Word Subsets Solution In C++/Python/Java/Javascript
Problem Description:
You are given two lists of words: words1 and words2.
A word from words2 is called a subset of a word in words1 if:
All the letters in the word from words2 are present in the word from words1.
And each letter appears at least as many times in the word from words1 as it does in the word from words2.
For example:
"wrr" is a subset of "warrior" (because "warrior" has at least 2 'r's and one 'w').
But "wrr" is not a subset of "world" (because "world" doesn’t have 2 'r's).
A word from words1 is called universal if:
Every word in words2 is a subset of it.
The goal is to return all the universal words from words1.
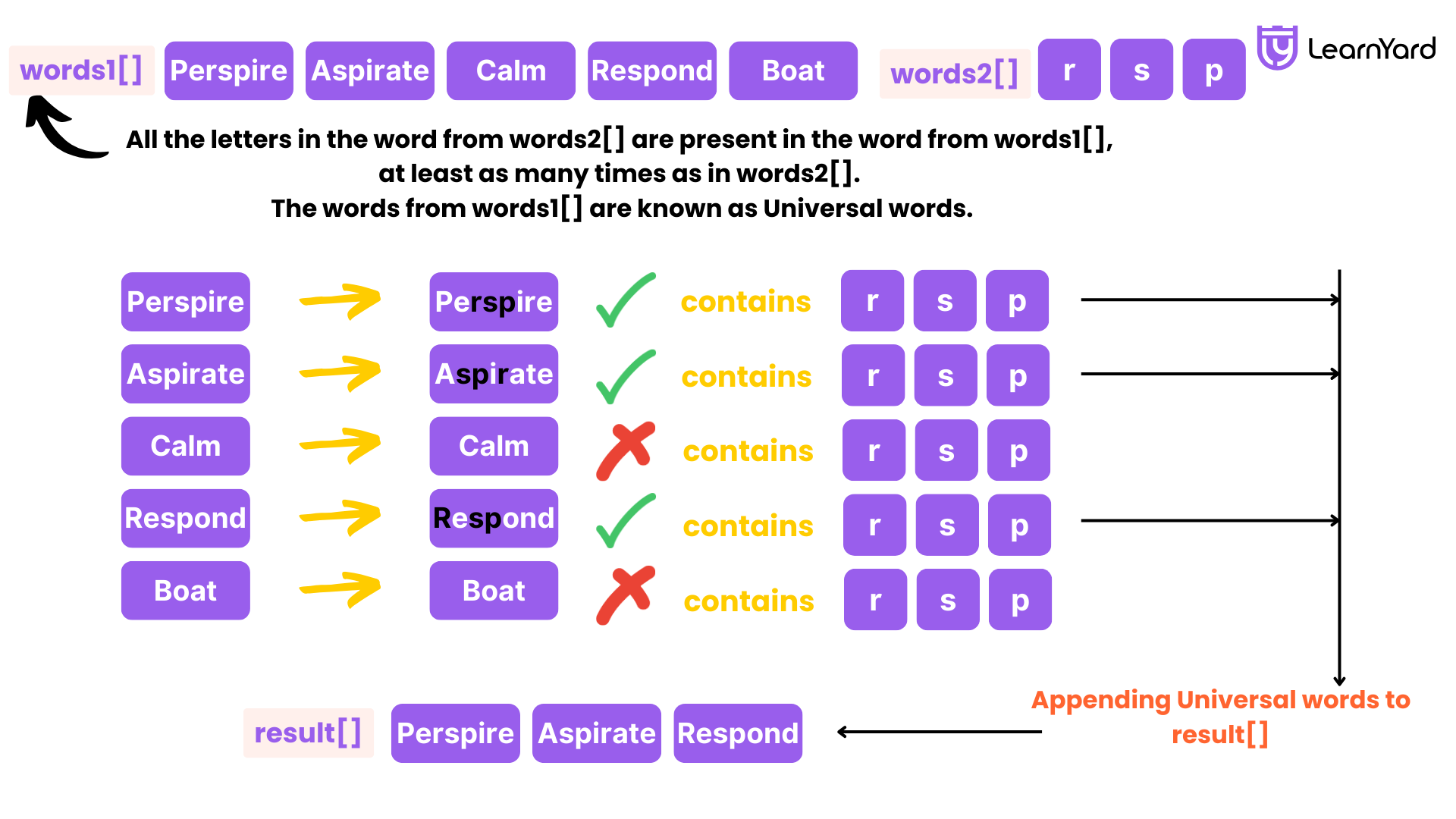
Examples:
Input: words1 = ["amazon","apple","facebook","google","leetcode"], words2 = ["e","o"]
Output: ["facebook","google","leetcode"]
Explanation: "e" and "o" exits on only three strings of words1 i.e. "facebook", "google" and "leetcode"
Input: words1 = ["amazon","apple","facebook","google","leetcode"], words2 = ["l","e"]
Output: ["apple","google","leetcode"]
Explanation: "l" and "e" exits on only three strings of words1 i.e. "apple", "google" and "leetcode"
Constraints:
1 <= words1.length, words2.length <= 10⁴
1 <= words1[i].length, words2[i].length <= 10
words1[i] and words2[i] consist only of lowercase English letters.
All the strings of words1 are unique.
Brute Force Approach
Okay, so here's the thought process:
What comes to mind after reading the problem statement?
We need to find strings from words1 such that every string in words2 is a subset of that string in words1.
If a string from words1 satisfies this condition, we add it to the answer. After processing all strings in words1, we return the answer.
To check if a string from words2 is a subset of a string from words1, we ensure that:
- Every character in the string from words2 is present in the string from words1.
- The character appears at least as many times in the string from words1 as it does in the string from words2.
This process is repeated for all strings in words2 and all strings in words1 to find the valid strings in words1 that meet the condition. Finally, we return the list of such valid strings.
How can we do it?
Now we understand what we need to do, so let's focus on how to do it.
We will traverse through all the strings in words1, and for every string, we will traverse through all the strings in words2. If the string from words2 is a subset of the string from words1, we will continue to check for all the strings in words2. If all strings in words2 satisfy the condition, we will simply add the string from words1 to the answer.
But how do we check if a string b (from words2) is a subset of a string a (from words1) or not?
For this, we will simply check how many times each character occurs in string b. If it occurs at least that many times in string a, then b is a subset of a.
Ok, now we got it! So we will keep track of the frequencies of both string a and string b. The frequency of every character in string b should be less than or equal to the frequency of every character in string a.
But how do we keep track of the frequencies of characters in an effective way?
Which data structure is useful here?
Yes, it's a hashtable!
What is a hash table?
A hashtable is a data structure that stores key-value pairs, using a hash function to compute an index for quick access. It offers average O(1) time complexity for operations like insertion, deletion, and lookup.
Got it! To sum up:
We will iterate through all the strings in words1. For every string in words1, we will maintain a frequency table of all its characters. Then, we will go through all the strings in words2 and check if each string is a subset of the current string from words1 by comparing the frequencies of characters.
If all strings in words2 are subsets of the current string from words1, we will add that string from words1 to our answer. Finally, at the end of the process, we will return all such strings as our result.
Let's understand with an example:
Dry Run of Brute Force for :
words1 = ["amazon", "apple", "facebook", "google", "leetcode"]
words2 = ["e", "o"]
Steps:
- words2 frequency requirement:
For "e" → {'e': 1}
For "o" → {'o': 1}
Combined requirement: {'e': 1, 'o': 1} (take the maximum frequency for each character across words2). - Check each string in words1 against the combined requirement:
- "amazon":
- Frequency: {'a': 2, 'm': 1, 'z': 1, 'o': 1, 'n': 1}
- Satisfies "e"? No (no 'e') → Not universal.
- "apple":
- Frequency: {'a': 1, 'p': 2, 'l': 1, 'e': 1}
- Satisfies "e"? Yes.
- Satisfies "o"? No (no 'o') → Not universal.
- "facebook":
- Frequency: {'f': 1, 'a': 1, 'c': 1, 'e': 2, 'b': 1, 'o': 2, 'k': 1}
- Satisfies "e"? Yes.
- Satisfies "o"? Yes → Universal.
- "google":
- Frequency: {'g': 2, 'o': 2, 'l': 1, 'e': 1}
- Satisfies "e"? Yes.
- Satisfies "o"? Yes → Universal.
- "leetcode":
- Frequency: {'l': 1, 'e': 3, 't': 1, 'c': 1, 'o': 1, 'd': 1}
- Satisfies "e"? Yes.
- Satisfies "o"? Yes → Universal.
Output: ["facebook", "google", "leetcode"]
How to code it up:
Here are the concise steps to code the solution:
- Define a helper function getFrequency:
Create a frequency array of size 26 (for each letter 'a' to 'z').
Iterate over the characters of the input string and count the frequency of each character.
Return the frequency array. - Define a helper function isSubset:
Take two frequency arrays as input.
Compare the frequencies at each index.
If any character in the second frequency array has a count greater than in the first array, return false. Otherwise, return true. - Implement the main function wordSubsets:
Initialize an empty vector result to store the universal words.
Iterate over each word in words1:
Get its frequency array using getFrequency.
Initialize a flag isUniversal as true.
For each word in words2:
Get its frequency array using getFrequency.
Check if the current word from words1 satisfies the subset condition using isSubset.
If it doesn't, set isUniversal to false and break out of the loop.
If the word satisfies all conditions, add it to result.
Return result.
By following these steps, you'll implement a solution that checks for universal words efficiently.
Code Implementation
1. C++ Try on Compiler
class Solution {
public:
// Function to calculate the frequency of each character in a word
vector<int> getFrequency(const string& word) {
// Initialize a frequency array of size 26 for each letter 'a' to 'z'
vector<int> freq(26, 0);
// Count the frequency of each character in the word
for (char c : word) {
freq[c - 'a']++;
}
// Return the frequency array
return freq;
}
// Function to check if freq2 is a subset of freq1
bool isSubset(const vector<int>& freq1, const vector<int>& freq2) {
// Iterate through all 26 characters
for (int i = 0; i < 26; i++) {
// If any character in freq2 has a count greater than in freq1, return false
if (freq2[i] > freq1[i]) {
return false;
}
}
// If all characters satisfy the condition, return true
return true;
}
// Function to find all universal strings in words1
vector<string> wordSubsets(vector<string>& words1, vector<string>& words2) {
// Initialize the result vector to store universal strings
vector<string> result;
// Iterate through all strings in words1
for (const string& word1 : words1) {
// Get the frequency array of the current string in words1
vector<int> freq1 = getFrequency(word1);
// Initialize a flag to check if the current word1 is universal
bool isUniversal = true;
// Iterate through all strings in words2
for (const string& word2 : words2) {
// Get the frequency array of the current string in words2
vector<int> freq2 = getFrequency(word2);
// Check if the current word2 is a subset of word1
if (!isSubset(freq1, freq2)) {
// If not, mark as not universal and break the loop
isUniversal = false;
break;
}
}
// If the word1 satisfies the condition for all words2, add it to the result
if (isUniversal) {
result.push_back(word1);
}
}
// Return the result containing all universal strings
return result;
}
};
2. Java Try on Compiler
import java.util.*;
public class Solution {
// Function to calculate the frequency of each character in a word
private int[] getFrequency(String word) {
// Array of size 26 for letters 'a' to 'z'
int[] freq = new int[26];
// Count the frequency of each character in the word
for (char c : word.toCharArray()) {
freq[c - 'a']++;
}
// Return the frequency array
return freq;
}
// Function to check if freq2 is a subset of freq1
private boolean isSubset(int[] freq1, int[] freq2) {
// Check if all frequencies in freq2 are less than or equal to those in freq1
for (int i = 0; i < 26; i++) {
if (freq2[i] > freq1[i]) {
// If any character in freq2 exceeds freq1, it's not a subset
return false;
}
}
// If all characters satisfy the condition, return true
return true;
}
// Function to find all universal strings in words1
public List<String> wordSubsets(String[] words1, String[] words2) {
// Initialize the result list to store universal strings
List<String> result = new ArrayList<>();
// Convert words2 into frequency arrays to avoid repeated calculations
List<int[]> freqWords2 = new ArrayList<>();
for (String word2 : words2) {
freqWords2.add(getFrequency(word2));
}
// Iterate through all strings in words1
for (String word1 : words1) {
// Get the frequency array of the current word in words1
int[] freq1 = getFrequency(word1);
// Flag to track if word1 is universal
boolean isUniversal = true;
// Iterate through all frequency arrays of words2
for (int[] freq2 : freqWords2) {
// Check if the current word2 is a subset of word1
if (!isSubset(freq1, freq2)) {
// If not, mark as not universal
isUniversal = false;
break;
}
}
// If word1 satisfies the condition for all words2, add it to the result
if (isUniversal) {
result.add(word1);
}
}
// Return the list of universal strings
return result;
}
}3. Python Try on Compiler
class Solution:
# Function to calculate the frequency of each character in a word
def getFrequency(self, word):
freq = [0] * 26
for c in word:
freq[ord(c) - ord('a')] += 1
return freq
# Function to check if freq2 is a subset of freq1
def isSubset(self, freq1, freq2):
for i in range(26):
if freq2[i] > freq1[i]:
return False
return True
# Function to find all universal strings in words1
def wordSubsets(self, words1, words2):
result = []
# Iterate through all strings in words1
for word1 in words1:
freq1 = self.getFrequency(word1)
isUniversal = True
# Iterate through all strings in words2
for word2 in words2:
freq2 = self.getFrequency(word2)
if not self.isSubset(freq1, freq2):
isUniversal = False
break
# If word1 satisfies the condition for all words2, add it to the result
if isUniversal:
result.append(word1)
return result4. Javascript Try on Compiler
/**
* @param {string[]} words1
* @param {string[]} words2
* @return {string[]}
*/
// Function to calculate the frequency of each character in a word
var getFrequency = function(word) {
const freq = new Array(26).fill(0);
for (const c of word) {
freq[c.charCodeAt(0) - 'a'.charCodeAt(0)]++;
}
return freq;
}
// Function to check if freq2 is a subset of freq1
isSubset = function(freq1, freq2) {
for (let i = 0; i < 26; i++) {
if (freq2[i] > freq1[i]) {
return false;
}
}
return true;
}
var wordSubsets = function (words1, words2) {
const result = [];
// Iterate through all strings in words1
for (const word1 of words1) {
const freq1 = getFrequency(word1);
let isUniversal = true;
// Iterate through all strings in words2
for (const word2 of words2) {
const freq2 = getFrequency(word2);
if (!isSubset(freq1, freq2)) {
isUniversal = false;
break;
}
}
// If word1 satisfies the condition for all words2, add it to the result
if (isUniversal) {
result.push(word1);
}
}
return result;
}Time Complexity: O(n1 * n2 * (m1 + m2))
Let's walk through the time complexity:
Step 1: getFrequency(String word) function
- For each word, we go through all its characters once, so the complexity depends on the length of the word. The time complexity of this function is O(m), where m is the length of the word.
Step 2: isSubset(int[] freq1, int[] freq2) function
- Since there are only 26 lowercase English letters, this function always iterates over a fixed number of 26 characters. Therefore, its time complexity is O(26), which simplifies to O(1) because 26 is a constant.
Step 3: wordSubsets(String[] words1, String[] words2) function
- Here, for each word in words1, we call getFrequency to get the frequency array. This takes O(m1) time, where m1 is the length of the current word.
- For each word in words2, we check if it is a subset of the current word from words1 by calling isSubset. Each comparison takes O(m2), where m2 is the length of the current word from words2.
- The function loops over all words in words1 and words2, so the overall time complexity for this part is O(n1 * n2 * (m1 + m2)),
where n1 is the number of words in words1,
n2 is the number of words in words2,
m1 is the average length of words in words1, and m2 is the average length of words in words2.
Final Time Complexity: Overall, the time complexity of the wordSubsets function is O(n1 * n2 * (m1 + m2)).
Space Complexity: O(n1 * m1 + n2 * m2)
Auxiliary Space: O(1)
Explanation: The only significant additional space used is for storing the frequency arrays and intermediate variables (such as the boolean flag and result list). Therefore, the auxiliary space complexity is O(1), as the frequency array has a fixed size of 26 (one entry for each letter of the alphabet). The auxiliary space taken by a single frequency array is O(1), since 26 is a constant.
Total Space Complexity: O(n)
Explanation: We are given two input arrays, words1 and words2. The total space taken by these arrays is proportional to the number of words and the length of each word. Hence, the space complexity for the input is O(n1 * m1 + n2 * m2), where n1 and n2 are the number of words in words1 and words2, respectively, and m1 and m2 are the average lengths of the words in words1 and words2, respectively.
Therefore, the total space used by the algorithm is O(n1 * m1 + n2 * m2).
Will Brute Force Work Against the Given Constraints?
For the current solution, the time complexity is O(n1 * n2 * (m1 + m2)), where n1 and n2 represent the number of strings in words1 and words2, respectively, and m1 and m2 represent the average lengths of the strings in words1 and words2. Given the constraints:
- 1 ≤ words1.length, words2.length ≤ 10⁴
- 1 ≤ words1[i].length, words2[i].length ≤ 10
This time complexity might still be too slow for larger inputs, especially when n1 and n2 are large, or when the lengths of the strings (m1 and m2) are substantial. Although m1 + m2 is small and bounded by O(10), the solution's time complexity is heavily influenced by the sizes of n1 and n2.
For example, with n1 = n2 = 10⁴ and m1 = m2 = 10, the solution might perform up to O(10⁴ * 10⁴ * 10) = O(10⁹) operations, which could be too slow for the largest test cases within typical competitive programming time limits.
In competitive programming environments, problems typically handle up to 10⁶ operations per second, which means that for n1 = n2 = 10⁴, the solution may still perform O(10⁹) operations, which could be inefficient for larger inputs.
Additionally, when multiple test cases are involved, the total number of operations can increase even further, potentially leading to Time Limit Exceeded (TLE) errors. For problems with large inputs or numerous test cases, this time complexity could be a major bottleneck.
Thus, while this solution might work for small inputs, it is not efficient enough to handle larger inputs or numerous test cases, especially when n1, n2, m1, and m2 are close to their upper limits.
Can we optimize it?
In the previous approach, we traversed through all the strings in words1, and for every string, we traversed through all the strings in words2. If a string from words2 was a subset of a string from words1, we continued to check for the remaining strings in words2. If all strings in words2 satisfied the condition, we added the string from words1 to the answer. While this approach was correct, it took O(n1 * n2 * (m1 + m2)) time.
Can we optimize this?
The answer is yes!
Let’s understand where the optimization is needed. If you observe, for each string a in words1, we are checking the entire list of strings in words2. This double iteration is taking a significant amount of time, especially since both n1 and n2 can go up to 10⁴.
How can we optimize this?
Think about why we need the second loop. The second loop is there to traverse the entire words2 array and check if each string in words2 is a subset of the current string from words1. Essentially, we are comparing the frequency of characters in a string a from words1 with all the strings in words2.
So, here’s the key insight: Can’t we preprocess the frequency of characters in all the strings of words2 at once and then compare it with each string from words1?
For example, consider words1 = ["abc", "cde"] and words2 = ["a", "c"].
In the previous approach, for each string in words1, we iterated through words2.
- For "abc", we checked if "a" is present. Since it is, we moved on to check if "c" is present. Both conditions are satisfied, so we marked "abc" as valid.
- Then, for "cde", we again checked if "a" is present. Since "a" is not present, we marked "cde" as invalid.
This process repeated for every string in words1 and for every string in words2, making the approach time-consuming for large inputs.
Now, instead of this repetitive checking, we can precompute the frequency of all characters in words2.
- First, calculate the maximum frequency of each character across all strings in words2. In this case, the result would be {a: 1, c: 1}, as "a" appears once in "a", and "c" appears once in "c".
- Then, iterate over each string in words1 and compare its character frequencies with the precomputed frequency of words2.
Let’s apply this logic:
- For "abc", check if it satisfies the precomputed frequency {a: 1, c: 1}. Both "a" and "c" are present at least once, so "abc" is valid.
- For "cde", check if it satisfies {a: 1, c: 1}. "a" is not present, so "cde" is invalid.
Finally, return ["abc"] as the answer.
By preprocessing the frequency of words2, we avoid redundant calculations and speed up the comparison process for words1.
Note that in the frequency table of words2, we store the maximum number of times a character appears across all strings in words2. This ensures that we capture the strictest requirement for each character across all strings in words2.
For example, if words2 = ["a", "aab"],
- In the first string, "a" appears once.
- In the second string, "a" appears twice and "b" appears once.
So, the frequency table for words2 will be {a: 2, b: 1}, as "a" is present a maximum of 2 times, and "b" is present a maximum of 1 time.
Now, if we do this preprocessing, we can store the maximum frequency of each character across all strings in words2. Instead of checking each string of words2 individually, we can compare the frequency of the current string from words1 with this precomputed frequency table.
This eliminates the need for the second loop over words2, reducing the time complexity significantly. This approach leverages preprocessing to make the comparison more efficient.
Let's understand with an example:
Dry Run of the Approach on Input:
words1 = ["amazon", "apple", "facebook", "google", "leetcode"]
words2 = ["lo", "eo"]
Steps:
- Build frequency table for words2:
For "lo": {l: 1, o: 1}
For "eo": {e: 1, o: 1}
Take the max frequency for each character across words2 → {l: 1, o: 1, e: 1}. - Iterate over words1:
"amazon": Frequency → {a: 2, m: 1, z: 1, o: 1, n: 1}.
Does not satisfy {l: 1, o: 1, e: 1} → Skip.
"apple": Frequency → {a: 1, p: 2, l: 1, e: 1}.
Does not satisfy {l: 1, o: 1, e: 1} → Skip.
"facebook": Frequency → {f: 1, a: 1, c: 1, e: 1, b: 1, o: 2, k: 1}.
Does not satisfy {l: 1, o: 1, e: 1} → Skip
"google": Frequency → {g: 2, o: 2, l: 1, e: 1}.
Satisfies {l: 1, o: 1, e: 1} → Add to result.
"leetcode": Frequency → {l: 1, e: 3, t: 1, c: 1, o: 1, d: 1}.
Satisfies {l: 1, o: 1, e: 1} → Add to result.
Result: ["google", "leetcode"]
How to code it up?
Here are concise steps to implement the given solution:
- Initialize maxFreq for words2:
Create a frequency array maxFreq of size 26 initialized to 0.
For each word in words2, calculate the frequency of each character and update maxFreq with the maximum frequency of each character across all words in words2. - Iterate through words1:
For each word in words1, calculate its character frequency using an array freq of size 26.
Compare the frequency of each character in freq against maxFreq.
If any character count in freq is less than the corresponding value in maxFreq, skip the current word.
If all conditions are satisfied, add the word to the result list. - Return the result:
Return the list of universal words from words1.
Code Implementation
1. C++ Try on Compiler
class Solution {
public:
vector<string> wordSubsets(vector<string>& words1, vector<string>& words2) {
// Initialize a frequency array to track the maximum frequency of each character in words2
vector<int> maxFreq(26, 0);
// Iterate through each word in words2 to build the maxFreq array
for (const string& word : words2) {
// Create a frequency array for the current word
vector<int> freq(26, 0);
// Count the frequency of each character in the current word
for (char c : word) {
freq[c - 'a']++;
}
// Update maxFreq to store the maximum frequency of each character across all words in words2
for (int i = 0; i < 26; i++) {
maxFreq[i] = max(maxFreq[i], freq[i]);
}
}
// Initialize the result vector to store universal words
vector<string> ans;
// Iterate through each word in words1
for (const string& word : words1) {
// Create a frequency array for the current word
vector<int> freq(26, 0);
// Count the frequency of each character in the current word
for (char c : word) {
freq[c - 'a']++;
}
// Check if the current word satisfies the universal condition
bool isUniversal = true;
for (int i = 0; i < 26; i++) {
// If any character's frequency in the word is less than the required frequency, it's not universal
if (freq[i] < maxFreq[i]) {
isUniversal = false;
break;
}
}
// If the word is universal, add it to the result vector
if (isUniversal) {
ans.push_back(word);
}
}
// Return the list of universal words
return ans;
}
};
2. Java Try on Compiler
class Solution {
public List<String> wordSubsets(String[] words1, String[] words2) {
// Initialize a frequency array to track the maximum frequency of each character in words2
int[] maxFreq = new int[26];
// Iterate through each word in words2 to build the maxFreq array
for (String word : words2) {
// Create a frequency array for the current word
int[] freq = new int[26];
// Count the frequency of each character in the current word
for (char c : word.toCharArray()) {
freq[c - 'a']++;
}
// Update maxFreq to store the maximum frequency of each character across all words in words2
for (int i = 0; i < 26; i++) {
maxFreq[i] = Math.max(maxFreq[i], freq[i]);
}
}
// Initialize the result list to store universal words
List<String> result = new ArrayList<>();
// Iterate through each word in words1
for (String word : words1) {
// Create a frequency array for the current word
int[] freq = new int[26];
// Count the frequency of each character in the current word
for (char c : word.toCharArray()) {
freq[c - 'a']++;
}
// Check if the current word satisfies the universal condition
boolean isUniversal = true;
for (int i = 0; i < 26; i++) {
// If any character's frequency in the word is less than the required frequency, it's not universal
if (freq[i] < maxFreq[i]) {
isUniversal = false;
break;
}
}
// If the word is universal, add it to the result list
if (isUniversal) {
result.add(word);
}
}
// Return the list of universal words
return result;
}
}
3. Python Try on Compiler
class Solution:
def wordSubsets(self, words1, words2):
# Initialize a frequency array to track the maximum frequency of each character in words2
max_freq = [0] * 26
# Iterate through each word in words2 to build the max_freq array
for word in words2:
# Create a frequency array for the current word
freq = [0] * 26
# Count the frequency of each character in the current word
for c in word:
freq[ord(c) - ord('a')] += 1
# Update max_freq to store the maximum frequency of each character across all words in words2
for i in range(26):
max_freq[i] = max(max_freq[i], freq[i])
# Initialize the result list to store universal words
result = []
# Iterate through each word in words1
for word in words1:
# Create a frequency array for the current word
freq = [0] * 26
# Count the frequency of each character in the current word
for c in word:
freq[ord(c) - ord('a')] += 1
# Check if the current word satisfies the universal condition
is_universal = True
for i in range(26):
# If any character's frequency in the word is less than the required frequency, it's not universal
if freq[i] < max_freq[i]:
is_universal = False
break
# If the word is universal, add it to the result list
if is_universal:
result.append(word)
# Return the list of universal words
return result
4. Javascript Try on Compiler
var wordSubsets = function(words1, words2) {
// Initialize a frequency array to track the maximum frequency of each character in words2
let maxFreq = new Array(26).fill(0);
// Iterate through each word in words2 to build the maxFreq array
for (let word of words2) {
// Create a frequency array for the current word
let freq = new Array(26).fill(0);
// Count the frequency of each character in the current word
for (let c of word) {
freq[c.charCodeAt(0) - 'a'.charCodeAt(0)]++;
}
// Update maxFreq to store the maximum frequency of each character across all words in words2
for (let i = 0; i < 26; i++) {
maxFreq[i] = Math.max(maxFreq[i], freq[i]);
}
}
// Initialize the result array to store universal words
let result = [];
// Iterate through each word in words1
for (let word of words1) {
// Create a frequency array for the current word
let freq = new Array(26).fill(0);
// Count the frequency of each character in the current word
for (let c of word) {
freq[c.charCodeAt(0) - 'a'.charCodeAt(0)]++;
}
// Check if the current word satisfies the universal condition
let isUniversal = true;
for (let i = 0; i < 26; i++) {
// If any character's frequency in the word is less than the required frequency, it's not universal
if (freq[i] < maxFreq[i]) {
isUniversal = false;
break;
}
}
// If the word is universal, add it to the result array
if (isUniversal) {
result.push(word);
}
}
// Return the list of universal words
return result;
};
Time Complexity: O(n2 * m2 + n1 * m1)
First, we handle the maxFreq array:
We go through each word in words2, and for each word, we calculate the frequency of each character. This part involves:
- Iterating over n2 words (the size of words2).
- For each word, we traverse its characters, which takes O(m2) time, where m2 is the average length of the words in words2.
So, the time complexity for this step is O(n2 * m2).
Next, we process words1:
Now, we check each word in words1 against the maxFreq array to see if it meets the universal condition. For each word:
- We calculate its frequency, which takes O(m1) time, where m1 is the average length of the words in words1.
- Then, we compare this frequency with the maxFreq array, which takes constant time O(26) because there are only 26 letters to check.
The time complexity for this step is O(n1 * m1).
Putting it all together:
- For words2, we calculate the frequencies of characters for all words, which takes O(n2 * m2).
- For words1, we compare each word's character frequency with the maxFreq array, which takes O(n1 * m1).
So, the overall time complexity is O(n2 * m2 + n1 * m1).
Space Complexity: O(n1 * m1 + n2 * m2)
Auxiliary Space Complexity: O(n1)
Explanation: The maxFreq and temporary freq arrays are of size 26, which corresponds to the number of lowercase English letters. Since this size is constant and does not depend on the input size, the space required to store these arrays is O(1).
The ans array stores the universal words from words1. In the worst-case scenario, all strings in words1 could be universal, meaning the space required to store the result would be proportional to the number of words in words1. Thus, the space required for ans would be O(n1) in the worst case.
Total Space Complexity: O(n1 * m1 + n2 * m2)
Explanation: We are given two vectors: words1 and words2. The size of words1 is n1, and the size of words2 is n2. Each word in words1 has an average length of m1, and each word in words2 has an average length of m2.
Thus, the space required to store the words in words1 is O(n1 * m1), and the space required to store the words in words2 is O(n2 * m2).
Total space for input storage is the sum of both: O(n1 * m1 + n2 * m2).
So, the total space complexity will be O(n1 * m1 + n2 * m2).
Learning Tip
Now we have successfully tackled this problem, let's try these similar problems.
Given a string s, find the length of the longest substring without repeating characters.
Given a string s and an integer k, return the length of the longest substring of s such that the frequency of each character in this substring is greater than or equal to k.
if no such substring exists, return 0.