Count Beautiful Substrings II Solution In C++/Java/Python/JS
Problem Description:
You are given a string s and a positive integer k.
Let vowels and consonants be the number of vowels and consonants in a string.
A string is beautiful if:
vowels == consonants.
(vowels * consonants) % k == 0, in other terms the multiplication of vowels and consonants is divisible by k.
Return the number of non-empty beautiful substrings in the given string s.
A substring is a contiguous sequence of characters in a string.
Vowel letters in English are 'a', 'e', 'i', 'o', and 'u'.
Consonant letters in English are every letter except vowels.
Examples:
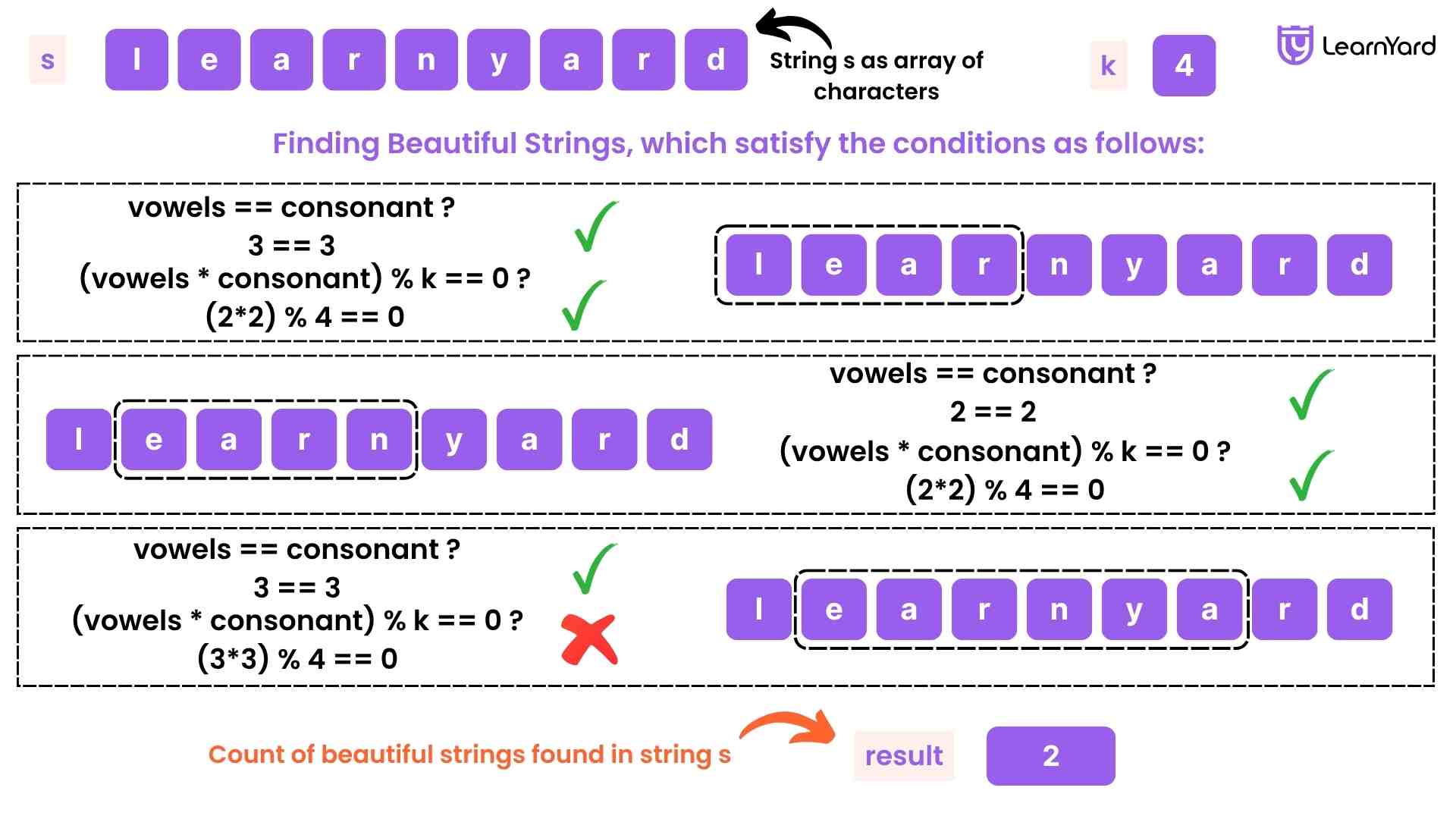
Input: s = "baeyh", k = 2
Output: 2
Explanation: There are 2 beautiful substrings in the given string.
- Substring "aeyh", vowels = 2 (["a", "e"]), consonants = 2 (["y", "h"]).
You can see that string "aeyh" is beautiful as vowels == consonants and (vowels * consonants) % k == 0. - Substring "baey", vowels = 2 (["a", "e"]), consonants = 2 (["b", "y"]).
You can see that string "baey" is beautiful as vowels == consonants and (vowels * consonants) % k == 0.
It can be shown that there are only 2 beautiful substrings in the given string.
Input: s = "abba", k = 1
Output: 3
Explanation: There are 3 beautiful substrings in the given string.
- Substring "ab", vowels = 1 (["a"]), consonants = 1 (["b"]).
- Substring "ba", vowels = 1 (["a"]), consonants = 1 (["b"]).
- Substring "abba", vowels = 2 (["a", "a"]), consonants = 2 (["b", "b"]).
It can be shown that there are only 3 beautiful substrings in the given string.
Input: s = "bcdf", k = 1
Output: 0
Explanation: There are no beautiful substrings in the given string.
Constraints:
1 <= s.length <= 5 * 10⁴
1 <= k <= 1000
s consists of only English lowercase letters.
Brute Force Approach
When we read the problem statement, the first idea that comes to mind is simple:
Iterate through all the substrings and count the number of vowels and consonants in each substring. If they are equal and (vowels * consonants) % k == 0, then increase the counter of answer. Return answer at the end.
How to do it?
To solve the problem, you can iterate through all the substrings and calculate the number of vowels and consonants for each. Here's the step-by-step flow:
- Initialize a counter, answer, to 0. This will store the count of beautiful substrings.
- Iterate through all possible starting indices i of substrings in the string s.
- For each starting index i, iterate through all possible ending indices j (from i to the end of the string).
- For each substring, do the following:
- Count the number of vowels and consonants in the substring.
- Check if the number of vowels equals the number of consonants.
- If they are equal, check if (vowels * consonants) % k == 0.
- If both conditions are satisfied, increment the answer counter.
- After completing the iteration, return answer.
This approach ensures that every substring is evaluated for the conditions, and the count of beautiful substrings is accurately computed.
Let's understand it with and example:
Let's dry run on Input: s = "baeyh", k = 2
- Substring: "b" → Vowels = 0, Consonants = 1 → Not beautiful.
- Substring: "ba" → Vowels = 1, Consonants = 1 → Not divisible by k.
- Substring: "bae" → Vowels = 2, Consonants = 1 → Not equal.
- Substring: "baey" → Vowels = 2, Consonants = 2 → Beautiful (4 % 2 == 0).
- Substring: "baeyh" → Vowels = 2, Consonants = 3 → Not equal.
- Substring: "a" → Vowels = 1, Consonants = 0 → Not beautiful.
- Substring: "ae" → Vowels = 2, Consonants = 0 → Not equal.
- Substring: "aey" → Vowels = 2, Consonants = 1 → Not equal.
- Substring: "aeyh" → Vowels = 2, Consonants = 2 → Beautiful (4 % 2 == 0).
- Substring: "e" → Vowels = 1, Consonants = 0 → Not beautiful.
- Substring: "ey" → Vowels = 1, Consonants = 1 → Not divisible by k.
- Substring: "eyh" → Vowels = 1, Consonants = 2 → Not equal.
- Substring: "y" → Vowels = 0, Consonants = 1 → Not beautiful.
- Substring: "yh" → Vowels = 0, Consonants = 2 → Not equal.
- Substring: "h" → Vowels = 0, Consonants = 1 → Not beautiful.
Answer: 2 beautiful substrings → "baey" and "aeyh".
How to code it up:
- Define isVowel to check if a character is a vowel.
- Create beautifulSubstrings function with parameters s and k.
- Initialize n as the length of s and ans as 0.
- Use an outer loop to iterate starting indices i of substrings.
- Use an inner loop to iterate ending indices j for substrings starting at i.
- Count vowels and consonants for substring s[i:j+1] using isVowel.
- Check if vowels == consonants and (vowels * consonants) % k == 0.
- Increment ans if conditions are satisfied.
- Return ans after the loops.
Code Implementation
1. C++ Try on Compiler
class Solution {
// Helper function to check if a character is a vowel
bool isVowel(char ch)
{
return ch == 'a' || ch == 'e' || ch == 'i' || ch == 'o' || ch == 'u';
}
public:
// Function to count the number of beautiful substrings
int beautifulSubstrings(string s, int k)
{
// Get the length of the string
int n = s.length();
// Initialize the answer counter
int ans = 0;
// Outer loop to iterate over starting indices of substrings
for(int i = 0; i < n; i++)
{
// Initialize the vowel count for the current substring
int vowels = 0;
// Initialize the consonant count for the current substring
int consonants = 0;
// Inner loop to iterate over ending indices of substrings
for(int j = i; j < n; j++) {
// Check if the current character is a vowel
if(isVowel(s[j]))
// Increment vowel count
vowels++;
else
// Increment consonant count
consonants++;
// Check if the substring satisfies the conditions for being beautiful
if(vowels == consonants && (vowels * consonants) % k == 0)
ans++; // Increment the answer counter if conditions are met
}
}
// Return the total count of beautiful substrings
return ans;
}
};2. Java Try on Compiler
class Solution {
// Helper function to check if a character is a vowel
boolean isVowel(char ch) {
return ch == 'a' || ch == 'e' || ch == 'i' || ch == 'o' || ch == 'u';
}
public int beautifulSubstrings(String s, int k) {
// Get the length of the string
int n = s.length();
// Initialize the answer counter
int ans = 0;
// Outer loop to iterate over starting indices of substrings
for (int i = 0; i < n; i++) {
// Initialize the vowel count for the current substring
int vowels = 0;
// Initialize the consonant count for the current substring
int consonants = 0;
// Inner loop to iterate over ending indices of substrings
for (int j = i; j < n; j++) {
// Check if the current character is a vowel
if (isVowel(s.charAt(j)))
// Increment vowel count
vowels++;
else
// Increment consonant count
consonants++;
// Check if the substring satisfies the conditions for being beautiful
if (vowels == consonants && (vowels * consonants) % k == 0)
ans++; // Increment the answer counter if conditions are met
}
}
// Return the total count of beautiful substrings
return ans;
}
}3. Python Try on Compiler
class Solution:
# Helper function to check if a character is a vowel
def isVowel(self, ch):
return ch in ['a', 'e', 'i', 'o', 'u']
def beautifulSubstrings(self, s, k):
# Get the length of the string
n = len(s)
# Initialize the answer counter
ans = 0
# Outer loop to iterate over starting indices of substrings
for i in range(n):
# Initialize the vowel count for the current substring
vowels = 0
# Initialize the consonant count for the current substring
consonants = 0
# Inner loop to iterate over ending indices of substrings
for j in range(i, n):
# Check if the current character is a vowel
if self.isVowel(s[j]):
# Increment vowel count
vowels += 1
else:
# Increment consonant count
consonants += 1
# Check if the substring satisfies the conditions for being beautiful
if vowels == consonants and (vowels * consonants) % k == 0:
ans += 1 # Increment the answer counter if conditions are met
# Return the total count of beautiful substrings
return ans
4. Javascript Try on Compiler
/**
* @param {string} s
* @param {number} k
* @return {number}
*/
// Helper function to check if a character is a vowel
var isVowel = function(ch) {
return ch === 'a' || ch === 'e' || ch === 'i' || ch === 'o' || ch === 'u';
};
var beautifulSubstrings = function (s, k) {
// Get the length of the string
let n = s.length;
// Initialize the answer counter
let ans = 0;
// Outer loop to iterate over starting indices of substrings
for (let i = 0; i < n; i++) {
// Initialize the vowel count for the current substring
let vowels = 0;
// Initialize the consonant count for the current substring
let consonants = 0;
// Inner loop to iterate over ending indices of substrings
for (let j = i; j < n; j++) {
// Check if the current character is a vowel
if (isVowel(s[j])) {
// Increment vowel count
vowels++;
} else {
// Increment consonant count
consonants++;
}
// Check if the substring satisfies the conditions for being beautiful
if (vowels === consonants && (vowels * consonants) % k === 0) {
ans++; // Increment the answer counter if conditions are met
}
}
}
// Return the total count of beautiful substrings
return ans;
};
Time Complexity: O(n²)
This approach runs two nested loops to find all substrings, one inside another, where the outer loop runs n times
(i.e. i ranges from 0 to n), and for each iteration of the outer loop, the inner loop(i.e. j ranges from i to n) also runs n-i times.
Analyzing the Loops:
Outer Loop (indexed by i):
It runs from 0 to n-1. So, it iterates n times.
Inner Loop (indexed by j):
For each fixed i, j runs from i to n-1.
When i = 0, j runs n times.
When i = 1, j runs n-1 times.
When i = 2, j runs n-2 times.
…
When i = n-1, j runs 1 time.
Total Iterations:
To find the total number of iterations of the inner loop across all iterations of the outer loop,
we sum up the iterations for each value of i: ∑(i=0 to n−1) (n−i)
This is the sum of an arithmetic series: n+(n−1)+(n−2)+…+1.
If we closely observe and reverse the series
we get 1 + 2 + 3 + … + (n-2) + (n-1) + n.
That is nothing but the sum of n terms.
So the sum of n numbers from 1 to n is (n*(n+1))/2.
Thus, the total number of operations is (n*(n+1))/2.
Simplifying to Big-O Notation:
In Big-O notation, we focus on the term that grows the fastest as n increases, and we ignore constant factors and lower-order terms.
Therefore: O((n*(n+1))/2) ≈ O(n²)
Conclusion: The time complexity of the given code is O(n²).
This is because the nested loops result in a quadratic number of total operations, which dominate the runtime as the input size n becomes large.
Space Complexity: O(n)
Auxiliary Space Complexity: O(1)
The solution uses only a few variables (ans, vowels, consonants) are used, which require O(1) space.
Total Space Complexity: O(n)
The input string s is given, which requires O(n) space.
Adding this to the auxiliary space gives: Total Space Complexity = O(n)
Will Brute Force Work Against the Given Constraints?
For the current solution, the time complexity is O(n²), which is not suitable for n ≤ 10⁴. This means that for each test case where the length of string s (n) is at most 10⁴, the solution should not execute within the given time limits.
Since O(n²) results in a maximum of 10⁸ operations (for n = 10⁴), the solution is expected to work well for individual test cases under these constraints, typically allowing around 1–2 seconds for execution.
In most competitive programming environments, problems can handle up to 10⁶ operations per test case, meaning for n ≤ 10⁴, the solution is efficient enough. However, when multiple test cases are involved, the total number of operations could easily exceed this limit and approach 10⁸ operations, especially when there are many test cases or the value of n increases.
Thus, while the solution meets the time limits for a single test case, the O(n²) time complexity will give Time Limit Exceeded (TLE) errors when handling larger input sizes or multiple test cases. This can be a challenge for competitive programming problems with larger inputs or numerous test cases.
Can we optimize it?
Yes, of course!
We can definitely optimize it—let's do it!
In the previous approach, we iterate through each and every substring, count the number of vowels and consonants in each substring, and check the conditions vowels == consonants and (vowels * consonants) % k == 0, but this takes O(n²) time, which is not efficient enough.
Ok, let's look into an observation.
We need to check if vowels = consonants.
Rearranging, this becomes: vowels - consonants = 0.
Now, suppose there’s an index j for which vowels[j] - consonants[j] = p, and we previously encountered an index i in the string where vowels[i] - consonants[i] = p.
Taking both equations:
- vowels[j] - consonants[j] = p
- vowels[i] - consonants[i] = p
Subtracting the second equation from the first:
vowels[j] - consonants[j] = vowels[i] - consonants[i]
Rearranging:
vowels[j] - vowels[i] = consonants[j] - consonants[i]
What does this equation signify?
- vowels[j] - vowels[i] represents the number of vowels in the substring s[i+1:j] (as we subtract the number of vowels from 0 to i from the number of vowels from 0 to j).
- consonants[j] - consonants[i] represents the number of consonants in the substring s[i+1:j] (as we subtract the number of consonants from 0 to i from the number of consonants from 0 to j).
This equation means, the number of vowels in the substring s[i+1:j] is equal to the number of consonants in the substring s[i+1:j].
With this observation, we can conclude that if we have a substring s[i+1:j], and for this substring, vowels[j] - consonants[j] = vowels[i] - consonants[i], then the number of vowels in the substring is equal to the number of consonants in the substring.
To find this efficiently within a string, we can iterate over the string using an index j and calculate vowels[j] - consonants[j] for each index. If this value matches a value previously encountered at index i, we can determine that there exists a substring s[i+1:j] where the number of vowels equals the number of consonants.
Ok, that was one part of the observation. Now, let’s handle the second condition:
We need to prove that (vowels * consonants) % k == 0 for the substring.
Taking the condition:
(vowels * consonants) % k == 0
But in the previous step, we proved that vowels == consonants.
Substituting this:
(vowels * vowels) % k == 0
Hence, for every index, we also need to store the count of vowels to check if this condition is satisfied.
But wait—our string can range from 0 to 5 × 10⁴, so in the worst case, the count of vowels can also go up to this range. Can we optimize this part?
Yes, we can!
Using the equation:
(vowels * vowels) % k == 0
Apply the distributive property of modulo:
((vowels % k) * (vowels % k)) % k == 0
Now, to address the second part of the problem, we need to check if ((vowels % k) * (vowels % k)) % k == 0. This means we only need the vowels % k values to verify the condition.
As we traverse the string, we will keep a running count of vowels from the start. For each index j, we compute and store vowels[j] % k. This represents the remainder when the total number of vowels from the beginning of the string to index j is divided by k.
To determine the number of vowels in the substring s[i+1:j], we simply calculate vowels[j] % k - vowels[i] % k. Here:
- vowels[j] represents the total number of vowels from index 0 to j.
- vowels[i] represents the total number of vowels from index 0 to i.
Subtracting these gives the number of vowels in the substring s[i+1:j].
Combining both observations, for each index j, we need to track two key values: vowels[j] - consonants[j] and vowels[j] % k.
Here’s the logic:
- As we iterate over the string, if the value vowels[j] - consonants[j] has been encountered before, it indicates the existence of a substring s[i+1:j] where the number of vowels equals the number of consonants.
- Once such a substring is found, we verify if the number of vowels in the substring (i.e., vowels[j] % k - vowels[i] % k) satisfies the condition ((vowels % k) * (vowels % k)) % k == 0. This ensures that the square of the number of vowels in the substring is divisible by k.
If both conditions are satisfied, we have identified a beautiful substring.
To store both vowels[j] - consonants[j] and vowels[j] % k efficiently for faster lookup, we use a 2D hashmap. Here's how it works:
- The outer hashmap tracks vowels[j] - consonants[j] as the key.
- The inner hashmap stores vowels[j] % k as the key and its frequency as the value.
This structure allows us to efficiently:
- Check if vowels[j] - consonants[j] has been encountered before.
- For a matching key, check if vowels[j] % k satisfies the condition for a beautiful substring.
Example:
- Outer map: Tracks the balance between vowels and consonants, e.g., mp[vowels[j] - consonants[j]].
- Inner map: Tracks the frequency of different vowels[j] % k values for a given balance, e.g., mp[balance][vowels[j] % k].
This structure ensures that for every index j, we can quickly find:
- Matching substrings where vowels[j] - consonants[j] is the same as a previously encountered balance.
- The frequency of vowels[j] % k to validate the condition.
By maintaining this 2D hashmap, lookups and updates remain efficient, enabling us to process the string optimally.
Let us understand this with a video,
Let's understand with an example:
Dry Run for s = "baeyh", k = 2:
Initial Setup:
- map = {0: {0: 1}} (Start with (vowels - consonants = 0) and (vowels % k = 0) for the empty prefix, as both vowels and consonants are initialized to 0 at the beginning.).
- vowels = 0, consonants = 0, ans = 0.
Iteration:
- j = 0, char = 'b':
- Consonant: consonants = 1.
- balance = vowels - consonants = -1.
- vowels % k = 0.
- No match for balance in map, add {-1: {0: 1}}.
- ans = 0.
- j = 1, char = 'a':
- Vowel: vowels = 1.
- balance = vowels - consonants = 0.
- vowels % k = 1.
- Found balance = 0 in map, but vowels % k = 1 doesn’t satisfy the condition. ((vowels % k- pastVowel) * (vowels % k- pastVowel))%k == 0
- Update map = {0: {0: 1, 1: 1}}.
- ans = 0.
- j = 2, char = 'e':
- Vowel: vowels = 2.
- balance = vowels - consonants = 1.
- vowels % k = 0.
- No match for balance in map, add {1: {0: 1}}.
- ans = 0.
- j = 3, char = 'y':
- Consonant: consonants = 2.
- balance = vowels - consonants = 0.
- vowels % k = 0.
- Found balance = 0 with vowels % k = 0 in map.
- Satisfies ((vowels % k - pastVowel) * (vowels % k - pastVowel)) % k == 0.
- Increment ans += 1.
- Update map = {0: {0: 2, 1: 1}}.
- ans = 1.
- j = 4, char = 'h':
- Consonant: consonants = 3.
- balance = vowels - consonants = -1.
- vowels % k = 0.
- Found balance = -1 with vowels % k = 0 in map.
- Satisfies ((vowels % k - pastVowel) * (vowels % k - pastVowel)) % k == 0.
- Increment ans += 1.
- Update map = {-1: {0: 2}}.
- ans = 2.
Final Answer:
- ans = 2.
- Beautiful substrings: "baey" and "aeyh".
Final Map State:
- map = {0: {0: 2, 1: 1}, -1: {0: 2}, 1: {0: 1}}.
How to code it up:
- Define the helper function:
- Create a function isVowel to check if a character is a vowel.
- Initialize variables:
- Set ans = 0 (stores the count of beautiful substrings).
- Set vowels = 0 and consonants = 0 (track cumulative counts).
- Create the map:
- Initialize mp as unordered_map<int, unordered_map<int, int>>.
- Set mp[0][0] = 1 (base case to handle empty prefix).
- Iterate through the string:
- For each character ch:
- If it's a vowel, increment vowels; otherwise, increment consonants.
- Compute pSum = vowels - consonants.
- Check for beautiful substrings:
- For each entry in mp[pSum], check if ((vowels % k - pastVowel) * (vowels % k - pastVowel)) % k == 0.
- If true, increment ans by the count stored in mp[pSum].
- Update the map:
- Increment mp[pSum][vowels % k] to track the occurrence of the current combination.
- Return the result:
- After the loop ends, return ans, the count of beautiful substrings.
Code Implementation
1. C++ Try on Compiler
class Solution {
// Helper function to check if a character is a vowel
bool isVowel(char ch) {
return ch == 'a' || ch == 'e' || ch == 'i' || ch == 'o' || ch == 'u';
}
public:
// Function to count the number of beautiful substrings
long long beautifulSubstrings(string s, int k) {
// Initialize the answer counter to 0
long long ans = 0;
// Initialize counters for vowels and consonants
long long vowels = 0;
long long consonants = 0;
// Create a map to store the balance (vowels - consonants) and their counts based on mod values
unordered_map<int, unordered_map<int, int>> mp;
// Base case: The empty prefix balance of 0 with mod 0 occurs once
mp[0][0] = 1;
// Iterate through the string to process each character
for(auto &ch: s) {
// If the character is a vowel, increment the vowels count
if(isVowel(ch))
vowels++;
else
// Otherwise, increment the consonants count
consonants++;
// Calculate the balance between vowels and consonants at the current index
long long pSum = (vowels - consonants);
// Iterate through previous occurrences of the same balance (vowels - consonants)
for(auto &[pastVowel, count] : mp[pSum]) {
// Check if the current substring satisfies the condition for being beautiful
if(((vowels % k - pastVowel) * (vowels % k - pastVowel)) % k == 0)
// Increment the answer by the count of previous occurrences
ans += count;
}
// Update the map with the current balance and mod value
mp[pSum][vowels % k]++;
}
// Return the final count of beautiful substrings
return ans;
}
};
2. Java Try on Compiler
import java.util.HashMap;
import java.util.Map;
class Solution {
// Helper function to check if a character is a vowel
private boolean isVowel(char ch) {
return ch == 'a' || ch == 'e' || ch == 'i' || ch == 'o' || ch == 'u';
}
public long beautifulSubstrings(String s, int k) {
// Initialize the answer counter to 0
long ans = 0;
// Initialize counters for vowels and consonants
long vowels = 0;
long consonants = 0;
// Create a map to store the balance (vowels - consonants) and their counts based on mod values
Map<Long, Map<Long, Long>> mp = new HashMap<>();
// Base case: The empty prefix balance of 0 with mod 0 occurs once
mp.put(0L, new HashMap<>());
mp.get(0L).put(0L, 1L);
// Iterate through the string to process each character
for (char ch : s.toCharArray()) {
// If the character is a vowel, increment the vowels count
if (isVowel(ch)) {
vowels++;
} else {
// Otherwise, increment the consonants count
consonants++;
}
// Calculate the balance between vowels and consonants at the current index
long pSum = vowels - consonants;
// Iterate through previous occurrences of the same balance (vowels - consonants)
for (Map.Entry<Long, Long> entry : mp.getOrDefault(pSum, new HashMap<>()).entrySet()) {
// Check if the current substring satisfies the condition for being beautiful
if (((vowels % k - entry.getKey()) * (vowels % k - entry.getKey())) % k == 0) {
// Increment the answer by the count of previous occurrences
ans += entry.getValue();
}
}
// Update the map with the current balance and mod value
mp.putIfAbsent(pSum, new HashMap<>());
mp.get(pSum).put(vowels % k, mp.get(pSum).getOrDefault(vowels % k, 0L) + 1L);
}
// Return the final count of beautiful substrings
return ans;
}
}
3. Python Try on Compiler
from collections import defaultdict
class Solution:
# Helper function to check if a character is a vowel
def isVowel(self, ch):
return ch in 'aeiou'
def beautifulSubstrings(self, s, k):
# Initialize the answer counter to 0
ans = 0
# Initialize counters for vowels and consonants
vowels = 0
consonants = 0
# Create a map to store the balance (vowels - consonants) and their counts based on mod values
mp = defaultdict(lambda: defaultdict(int))
# Base case: The empty prefix balance of 0 with mod 0 occurs once
mp[0][0] = 1
# Iterate through the string to process each character
for ch in s:
# If the character is a vowel, increment the vowels count
if self.isVowel(ch):
vowels += 1
else:
# Otherwise, increment the consonants count
consonants += 1
# Calculate the balance between vowels and consonants at the current index
pSum = vowels - consonants
# Iterate through previous occurrences of the same balance (vowels - consonants)
for pastVowel, count in mp[pSum].items():
# Check if the current substring satisfies the condition for being beautiful
if ((vowels % k - pastVowel) * (vowels % k - pastVowel)) % k == 0:
# Increment the answer by the count of previous occurrences
ans += count
# Update the map with the current balance and mod value
mp[pSum][vowels % k] += 1
# Return the final count of beautiful substrings
return ans
4. Javascript Try on Compiler
/**
* @param {string} s
* @param {number} k
* @return {number}
*/
// Helper function to check if a character is a vowel
var isVowel = function (ch) {
return 'aeiou'.includes(ch);
}
var beautifulSubstrings = function (s, k) {
// Initialize the answer counter to 0
let ans = 0;
// Initialize counters for vowels and consonants
let vowels = 0;
let consonants = 0;
// Create a map to store the balance (vowels - consonants) and their counts based on mod values
let mp = new Map();
mp.set(0, new Map());
mp.get(0).set(0, 1);
// Iterate through the string to process each character
for (let ch of s) {
// If the character is a vowel, increment the vowels count
if (isVowel(ch)) {
vowels++;
} else {
// Otherwise, increment the consonants count
consonants++;
}
// Calculate the balance between vowels and consonants at the current index
let pSum = vowels - consonants;
// Iterate through previous occurrences of the same balance (vowels - consonants)
if (mp.has(pSum)) {
for (let [pastVowel, count] of mp.get(pSum).entries()) {
// Check if the current substring satisfies the condition for being beautiful
if (((vowels % k - pastVowel) * (vowels % k - pastVowel)) % k == 0) {
// Increment the answer by the count of previous occurrences
ans += count;
}
}
}
// Update the map with the current balance and mod value
if (!mp.has(pSum)) {
mp.set(pSum, new Map());
}
mp.get(pSum).set(vowels % k, (mp.get(pSum).get(vowels % k) || 0) + 1);
}
// Return the final count of beautiful substrings
return ans;
};
Time Complexity: O(n * k)
The outer loop runs once for each character in the string, so it will iterate n times, where n is the length of the string.
For each character, the inner loop iterates over the Map of previous balances (mp[pSum]). For each balance (pSum), we perform a lookup in mp[pSum], which takes O(1) time on average for a map access. Then, the code iterates through the map associated with that balance (mp[pSum]), which contains the mod values (vowels % k).
The worst case for each balance can have up to k different mod values (since vowels % k can have at most k different values). So, in the worst case, for each balance, the inner loop can iterate up to k times.
Thus, the total time complexity of the algorithm is O(n * k), where:
- n is the length of the string.
- k is the divisor used for the mod operation.
Space Complexity: O(n * k)
- Auxiliary Space Complexity: O(n*k)
The main auxiliary space usage is from the unordered_map mp.
mp stores balances (vowels - consonants) as keys and the counts of mod values (vowels % k) for each balance as values. - For each unique balance (vowels - consonants), we store up to k possible mod values (because vowels % k can have up to k different values).
- In the worst case, there can be O(n) distinct balances (since vowels - consonants can range from -n to +n). For each balance, there can be up to k different mod values.
So, the auxiliary space for the map mp is O(n * k).
- Total Space Complexity: O(n)
The input string s itself takes O(n) space.
Thus, the total space complexity is O(n) (for the input string s) + O(n * k) (for the unordered_map mp) = O(n * k).
Learning Tip
Now we have successfully tackled this problem, let's try these similar problems.
Given an array of integer nums and an integer k, return the total number of continuous subarrays whose sum equals k.
Given an integer array nums and an integer k, return the number of non-empty subarrays that have a sum divisible by k.
A subarray is a contiguous part of an array.