Groups of Special-Equivalent Strings Solution In C++/Python/Java/Javascript
Problem Statement:
You are given an array of strings of the same length words.
In one move, you can swap any two even indexed characters or any two odd indexed characters of a string words[i].
Two strings words[i] and words[j] are special-equivalent if after any number of moves, words[i] == words[j].
For example, words[i] = "zzxy" and words[j] = "xyzz" are special-equivalent because we may make the moves "zzxy" -> "xzzy" -> "xyzz".
A group of special-equivalent strings from words is a non-empty subset of words such that:
1. Every pair of strings in the group are special equivalent, and
2. The group is the largest size possible (i.e., there is not a string words[i] not in the group such that words[i] is special-equivalent to every string in the group).
Return the number of groups of special-equivalent strings from words.
Examples:
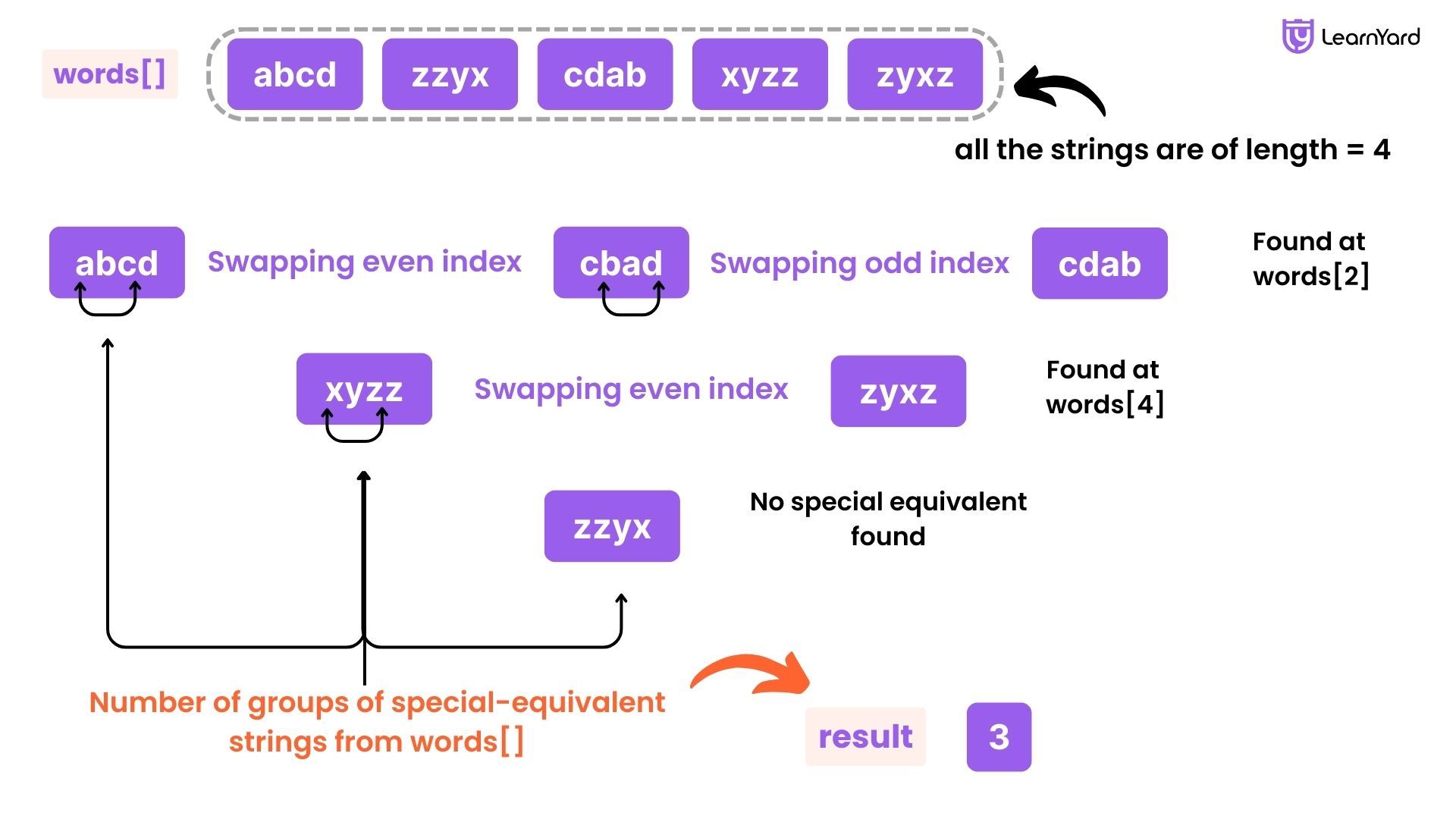
Input: words = ["abcd","cdab","cbad","xyzz","zzxy","zzyx"]
Output: 3
Explanation: One group is ["abcd", "cdab", "cbad"], since they are all pairwise special equivalent, and none of the other strings is all pairwise special equivalent to these.
The other two groups are ["xyzz", "zzxy"] and ["zzyx"].
Note that in particular, "zzxy" is not special equivalent to "zzyx".
Input: words = ["abc","acb","bac","bca","cab","cba"]
Output: 3
Explanation: One group is ["abc", "acb", "bac", "bca", "cab", "cba"], since they are all pairwise special equivalent.
Constraints:
1 <= words.length <= 1000
1 <= words[i].length <= 20
words[i] consist of lowercase English letters.
All the strings are of the same length.
Brute Force Approach
Okay, so here's the thought process:
What comes to mind after reading the problem statement?
We need to make a group of words where, by swapping odd indexed elements and even indexed elements separately, the words become equivalent.
So how can we do that?
First, let's observe something:
We can only swap the even indexed elements with each other and odd indexed elements with each other. This means that if two strings are special equivalent, their odd indexed elements and even indexed elements must be the same. They can be in different orders, but they must be the same elements.
For example, consider the words "abcd" and "cdab":
- Odd indexed elements in "abcd" are 'a' and 'c'.
- Odd indexed elements in "cdab" are 'c' and 'a'. They are the same elements, just in a different order (like 'a', 'c' vs 'c', 'a').
- Even indexed elements in "abcd" are 'b' and 'd'.
- Even indexed elements in "cdab" are 'd' and 'b'. Again, these elements are the same, but reordered.
Now, we understand that the odd indexed elements and even indexed elements in two special equivalent strings must be the same, regardless of the order.
Now we need to compare the odd indexed and even indexed elements of two strings to determine if they are special equivalent or not.
But how can we compare the odd indexed and even indexed elements efficiently?
Great question!
Is there a technique to compare two sets of elements, even if they are ordered differently?
Yes, you're right—sorting is the perfect solution! If we sort the odd indexed elements and even indexed elements, they will be ordered in the same way. Once sorted, we can simply compare the sorted sets directly. If both the odd indexed elements and even indexed elements match, we can confidently say that the two strings are special equivalent.
Now, once the elements are sorted, we can simply check if the odd indexed elements and even indexed elements of two strings are equal or not. If they match, we can declare the strings as special equivalent.
To make things simpler, instead of keeping two separate strings for even and odd characters, why don’t we just combine them into one? We can sort the even characters and odd characters separately, and then just concatenate them into a single string. This way, we only need to compare one string instead of two for each word.
Think about it like this: if the even parts of two words are the same and the odd parts are the same, then combining them will also be the same. For example, if even1 == even2 and odd1 == odd2, then even1 + odd1 == even2 + odd2.
This combined string is called the canonical form. It’s like a unique signature for each word that makes it super easy to check if two words belong to the same group. The canonical form is essentially a sorted representation of the even and odd parts combined.
How can we do it?
Here's how we can implement it:
- Traverse the array of strings and, for each string, collect its odd and even indexed elements into two separate strings called even and odd.
- Sort both the even and odd strings for each word.
- To compare these efficiently, store the concatenation of the sorted even and odd strings (i.e., even + odd). This concatenated string is referred to as the canonical form.
- Compare the canonical forms of all strings: For each string, compare its canonical form with the canonical forms of other strings. If they match, we group them together.
By using the canonical form, we simplify the process of comparing strings by reducing it to comparing their sorted odd and even indexed characters in a unified manner.
Let's understand with an example:
Input: words = ["abcd", "cdab", "cbad", "xyzz", "zzxy", "zzyx"]
- Separate odd and even indexed characters:
"abcd": even = "ac", odd = "bd"
"cdab": even = "ca", odd = "db"
"cbad": even = "ca", odd = "bd"
"xyzz": even = "xz", odd = "yz"
"zzxy": even = "zx", odd = "zy"
"zzyx": even = "zy", odd = "zx" - Sort even and odd indexed characters:
"abcd": even = "ac", odd = "bd" → canonical form = "acbd"
"cdab": even = "ac", odd = "bd" → canonical form = "acbd"
"cbad": even = "ac", odd = "bd" → canonical form = "acbd"
"xyzz": even = "xz", odd = "yz" → canonical form = "xzyz"
"zzxy": even = "xz", odd = "yz" → canonical form = "xzyz"
"zzyx": even = "yz", odd = "xz" → canonical form = "xzyz" - Group by canonical form:
Group 1: ["abcd", "cdab", "cbad"]
Group 2: ["xyzz", "zzxy"]
Group 3: ["zzyx"] - Output: 3 groups.
How to code it up:
- Initialize variables: Create an array for canonical forms and a visited array to track groups.
- Loop through words: For each word, initialize two strings: one for even indices and one for odd indices.
- Collect characters: Traverse the word, separating even and odd indexed characters into their respective strings.
- Sort characters: Sort both the even and odd indexed strings.
- Form canonical string: Concatenate the sorted even and odd strings and store it as the canonical form.
- Group by canonical form: Compare the canonical form of the current word with the forms of previously processed words.
- If the canonical form is already in the list of processed canonical forms (or groups), mark the word as already visited. If not, it forms a new group.
- Count unique groups: Count the number of distinct canonical forms that represent the number of unique groups.
- Return result: Return the count of groups.
Code Implementation
1. C++ Try on Compiler
class Solution {
public:
int numSpecialEquivGroups(vector<string>& words) {
// Total number of words
int numWords = words.size();
// Stores canonical forms of all words
vector<string> canonicalForms(numWords);
// Tracks if a word is already grouped
vector<bool> isVisited(numWords, false);
// Count of special-equivalent groups
int numGroups = 0;
// Step 1: Compute the canonical form for each word
for (int i = 0; i < numWords; i++) {
// To store even-indexed and odd-indexed characters
string evenChars, oddChars;
for (int j = 0; j < words[i].size(); j++) {
// Add even-indexed character
if (j % 2 == 0)
evenChars += words[i][j];
// Add odd-indexed character
else
oddChars += words[i][j];
}
// Sort the even characters
sort(evenChars.begin(), evenChars.end());
// Sort the odd characters
sort(oddChars.begin(), oddChars.end());
// Combine sorted even and odd characters as the canonical form
canonicalForms[i] = evenChars + oddChars;
}
// Step 2: Group words based on their canonical forms
for (int i = 0; i < numWords; i++) {
// Skip if the word is already part of a group
if (isVisited[i])
continue;
// Start a new group
numGroups++;
// Mark the current word as visited
isVisited[i] = true;
// Canonical form of the current word
string currentForm = canonicalForms[i];
for (int j = i + 1; j < numWords; j++) {
// Skip already grouped words
if (isVisited[j])
continue;
// Canonical form of the other word
string otherForm = canonicalForms[j];
// Mark as visited if they are in the same group
if (currentForm == otherForm) {
isVisited[j] = true;
}
}
}
// Return the total number of groups
return numGroups;
}
};
2. Java Try on Compiler
class Solution {
public int numSpecialEquivGroups(String[] words) {
// Total number of words
int numWords = words.length;
// Stores canonical forms of all words
String[] canonicalForms = new String[numWords];
// Tracks if a word is already grouped
boolean[] isVisited = new boolean[numWords];
// Count of special-equivalent groups
int numGroups = 0;
// Step 1: Compute the canonical form for each word
for (int i = 0; i < numWords; i++) {
// To store even-indexed and odd-indexed characters
StringBuilder evenChars = new StringBuilder(), oddChars = new StringBuilder();
for (int j = 0; j < words[i].length(); j++) {
// Add even-indexed character
if (j % 2 == 0)
evenChars.append(words[i].charAt(j));
// Add odd-indexed character
else
oddChars.append(words[i].charAt(j));
}
// Sort the even characters
char[] evenArray = evenChars.toString().toCharArray();
Arrays.sort(evenArray);
// Sort the odd characters
char[] oddArray = oddChars.toString().toCharArray();
Arrays.sort(oddArray);
// Combine sorted even and odd characters as the canonical form
canonicalForms[i] = new String(evenArray) + new String(oddArray);
}
// Step 2: Group words based on their canonical forms
for (int i = 0; i < numWords; i++) {
// Skip if the word is already part of a group
if (isVisited[i])
continue;
// Start a new group
numGroups++;
// Mark the current word as visited
isVisited[i] = true;
// Canonical form of the current word
String currentForm = canonicalForms[i];
for (int j = i + 1; j < numWords; j++) {
// Skip already grouped words
if (isVisited[j])
continue;
// Canonical form of the other word
String otherForm = canonicalForms[j];
// Mark as visited if they are in the same group
if (currentForm.equals(otherForm)) {
isVisited[j] = true;
}
}
}
// Return the total number of groups
return numGroups;
}
}
3. Python Try on Compiler
class Solution:
def numSpecialEquivGroups(self, words):
# Total number of words
numWords = len(words)
# Stores canonical forms of all words
canonicalForms = [None] * numWords
# Tracks if a word is already grouped
isVisited = [False] * numWords
# Count of special-equivalent groups
numGroups = 0
# Step 1: Compute the canonical form for each word
for i in range(numWords):
# To store even-indexed and odd-indexed characters
evenChars, oddChars = "", ""
for j in range(len(words[i])):
# Add even-indexed character
if j % 2 == 0:
evenChars += words[i][j]
# Add odd-indexed character
else:
oddChars += words[i][j]
# Sort the even characters
evenChars = ''.join(sorted(evenChars))
# Sort the odd characters
oddChars = ''.join(sorted(oddChars))
# Combine sorted even and odd characters as the canonical form
canonicalForms[i] = evenChars + oddChars
# Step 2: Group words based on their canonical forms
for i in range(numWords):
# Skip if the word is already part of a group
if isVisited[i]:
continue
# Start a new group
numGroups += 1
# Mark the current word as visited
isVisited[i] = True
# Canonical form of the current word
currentForm = canonicalForms[i]
for j in range(i + 1, numWords):
# Skip already grouped words
if isVisited[j]:
continue
# Canonical form of the other word
otherForm = canonicalForms[j]
# Mark as visited if they are in the same group
if currentForm == otherForm:
isVisited[j] = True
# Return the total number of groups
return numGroups
4. Javascript Try on Compiler
var numSpecialEquivGroups = function(words) {
// Total number of words
let numWords = words.length;
// Stores canonical forms of all words
let canonicalForms = new Array(numWords);
// Tracks if a word is already grouped
let isVisited = new Array(numWords).fill(false);
// Count of special-equivalent groups
let numGroups = 0;
// Step 1: Compute the canonical form for each word
for (let i = 0; i < numWords; i++) {
// To store even-indexed and odd-indexed characters
let evenChars = "", oddChars = "";
for (let j = 0; j < words[i].length; j++) {
// Add even-indexed character
if (j % 2 === 0)
evenChars += words[i][j];
// Add odd-indexed character
else
oddChars += words[i][j];
}
// Sort the even characters
evenChars = evenChars.split('').sort().join('');
// Sort the odd characters
oddChars = oddChars.split('').sort().join('');
// Combine sorted even and odd characters as the canonical form
canonicalForms[i] = evenChars + oddChars;
}
// Step 2: Group words based on their canonical forms
for (let i = 0; i < numWords; i++) {
// Skip if the word is already part of a group
if (isVisited[i])
continue;
// Start a new group
numGroups++;
// Mark the current word as visited
isVisited[i] = true;
// Canonical form of the current word
let currentForm = canonicalForms[i];
for (let j = i + 1; j < numWords; j++) {
// Skip already grouped words
if (isVisited[j])
continue;
// Canonical form of the other word
let otherForm = canonicalForms[j];
// Mark as visited if they are in the same group
if (currentForm === otherForm) {
isVisited[j] = true;
}
}
}
// Return the total number of groups
return numGroups;
};
Time Complexity: O(n²)
Let’s break down the time complexity of this approach step by step.
- Computing Canonical Forms:
First, we iterate through all the words, which takes O(n) time, where n is the number of words.
Next, for each word, we go through each character. This takes O(m) time, where m is the length of the longest word, because we need to inspect every character.
Then, we need to sort the even and odd characters separately for each word. Sorting each of those strings takes O(m log m) time. Why? Because sorting a string of length m requires O(m log m) time, and we’re doing that twice — once for the even characters and once for the odd characters.
Finally, after sorting, we combine the even and odd parts into a single string. This step takes O(m) time because concatenating two strings of length m/2 (or so) is linear in time.
So, when we put it all together, the time complexity for computing the canonical form for each word is dominated by the sorting step. That gives us a time complexity of O(m log m) for each word.
Thus, the total time complexity for this part is:
O(n * m log m), where n is the number of words and m is the length of each word. - Grouping Words:
Now, let’s look at the second part where we group the words based on their canonical forms.
First, we iterate through all the words, which takes O(n) time, where n is the number of words.
Then, for each word, we check against the remaining words to see if they belong to the same group. In the worst case, we might need to compare the current word with every other word that hasn't been grouped yet. This gives us O(n) time for each word to check its group membership.
Since this happens for every word, we end up with a nested loop where for each word, we compare it with all other words.
This results in a O(n²) time complexity in the worst case, because we’re comparing each pair of words once
Overall Time Complexity:
- O(n * m log m) for computing canonical forms.
- O(n²) for grouping words based on canonical forms.
Since the O(n²) term dominates the overall complexity (especially when m is relatively small), the overall time complexity is: O(n²), where n is the number of words.
Space Complexity: O(n * m)
Auxiliary Space: O(n * m)
Explanation: We create a vector of strings, canonicalForms, of size n to store the canonical form of each word. This takes O(n * m) space, as each string will have a length of m.
Visited Array: We create a boolean vector, isVisited, of size n to track if a word has been grouped. This takes O(n) space.
Even and Odd Character Strings: For each word, we store two strings, evenChars and oddChars, to hold the even and odd indexed characters, respectively. Each of these strings takes O(m) space, but they are only used during the computation of the canonical form and will not exist simultaneously for all words at once.
Thus, the total auxiliary space is the sum of the space for:
canonicalForms: O(n * m)
isVisited: O(n)
evenChars and oddChars: O(m) (for each word, but we don't need to store them all at once)
Therefore, the auxiliary space complexity is:
O(n * m).
Total Space Complexity: O(n * m)
Explanation: The input is a vector of strings of length n, where each string has length m. This takes O(n * m) space.We have computed the auxiliary space as O(n * m).
Thus, the total space complexity is: O(n * m).
Will Brute Force Work Against the Given Constraints?
For the current solution, the time complexity is O(n²), where n is the number of words in the input. Given the constraints of 1 ≤ words.length ≤ 1000 and 1 ≤ words[i].length ≤ 20, the solution is expected to execute within the given time limits.
Since O(n²) results in a maximum of 10⁶ operations (for n = 1000), the solution is expected to work well for individual test cases under these constraints, typically allowing around 1–2 seconds for execution.
In most competitive programming environments, problems can handle up to 10⁶ operations per test case. Therefore, for n ≤ 1000, the solution is efficient enough. However, when multiple test cases are involved, the total number of operations could easily approach 10⁶ operations, and the solution ensures that even with n = 1000 and multiple test cases, the time complexity remains manageable.
Thus, with O(n²) operations per test case, the solution handles up to 10⁶ operations efficiently, meeting typical competitive programming constraints.
Can we optimize it?
We previously ordered the even and odd indexed elements of each string, sorted them, and maintained a canonical form of all these strings. Then, we grouped all the strings that had equal canonical forms by iterating over all strings, which resulted in an O(n²) time complexity.
Now, can we optimize this approach?
Yes, we can!
The idea is that if two canonical forms are equal, it means they will belong to the same group. So, instead of iterating over all strings repeatedly to find equal canonical forms, we can simply track how many unique canonical forms there are.
We can store the count of unique canonical forms as we traverse the strings. If we encounter a string whose canonical form has already been encountered, we can skip it, as we only need to count unique strings to determine the number of groups.
Which data structure can help us with this?
We need to track unique values efficiently.
Yes, you're right! We can use a hash set.
A hash set is a data structure that automatically ensures only unique values are stored. When we try to add an element to the set, it first checks if that element already exists. If the element is already in the set, it will not be added again, ensuring no duplicates. By using this property, we can efficiently track the unique canonical forms of strings.
As we iterate through the list of strings and compute their canonical forms, we add each canonical form to the hash set. If the canonical form already exists, it won’t be added again, meaning we are only keeping unique canonical forms.
At the end, the size of the hash set represents the total number of unique groups, as each unique canonical form corresponds to a distinct group of special-equivalent strings.
This approach optimizes the time complexity and avoids the need for nested loops to compare canonical forms, reducing the overall time complexity.
Let's understand with an example:
Input: words = ["abcd", "cdab", "cbad", "xyzz", "zzxy", "zzyx"]
Step 1: Compute the canonical forms and add to the hash set
- For "abcd":
Even-indexed characters: "a" and "c"
Odd-indexed characters: "b" and "d"
Sorted even characters: "ac"
Sorted odd characters: "bd"
Canonical form: "acbd"
Add "acbd" to the hash set. - For "cdab":
Even-indexed characters: "c" and "a"
Odd-indexed characters: "d" and "b"
Sorted even characters: "ac"
Sorted odd characters: "bd"
Canonical form: "acbd"
"acbd" is already in the hash set (no duplicates). - For "cbad":
Even-indexed characters: "c" and "a"
Odd-indexed characters: "b" and "d"
Sorted even characters: "ac"
Sorted odd characters: "bd"
Canonical form: "acbd"
"acbd" is already in the hash set. - For "xyzz":
Even-indexed characters: "x" and "z"
Odd-indexed characters: "y" and "z"
Sorted even characters: "xz"
Sorted odd characters: "yz"
Canonical form: "xzyz"
Add "xzyz" to the hash set. - For "zzxy":
Even-indexed characters: "z" and "x"
Odd-indexed characters: "z" and "y"
Sorted even characters: "xz"
Sorted odd characters: "yz"
Canonical form: "xzyz"
"xzyz" is already in the hash set. - For "zzyx":
Even-indexed characters: "z" and "y"
Odd-indexed characters: "z" and "x"
Sorted even characters: "yz"
Sorted odd characters: "xz"
Canonical form: "yzxz"
Add "yzxz" to the hash set.
Step 2: Count the unique canonical forms in the hash set
- Final hash set: {"acbd", "xzyz", "yzxz"}
- The number of unique canonical forms is 3.
Output: 3 groups of special-equivalent strings.
How to code it up:
- Initialize an empty hash set to store unique canonical forms.
- For each word in the input array, split it into even and odd indexed characters.
- Sort the even and odd indexed characters.
- Concatenate the sorted even and odd characters to form the canonical form.
- Add the canonical form to the hash set.
- Return the size of the hash set as the number of unique groups.
Code Implementation
1. C++ Try on Compiler
class Solution {
public:
int numSpecialEquivGroups(vector<string>& words) {
// Create a set to store unique canonical forms of the strings
unordered_set<string> uniqueGroups;
// Iterate over each word in the input list
for (const string& word : words) {
// Variables to store even and odd indexed characters separately
string evenChars, oddChars;
// Split the string into even and odd indexed characters
for (int i = 0; i < word.size(); i++) {
if (i % 2 == 0)
evenChars += word[i]; // Add even-indexed character to evenChars
else
oddChars += word[i]; // Add odd-indexed character to oddChars
}
// Sort the characters in evenChars to create a canonical form
sort(evenChars.begin(), evenChars.end());
// Sort the characters in oddChars to create a canonical form
sort(oddChars.begin(), oddChars.end());
// Combine the sorted even and odd parts into a single string (canonical form)
// Insert the combined form into the set to track unique groups
uniqueGroups.insert(evenChars + oddChars);
}
// The size of the set represents the number of unique groups
return uniqueGroups.size();
}
};
2. Java Try on Compiler
import java.util.HashSet;
import java.util.Set;
class Solution {
public int numSpecialEquivGroups(String[] words) {
// Create a set to store unique canonical forms of the strings
Set<String> uniqueGroups = new HashSet<>();
// Iterate over each word in the input list
for (String word : words) {
// Variables to store even and odd indexed characters separately
StringBuilder evenChars = new StringBuilder(), oddChars = new StringBuilder();
// Split the string into even and odd indexed characters
for (int i = 0; i < word.length(); i++) {
if (i % 2 == 0)
evenChars.append(word.charAt(i)); // Add even-indexed character to evenChars
else
oddChars.append(word.charAt(i)); // Add odd-indexed character to oddChars
}
// Sort the characters in evenChars and oddChars to create a canonical form
char[] evenArray = evenChars.toString().toCharArray();
char[] oddArray = oddChars.toString().toCharArray();
java.util.Arrays.sort(evenArray);
java.util.Arrays.sort(oddArray);
// Combine the sorted even and odd parts into a single string (canonical form)
// Insert the combined form into the set to track unique groups
uniqueGroups.add(new String(evenArray) + new String(oddArray));
}
// The size of the set represents the number of unique groups
return uniqueGroups.size();
}
}
3. Python Try on Compiler
class Solution:
def numSpecialEquivGroups(self, words):
# Create a set to store unique canonical forms of the strings
unique_groups = set()
# Iterate over each word in the input list
for word in words:
# Variables to store even and odd indexed characters separately
even_chars, odd_chars = [], []
# Split the string into even and odd indexed characters
for i, char in enumerate(word):
if i % 2 == 0:
even_chars.append(char) # Add even-indexed character to even_chars
else:
odd_chars.append(char) # Add odd-indexed character to odd_chars
# Sort the characters in even_chars and odd_chars to create a canonical form
even_chars.sort()
odd_chars.sort()
# Combine the sorted even and odd parts into a single string (canonical form)
# Insert the combined form into the set to track unique groups
unique_groups.add("".join(even_chars) + "".join(odd_chars))
# The size of the set represents the number of unique groups
return len(unique_groups)
4. Javascript Try on Compiler
var numSpecialEquivGroups = function(words) {
// Create a set to store unique canonical forms of the strings
const uniqueGroups = new Set();
// Iterate over each word in the input list
for (let word of words) {
// Variables to store even and odd indexed characters separately
let evenChars = [], oddChars = [];
// Split the string into even and odd indexed characters
for (let i = 0; i < word.length; i++) {
if (i % 2 === 0)
evenChars.push(word[i]); // Add even-indexed character to evenChars
else
oddChars.push(word[i]); // Add odd-indexed character to oddChars
}
// Sort the characters in evenChars and oddChars to create a canonical form
evenChars.sort();
oddChars.sort();
// Combine the sorted even and odd parts into a single string (canonical form)
// Insert the combined form into the set to track unique groups
uniqueGroups.add(evenChars.join('') + oddChars.join(''));
}
// The size of the set represents the number of unique groups
return uniqueGroups.size;
};
Time Complexity: O(n * m log m)
For each word in the words array, we need to iterate through the string, which takes O(n) time, where n is the number of words in the array.
For each word, we then iterate through each character and separate them into even and odd indexed characters, which takes O(m) time, where m is the length of each word (with a maximum length of 20).
After that, we sort the even and odd indexed characters, and sorting each group takes O(m log m) time. Since sorting is done twice—once for the even characters and once for the odd characters—the total time complexity for sorting is O(m log m).
Finally, the operation of adding the concatenated canonical form (even + odd) into the hash set takes O(1) on average.
Therefore, for each word, the dominant operations are splitting characters, sorting the even and odd indexed characters, and inserting into the hash set, which results in a total complexity of O(m log m) per word.
Since there are n words, the overall time complexity is O(n * m log m), where n is the number of words (up to 1000) and m is the length of each word (up to 20). Thus, the final time complexity of the solution is O(n * m log m).
Space Complexity: O(n * m)
Auxiliary Space: O(n * m)
Explanation: O(m) per word is required to store the evenChars and oddChars strings, where m is the length of each word.
Sorting the characters requires an additional O(m) space for sorting both evenChars and oddChars arrays.
O(n * m) space is used by the unordered_set to store the canonical forms, where n is the number of words and m is the maximum length of each word.
Auxiliary space for storing even and odd characters, sorting, and canonical form storage is O(n * m).
Total Space Complexity: O(n * m)
Explanation: Input storage for the words array is O(n * m).
Learning Tip
Now we have successfully tackled this problem, let's try these similar problems.
Given a string s, partition the string into one or more substrings such that the characters in each substring are unique. That is, no letter appears in a single substring more than once.Return the minimum number of substrings in such a partition.Note that each character should belong to exactly one substring in a partition.
2. Word Subsets
Here’s the problem description with bold formatting as per your request:
You are given two string arrays words1 and words2.
A string b is a subset of string a if every letter in b occurs in a including multiplicity.
For example, "wrr" is a subset of "warrior" but is not a subset of "world".
A string a from words1 is universal if for every string b in words2, b is a subset of a.
Return an array of all the universal strings in words1. You may return the answer in any order.