Sentence Similarity III
Problem Description
You are given two strings sentence1 and sentence2, each representing a sentence composed of words. A sentence is a list of words that are separated by a single space with no leading or trailing spaces. Each word consists of only uppercase and lowercase English characters.
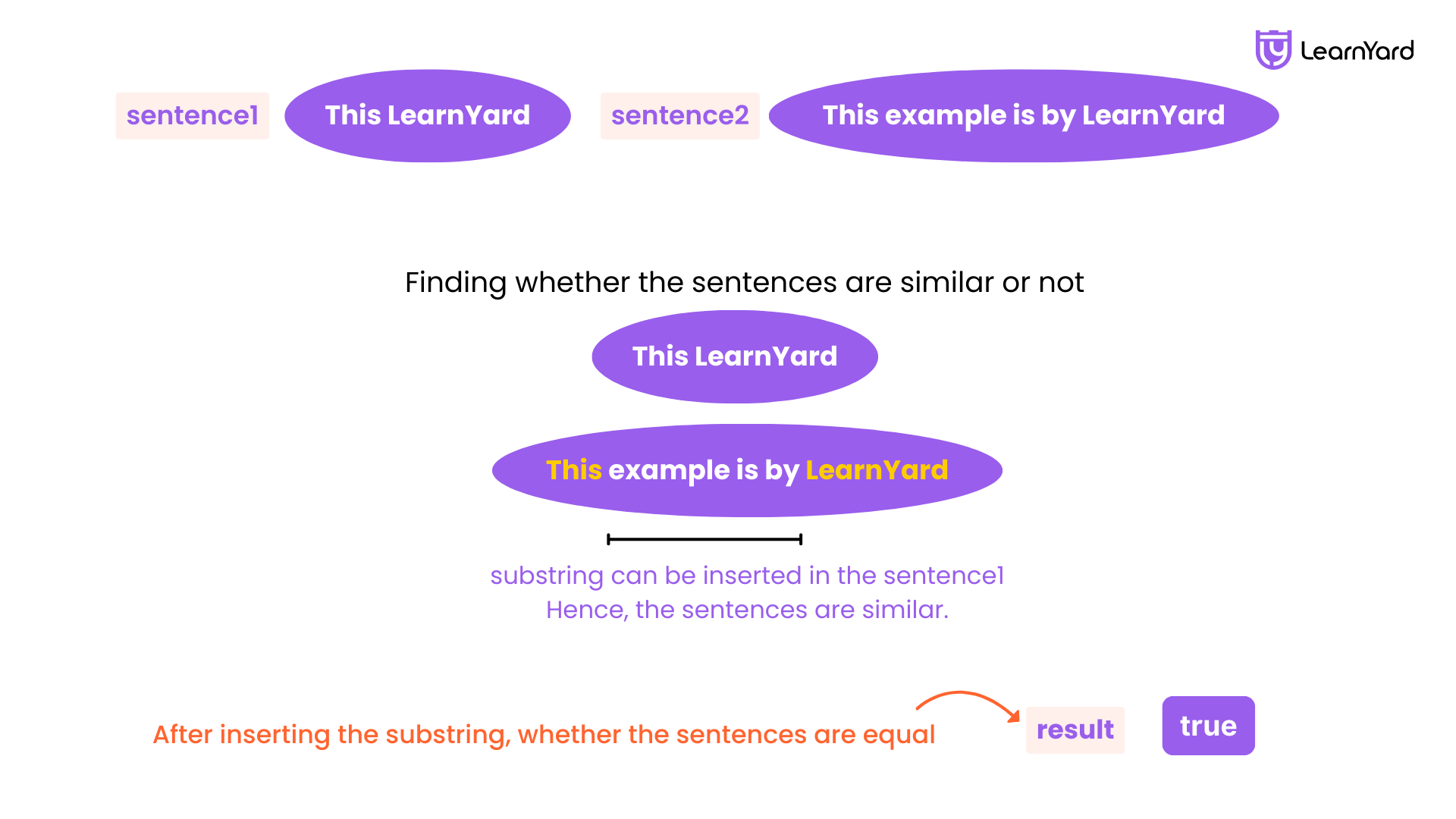
Two sentences s1 and s2 are considered similar if it is possible to insert an arbitrary sentence (possibly empty) inside one of these sentences such that the two sentences become equal. Note that the inserted sentence must be separated from existing words by spaces.
For example,
s1 = "Hello Jane" and s2 = "Hello my name is Jane" can be made equal by inserting "my name is" between "Hello" and "Jane" in s1.
s1 = "Frog cool" and s2 = "Frogs are cool" are not similar, since although there is a sentence "s are" inserted into s1, it is not separated from "Frog" by a space.
Given two sentences sentence1 and sentence2, return true if sentence1 and sentence2 are similar. Otherwise, return false.
Examples
Input: sentence1 = "My name is Haley", sentence2 = "My Haley"
Output: true
Explanation:sentence2 can be turned to sentence1 by inserting "name is" between "My" and "Haley".
Input: sentence1 = "of", sentence2 = "A lot of words"
Output: false
Explanation:No single sentence can be inserted inside one of the sentences to make it equal to the other.
Input: sentence1 = "Eating right now", sentence2 = "Eating"
Output: true
Explanation:sentence2 can be turned to sentence1 by inserting "right now" at the end of the sentence.
Constraints
- 1 <= sentence1.length, sentence2.length <= 100
- sentence1 and sentence2 consist of lowercase and uppercase English letters and spaces.
- The words in sentence1 and sentence2 are separated by a single space.j
Fine, What’s the first thought naturally we get in our mind ? Checking Every possibility right!
Brute Force Approach
Intuition
Okay, Let’s think about one basic thing before going to do the insertions on any particular sentence
To ensure a successful modification when inserting sub-sentences, always modify the sentence with fewer words. Inserting into the longer sentence increases the total word count, making a match impossible, right. By modifying the shorter sentence, it becomes closer in length to the longer one's length, so we can check for the matching.
What is a Sub-Sentence ?
Here, A sub-sentence is a continuous sequence of words taken from the sentence, preserving their order.
Now , how can we check all the possibilities ? Yes, we will take every sub-sentence(words) from one sentence and insert it between every two words in another sentence and we will check after every insertion whether the new sentence and another sentence is equal or not. Remember we are allowed to insert only one single sentence or nothing, not more than one .
Let’s have an Example on how we are going through all possibilities.
sentence1 = "Good morning" sentence2 = "Good things on morning"
Generating Sub-Sentences from sentence2:
From sentence2, sub-sentences start from every word right:
Starting with "Good", what sub-sentences are there?
- "Good", "Good things", "Good things on", "Good things on morning"
Similarly, starting with remaining words in sentence2.
Now, we will insert each sub-sentence into sentence1:
For every sub-sentence from sentence2, insert it into every possible position in sentence1 and check if the result equals sentence2.
Sub-sentence: "Good"
Inserting before "Good":
- "Good Good morning" → Not equal
Inserting between "Good" and "morning":
- "Good Good morning" → Not equal
Inserting after "morning":
- "Good morning Good" → Not equal
Similarly, we insert every sub-sentence of sentence2 between every two words and at the start and at the end also.
After some insertions we will also insert ‘things on’ between ‘Good’ and ‘morning’ then the both sentences become similar !
Approach
Step 1: Break sentence1 and sentence2 into lists of words (words1 and words2) for easier comparison and manipulation.
Step 2: Swap words1 and words2 if necessary so that the shorter sentence is always represented by words1. This simplifies further logic.
Step 3: Using for loops - For every position i in words1, consider all possible segments words2[i:j] of words2 that can be inserted into words1 at index i. This generates a new sentence for comparison.
- After inserting the segment, compare the resulting sentence with words2. If they match, return True.
Step 5: If no combination of insertions makes words1 equal to words2, the function returns False.
Dry Run
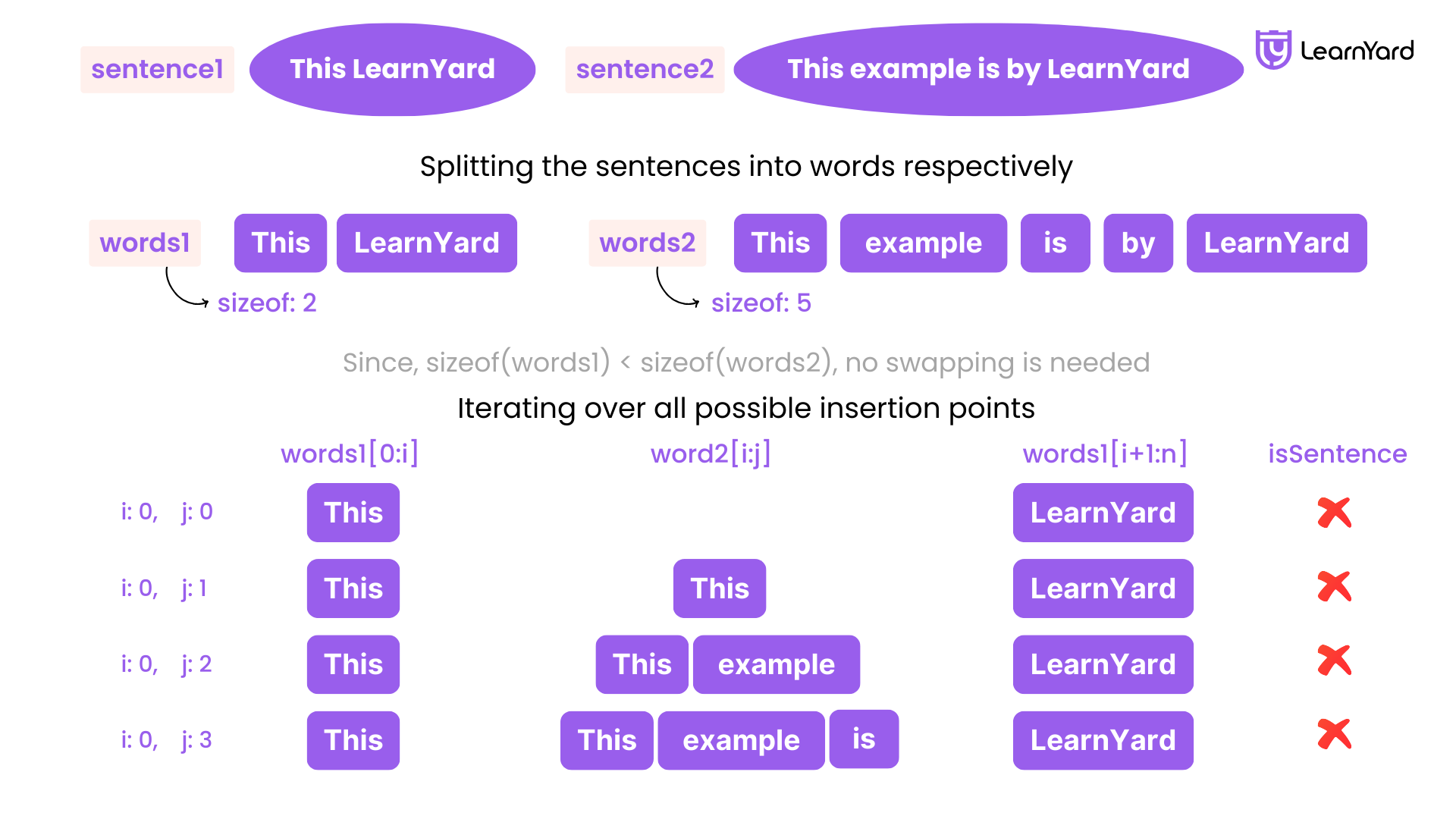
sentence1 = "the sky is blue"
sentence2 = "the beautiful sky is blue"
Output : True
Explanation : beautiful can be inserted between ‘the’ and ‘sky’ . So that both sentences become similar now.
Initialization:
- words1 = sentence1.split() → ['the', 'sky', 'is', 'blue']
- words2 = sentence2.split() → ['the', 'beautiful', 'sky', 'is', 'blue']
- Since len(words1) < len(words2), no swapping is needed.
Outer Loop (Iterate over all possible insertion points in words1):
- len(words1) + 1 = 5, so i will iterate from 0 to 4.
First Outer Loop (i = 0):
Inner Loop (j from i to len(words2)):
- len(words2) + 1 = 6, so j will iterate from 0 to 5.
Sub-iterations:
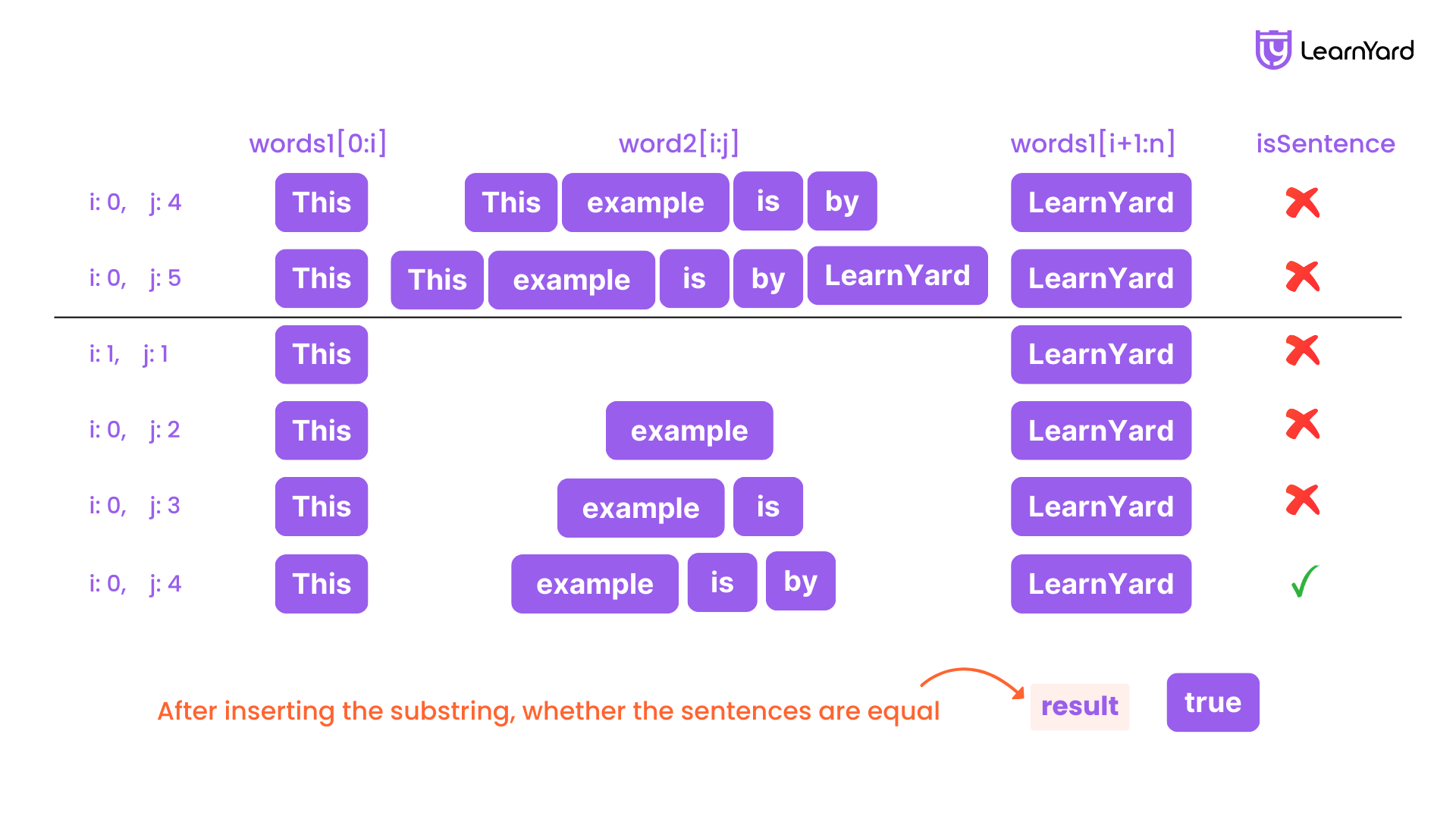
- j = 0: new_sentence = words1[:0] + words2[0:0] + words1[0:] → ['the', 'sky', 'is', 'blue']
→ Doesn't match words2.
- j = 1: new_sentence = words1[:0] + words2[0:1] + words1[0:] → ['the', 'the', 'sky', 'is', 'blue']
→ Doesn't match words2.
- j = 2: new_sentence = words1[:0] + words2[0:2] + words1[0:] → ['the', 'beautiful', 'the', 'sky', 'is', 'blue']
→ Doesn't match words2.
- j = 3: new_sentence = words1[:0] + words2[0:3] + words1[0:] → ['the', 'beautiful', 'sky', 'the', 'sky', 'is', 'blue']
→ Doesn't match words2.
- j = 4: new_sentence = words1[:0] + words2[0:4] + words1[0:] → ['the', 'beautiful', 'sky', 'is', 'the', 'sky', 'is', 'blue']
→ Doesn't match words2.
- j = 5: new_sentence = words1[:0] + words2[0:5] + words1[0:] → ['the', 'beautiful', 'sky', 'is', 'blue']
→ Matches words2.
Match Found: The function returns True.
Brute Force Code in all Languages
1. C++ Try on Compiler
class Solution {
public:
bool areSentencesSimilar(string sentence1, string sentence2) {
vector<string> words1, words2;
stringstream ss1(sentence1), ss2(sentence2);
string word;
// Split sentence1 into words
while (ss1 >> word) {
words1.push_back(word);
}
// Split sentence2 into words
while (ss2 >> word) {
words2.push_back(word);
}
// Ensure words1 is the shorter or equal in length for easier handling
if (words1.size() > words2.size()) {
swap(words1, words2);
}
// Iterate over all possible insertion points in words1
for (int i = 0; i <= words1.size(); i++) {
for (int j = i; j <= words2.size(); j++) {
// Create a new sentence by inserting words2[i:j] into words1 at index i
vector<string> newSentence;
for (int k = 0; k < i; k++) {
newSentence.push_back(words1[k]);
}
for (int k = i; k < j; k++) {
newSentence.push_back(words2[k]);
}
for (int k = i; k < words1.size(); k++) {
newSentence.push_back(words1[k]);
}
// If the new sentence matches the longer sentence, return True
if (newSentence == words2) {
return true;
}
}
}
// If no match is found, return False
return false;
}
};
2. Java Try on Compiler
class Solution {
public boolean areSentencesSimilar(String sentence1, String sentence2) {
String[] words1 = sentence1.split(" ");
String[] words2 = sentence2.split(" ");
// Ensure words1 is the shorter or equal in length for easier handling
if (words1.length > words2.length) {
String[] temp = words1;
words1 = words2;
words2 = temp;
}
// Iterate over all possible insertion points in words1
for (int i = 0; i <= words1.length; i++) {
for (int j = i; j <= words2.length; j++) {
// Create a new sentence by inserting words2[i:j] into words1 at index i
List<String> newSentence = new ArrayList<>();
for (int k = 0; k < i; k++) {
newSentence.add(words1[k]);
}
for (int k = i; k < j; k++) {
newSentence.add(words2[k]);
}
for (int k = i; k < words1.length; k++) {
newSentence.add(words1[k]);
}
// If the new sentence matches the longer sentence, return True
if (newSentence.equals(Arrays.asList(words2))) {
return true;
}
}
}
// If no match is found, return False
return false;
}
}3. Python Try on Compiler
class Solution:
def areSentencesSimilar(self, sentence1: str, sentence2: str) -> bool:
words1 = sentence1.split()
words2 = sentence2.split()
# Ensure words1 is the shorter or equal in length for easier handling
if len(words1) > len(words2):
words1, words2 = words2, words1
# Iterate over all possible insertion points in words1
for i in range(len(words1) + 1):
for j in range(i, len(words2) + 1):
# Create a new sentence by inserting words2[i:j] into words1 at index i
newSentence = words1[:i] + words2[i:j] + words1[i:]
# If the new sentence matches the longer sentence, return True
if newSentence == words2:
return True
# If no match is found, return False
return False4. JavaScript Try on Compiler
var areSentencesSimilar = function(sentence1, sentence2) {
let words1 = sentence1.split(' ');
let words2 = sentence2.split(' ');
// Ensure words1 is the shorter or equal in length for easier handling
if (words1.length > words2.length) {
[words1, words2] = [words2, words1]; // Swap words1 and words2
}
// Iterate over all possible insertion points in words1
for (let i = 0; i <= words1.length; i++) {
for (let j = i; j <= words2.length; j++) {
// Create a new sentence by inserting words2[i:j] into words1 at index i
let newSentence = [];
// Add words from words1 before index i
for (let k = 0; k < i; k++) {
newSentence.push(words1[k]);
}
// Add words from words2 from index i to j
for (let k = i; k < j; k++) {
newSentence.push(words2[k]);
}
// Add words from words1 after index i
for (let k = i; k < words1.length; k++) {
newSentence.push(words1[k]);
}
// If the new sentence matches words2, return true
if (newSentence.join(' ') === words2.join(' ')) {
return true;
}
}
}
// If no match is found, return false
return false;
};Time Complexity : O(n^3)
Outer Loop (Iterating i):
- The first loop runs from 0 to len(words1) + 1, so it iterates approximately O(n) times, where n is the length of words1.
Inner Loop (Iterating j):
- For each value of i, the inner loop runs from i to len(words2) + 1. In the worst case, this also iterates approximately O(m) times, where m is the length of words2.
Sentence Construction:
- Inside the nested loops, constructing new_sentence = words1[:i] + words2[i:j] + words1[i:] involves slicing and concatenation, which takes O(n + m) time, as it depends on the lengths of words1 and words2.
Combining all steps:
- The loops themselves run approximately O(n × m) times.
- Each iteration requires O(n + m) for slicing and concatenation.
- Hence, the overall time complexity is O(n × m × (n + m)), which simplifies to O(n³) in the worst case when n ≈ m.
Space Complexity : O(n1+n2)
Auxiliary Space Complexity: The extra space that is taken by an algorithm temporarily to finish its work apart from input space
- Temporary String (new_sentence):In each iteration, a temporary string may be constructed from parts of sentence1 or sentence2. The size of this temporary string is proportional to the combined lengths of the sentences, i.e., O(n1+n2).
Total space complexity
Space for input - O(n1) + O(n2)
Auxiliary space - O(n1) + O(n2)
Total space complexity - O(n1+n2)+ O(n1+n2) ≈ O(n1+n2)
where n1,n2 are lengths of the both sentences
For the given constraints of at most 100 characters per sentence, the current time complexity is acceptable. However, if the constraints increase significantly (e.g., sentences with up to 10^6 characters), the solution's efficiency becomes critical, requiring us to reassess its time and space complexities. And what if we get the same scenario at the interview with larger constraints, can we manage that? off course we can….. by analysing few factors...
Optimal Approach
Intuition
Imagine you're given two sentences, and you need to figure out if one can be transformed into the other by adding just a few words. The naive approach might be to try every possible way to insert words from the longer sentence into the shorter one. But, think about it—this feels like searching for a needle in a haystack! It’s bound to be slow and inefficient. What if we could do this more cleverly?
Let's think about the problem in a smarter way
Consider the below one, to dive into our intuition now with the examples we need to return true.
Sentence1 = “Hi manu”
Sentence2 = “Hi I am manu”
Now, if we observe the above example carefully, the longest common prefix of both sentence1 and sentence2 is “Hi” , am i correct ? yesss. What would be the longest common suffix for both ? its “manu”. Then inserting “I am” in sentence1 at center can make our sentence1 equal to sentence2? Yes , definitely we can.
Now, consider one more example,
Sentence1 = “Hi”
Sentence2 = “Hi I am manu”
What are the common things we have observed here? There is a common prefix for both, that is “Hi”, isn’t it?
So, can’t we insert “I am manu” at the end of the sentence1 to make it equal to sentence2? Yes, definitely we can do it.
Let’s have another sample case , where we can return true.
Sentence1 = “manu”
Sentence2 = “Hi I am manu”
Similarly, like above patterns we observed the common suffix for both sentences right!!!!1
Be attentive now, from the above all, the cases are returning True only right!!!
If you observe one point, while comparing both sentences the whole first sentence is being common in the second sentence as common prefix or common suffix or both.
Okay let's consider one more case where we need to return False.
Sentence1 = “Hi manu Hello”
Sentence2 = “Hi I am manu”
By seeing with our naked eye can we just say what could be the answer for it? We cannot make sentence 1 as sentence 2 right! Why because we are supposed insert only one single sentence or nothing , though we insert “I am” in the first one , still “Hello” makes the both sentences different, so we can only make sentence equal whenever the sentence with less words are common as either as the prefix or the suffix or both.Let’s Consider one more example
Sentence1 = “Hi I am manu”
Sentence2 = “Hey Hi I am manu Dir”
If we observe the above example, there is no common prefix or common suffix between these sentences right , except at middle, but if we want make sentence1 as sentence2, we need to insert “Hey” at the front and “Dir” at the end of the sentence1 right! But, as per the rules we can only insert one sentence or nothing right ! so we can’t make sentence1 and sentence2 similar.
Here Two-Pointers concept works well for our problem:We will start comparing the words in each sentence from starting until they are equal by initializing two pointers, one at the starting of the first sentence and another at the starting of the second one, simalary from the ending we will compare the words in each sentence until they are equal by taking another two pointers. After traversing both sides if known that smallest sentence covered fully then we return true, else false
But how can we know whether we covered the full sentence or not?
Simple , as we discussed previously, we initialized one pointer at the starting and one at the end of the sentence 1 right , whenever they cross each other i.e right pointer value becomes less than the left pointer value, then we return True.
Approach
Step 1: Split the Sentences into Words:
- First, split both sentences into lists of words. This allows us to work with each word individually.
Step 2: Ensuring that the first list has less number of words using condition by swapping if necessary.
Step 3: Define the Pointers:
- l1 and l2: These will move from the left side of sentence1 and sentence2, respectively, checking for the longest common prefix.
- r1 and r2: These will move from the right side of sentence1 and sentence2, respectively, checking for the longest common suffix.
Step 4: Match the Prefix:
Using while loop
- Start by moving l1 from the left side of sentence1 and l2 from the left side of sentence2, checking for matching words.
- Continue moving them forward until we encounter a mismatch or reach the end of either sentence.
Step 5: Match the Suffix:
Using while loop
- Now, move r1 from the right side of sentence1 and r2 from the right side of sentence2, checking for matching words.
- Continue moving them backward until we encounter a mismatch or reach the start of either sentence.
Step 6: Check whether word1 covered fully or not:
- If l1>r1 : Pointers l1,r1 covered fully
- Else: Not covered fully
Step 7: Return Result:
- If word1 is covered fully , return True.
- Otherwise, return False.
Let us understand this with a video ,
Sentence Similarity III-Optimal-Approach
Dry Run
Input:
sentence1 = "the sky is blue"
sentence2 = "the beautiful sky is blue"
Output : True
Explanation : beautiful can be inserted between ‘the’ and ‘sky’ . So that both sentences become similar now.
- Splitting the sentences into words:
words1 = ["the", "sky", "is", "blue"]
words2 = ["the", "beautiful", "sky", "is", "blue"]
- Swapping (if needed):
As the len(words1) < len(words2), no swapping is required.
- Initializing pointers:
l1 = 0, l2 = 0 (left pointers for both sentences)
r1 = 3 (last index of words1), r2 = 4 (last index of words2)
Matching the Prefix (Left Side):
- Compare words1[l1] and words2[l2] step by step:
words1[0] == words2[0] → "the" == "the" → Match! Increment both pointers: l1 = 1, l2 = 1
words1[1] == words2[1] → "sky" == "beautiful" → No match! Stop matching the prefix.
- Result:
Prefix match ends with "the".
Matching the Suffix (Right Side):
- Compare words1[r1] and words2[r2] step by step:
words1[3] == words2[4] → "blue" == "blue" → Match! Decrement both pointers: r1 = 2, r2 = 3
words1[2] == words2[3] → "is" == "is" → Match! Decrement both pointers: r1 = 1, r2 = 2
words1[1] == words2[2] → "sky" == "sky" → Match! Decrement both pointers: r1 = 0, r2 = 1
- Result:
Suffix match is "sky is blue".
Checking the Final Condition:
- Condition: Check if r1 < l1 (i.e., if the entire sentence1 is matched).
At this point: r1 = 0, l1 = 1.
Since r1 < l1 is True, the function returns True.
Final Output:
- sentence1 is a subsequence of sentence2.
- Result: True
Optimal Code in all Languages
1. C++ Try on Compiler
class Solution {
public:
bool areSentencesSimilar(string sentence1, string sentence2) {
// Split sentences into lists of words
vector<string> words1, words2;
stringstream ss1(sentence1), ss2(sentence2);
string word;
// Split sentence1 into words
while (ss1 >> word) {
words1.push_back(word);
}
// Split sentence2 into words
while (ss2 >> word) {
words2.push_back(word);
}
// Ensuring that words1 should have the less length
if (words1.size() > words2.size()) {
swap(words1, words2);
}
// Initialize pointers for left and right ends
int l1 = 0, l2 = 0;
int r1 = words1.size() - 1, r2 = words2.size() - 1;
// Match the prefix (left side)
while (l1 < words1.size() && words1[l1] == words2[l2]) {
l1++;
l2++;
}
// Match the suffix (right side)
while (r1 >= 0 && words1[r1] == words2[r2]) {
r1--;
r2--;
}
// Check if the entire sentence1 has been covered by matching prefix and suffix
// The remaining part in the middle should only be extra words in the longer sentence
return r1 < l1;
}
};2. Java Try on Compiler
class Solution {
public boolean areSentencesSimilar(String sentence1, String sentence2) {
// Split sentences into lists of words
String[] words1 = sentence1.split(" ");
String[] words2 = sentence2.split(" ");
// Ensuring that words1 should have the less length
if (words1.length > words2.length) {
String[] temp = words1;
words1 = words2;
words2 = temp;
}
// Initialize pointers for left and right ends
int l1 = 0, l2 = 0;
int r1 = words1.length - 1, r2 = words2.length - 1;
// Match the prefix (left side)
while (l1 < words1.length && words1[l1].equals(words2[l2])) {
l1++;
l2++;
}
// Match the suffix (right side)
while (r1 >= 0 && words1[r1].equals(words2[r2])) {
r1--;
r2--;
}
// Check if the entire sentence1 has been covered by matching prefix and suffix
// The remaining part in the middle should only be extra words in the longer sentence
return r1 < l1;
}
}3. Python Try on Compiler
class Solution:
def areSentencesSimilar(self, sentence1: str, sentence2: str) -> bool:
# Split sentences into lists of words
words1 = sentence1.split()
words2 = sentence2.split()
# Ensuring words1 is the shorter or equal in length
if len(words1) > len(words2):
words1, words2 = words2, words1
# Initialize pointers for left and right ends
l1, l2 = 0, 0
r1, r2 = len(words1) - 1, len(words2) - 1
# Match the prefix (left side)
while l1 < len(words1) and words1[l1] == words2[l2]:
l1 += 1
l2 += 1
# Match the suffix (right side)
while r1 >= 0 and r2 >= l2 and words1[r1] == words2[r2]:
r1 -= 1
r2 -= 1
# Check if the entire words1 has been covered by matching prefix and suffix
return r1 < l1
4. JavaScript Try on Compiler
var areSentencesSimilar = function(sentence1, sentence2) {
// Split sentences into lists of words
let words1 = sentence1.split(' ');
let words2 = sentence2.split(' ');
// Ensuring that words1 should have the less length
if (words1.length > words2.length) {
[words1, words2] = [words2, words1]; // Swap words1 and words2
}
// Initialize pointers for left and right ends
let l1 = 0, l2 = 0;
let r1 = words1.length - 1, r2 = words2.length - 1;
// Match the prefix (left side)
while (l1 < words1.length && words1[l1] === words2[l2]) {
l1++;
l2++;
}
// Match the suffix (right side)
while (r1 >= 0 && words1[r1] === words2[r2]) {
r1--;
r2--;
}
// Check if the entire sentence1 has been covered by matching prefix and suffix
// The remaining part in the middle should only be extra words in the longer sentence
return r1 < l1;
};
Time Complexity: O(n1+n2)
Splitting the sentences into words:
- For splitting both sentences as words take O(n1) and O(n2) time, where n1 and n2 are the lengths of sentence1 and sentence2, respectively.
Traversing the sentences:
- At worst case we need to traverse the both sentences fully takes O(n1) + O(n2)
Total Time complexity : O(n1+n2)
Space Complexity : O(n1+n2)
Auxiliary Space Complexity: The extra space that is taken by an algorithm temporarily to finish its work apart from input space
- Splitting the sentences creates two word lists, requiring O(n1+n2) space.
- Pointers l1, l2, r1, and r2 use O(1).
- Total auxiliary space is O(n1+n2).
Total Space Complexity
Inputs space for both strings - O(n1) + O(n2) = O(n1+n2)
Auxiliary space - O(n1+n2)
Total Space Complexity - O(n1+n2) + O(n1+n2) = O(2(n1+n2)) ≈ O(n1+n2), where n1 and n2 are the lengths of sentence1 and sentence2, respectively.
Learning Tip
A permutation of an array of integers is an arrangement of its members into a sequence or linear order.
For example, for arr = [1,2,3], the following are all the permutations of arr: [1,2,3], [1,3,2], [2, 1, 3], [2, 3, 1], [3,1,2], [3,2,1].
The next permutation of an array of integers is the next lexicographically greater permutation of its integer. More formally, if all the permutations of the array are sorted in one container according to their lexicographical order, then the next permutation of that array is the permutation that follows it in the sorted container. If such arrangement is not possible, the array must be rearranged as the lowest possible order (i.e., sorted in ascending order).
For example, the next permutation of arr = [1,2,3] is [1,3,2].
Similarly, the next permutation of arr = [2,3,1] is [3,1,2].
While the next permutation of arr = [3,2,1] is [1,2,3] because [3,2,1] does not have a lexicographical larger rearrangement.
Given an array of integers nums, find the next permutation of nums.
The replacement must be in place and use only constant extra memory.
Given a positive integer n find the smallest integer which has exactly the same digits existing in the integer n and is greater in value than n. If no such positive integer exists, return -1
Note that the returned integer should fit in 32-bit integer, if there is a valid answer but it does not fit in 32-bit integer, return -1.