount = 0;
vector<int> charFrequency(26, 0); // Array to store frequencies of uppercase characters
for (int right = 0; right < n; right++) {
char curr = s[right];
charFrequency[curr - 'A']++;
maxCount = max(maxCount, charFrequency[curr - 'A']);
// If the number of changes exceeds k, shrink the window
if (right - left + 1 - maxCount > k) {
charFrequency[s[left] - 'A']--;
left++;
}
// Update the maximum valid window size
maxLen = max(maxLen, right - left + 1);
}
return maxLen;
}
2. Java Try on Compiler
import java.util.Scanner;
class Solution {
// Function to find the length of the longest substring with the same letter after at most k changes
public static int longestSubstring(String s, int k) {
int left = 0;
int n = s.length();
int maxLen = 0;
int maxCount = 0;
int[] charFrequency = new int[26]; // Array to store frequencies of uppercase letters
for (int right = 0; right < n; right++) {
char curr = s.charAt(right);
int index = curr - 'A'; // Map 'A'-'Z' to 0-25
charFrequency[index]++; // Increment frequency of the current character
maxCount = Math.max(maxCount, charFrequency[index]); // Update maxCount with the most frequent character in the window
// If the number of characters to change exceeds k, shrink the window
if (right - left + 1 - maxCount > k) {
charFrequency[s.charAt(left) - 'A']--; // Decrease the frequency of the character at the left pointer
left++; // Shrink the window
}
// Update the maximum length of valid window
maxLen = Math.max(maxLen, right - left + 1);
}
return maxLen;
}
}
3. Python Try on Compiler
def longest_substring(s, k):
left = 0
n = len(s)
max_len = 0
max_count = 0
char_frequency = [0] * 26 # Array to store frequencies of uppercase letters
for right in range(n):
curr = s[right]
char_frequency[ord(curr) - ord('A')] += 1
max_count = max(max_count, char_frequency[ord(curr) - ord('A')])
# If the number of changes exceeds k, shrink the window
if right - left + 1 - max_count > k:
char_frequency[ord(s[left]) - ord('A')] -= 1
left += 1
# Update the maximum valid window size
max_len = max(max_len, right - left + 1)
return max_len4. JavaScript Try on Compiler
const readline = require('readline');
const rl = readline.createInterface({
input: process.stdin,
output: process.stdout
});
function canMakeSameWithKChanges(substring, k) {
let charFrequency = new Array(26).fill(0); // Array to store frequencies of uppercase letters
let maxFrequency = 0; // To track the maximum frequency of any character in the substring
// Calculate the frequency of each character in the substring
for (let i = 0; i < substring.length; i++) {
const index = substring.charCodeAt(i) - 'A'.charCodeAt(0); // Map 'A'-'Z' to 0-25
charFrequency[index]++;
maxFrequency = Math.max(maxFrequency, charFrequency[index]);
}
// Calculate changes needed
let changesNeeded = substring.length - maxFrequency;
return changesNeeded <= k; // Check if changes required are within allowed limit
}
function longestSubstring(s, k) {
let maxLength = 0;
// Iterate over all possible substrings
for (let i = 0; i < s.length; i++) {
for (let j = i; j < s.length; j++) {
let substring = s.substring(i, j + 1); // Get substring
if (canMakeSameWithKChanges(substring, k)) {
maxLength = Math.max(maxLength, substring.length); // Update max length
}
}
}
return maxLength;
}
Time Complexity : O(n)
Outer Loop:
The algorithm uses a single loop that iterates over the string s with n characters. This loop runs in O(n) time.
Inner Operations:
Inside the loop, the operations to update the frequency of characters, check conditions, and adjust the left pointer are all O(1) operations.
Combining these, the overall time complexity is: O(n), where n is the length of the input string s.
Space Complexity: O(n)
Auxiliary Space Complexity
Auxiliary space refers to the extra space used by the algorithm that is not part of the input.
An array of size 26 is used to store the frequency of each character. This space does not depend on the size of the input string, so it is constant space.
Other variables used in the algorithm (like left, maxLen, maxCount, etc.) are a fixed number of integers and do not grow with input size.
Thus, the auxiliary space complexity is: O(1), as the space used is constant and does not depend on the size of the input.
Total Space Complexity
The input string s is stored in memory, which takes O(n) space.
The auxiliary space from the character frequency array is O(1).
Thus, the total space complexity is: O(n), due to the input string.
Learning Tip
Since, we have implemented using a hash-table, try the implementation using a HashMap.
- Substring with Concatenation of All Words
- Minimum Window Substring
- Substrings of Size Three with Distinct Characters
- Max Consecutive Ones III