String Compression
Problem Description
Given an array of characters chars, compress it using the following algorithm:
Begin with an empty string s. For each group of consecutive repeating characters in chars:
- If the group's length is 1, append the character to s.
- Otherwise, append the character followed by the group's length.
The compressed string s should not be returned separately, but instead, be stored in the input character array chars. Note that group lengths that are 10 or longer will be split into multiple characters in chars.
After you are done modifying the input array, return the new length of the array.
You must write an algorithm that uses only constant extra space.
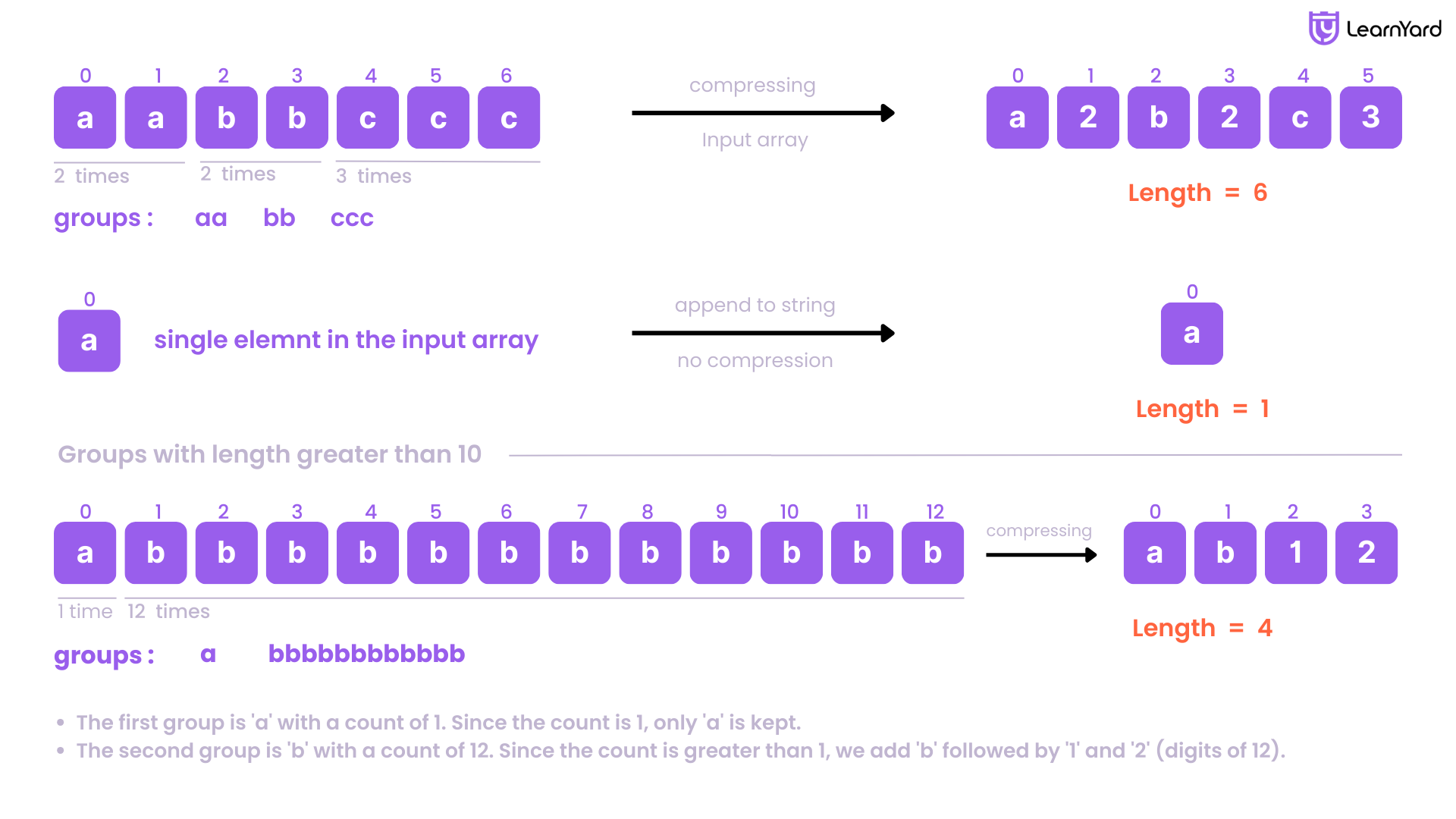
Examples
Input: chars = [‘a’,’a’,’b’,’b’,’c’,’c’,’c’]
Output: Return 6, and the first 6 characters of the input array should be: [‘a’,’2’,’b’,’2’,’c’,’3’]
Explanation: The groups are "aa", "bb", and "ccc". This compresses to "a2b2c3".
Input: chars = [‘a’]
Output: Return 1, and the first character of the input array should be: [‘a’]
Explanation: The only group is ‘a’, which remains uncompressed since it's a single character.
Input: chars = [‘a’,’b’,’b’,’b’,’b’,’b’,’b’,’b’,’b’,’b’,’b’,’b’,’b’]
Output: Return 4, and the first 4 characters of the input array should be: [‘a’,’b’,’1’,’2’].
Explanation: The groups are "a" and "bbbbbbbbbbbb". This compresses to "ab12".
Constraints
- 1 <= chars.length <= 2000
- chars[i] is a lowercase English letter, uppercase English letter, digit, or symbol.
The problem wants us to do the compression and modify itself in the input array. Let’s just now forget about the modification part and let’s focus on our main objective which is the string compression part.
Brute Force Approach
Intuition
Imagine you’re given a list of characters (e.g., ['a', 'a', 'b', 'b', 'b', 'c', 'c']). This list represents a series of letters, and some of these letters repeat consecutively. Your task is to compress this list into a shorter format where:
- If a letter appears multiple times in a row, it is compressed.
- If a letter appears only once, it stays the same.
The challenge is to modify the original list in place (without using extra space) and return the new length of the compressed list but what we are going to do is that we will use up some auxiliary space complexity and currently focus on the compression part not the part where we need to modify the input chars itself using constant space.
What Does Compression Mean?
To compress a group of repeated characters, you count how many times the same character appears consecutively:
- If the character repeats, write it once, followed by the count.
- For example, [‘a', 'a', 'a'] becomes ['a', '3'].
- If the character appears only once, you write just the character.
- For example, 'b' stays 'b'.
The compressed version must replace the original list.
Understanding the Compression Process
- Group Characters: Group together characters that appear consecutively.
- For ['a', 'a', 'b', 'b', 'b', 'c', 'c'], the groups are:
- Group 1: ['a', 'a']
- Group 2: ['b', 'b', 'b']
- Group 3: ['c', 'c']
- For ['a', 'a', 'b', 'b', 'b', 'c', 'c'], the groups are:
- Count the Group Length of each group: For each group, count how many times the character repeats:
- For ['a', 'a'], the count is 2.
- For ['b', 'b', 'b'], the count is 3.
- For ['c', 'c'], the count is 2.
- Write the Compressed Version: We will use a data structure to explicitly store the compression version.
- For 'a' (count = 2), write ['a', '2'].
- For 'b' (count = 3), write ['b', '3'].
- For 'c' (count = 2), write ['c', '2'].
It’s readily visible that all we need is:
- The current character we are processing.
- The count of how many times the character occurs consecutively.
These two things will make up most of the processing part and all we will be left with after this would be to update the information back into the chars list.
To figure out the current character and how many times it repeats in a row, we need a way to "look" at each character and move through the list one step at a time. This is where the pointer comes in. It helps us keep track of our position in the list.
Think of the pointer as a finger pointing to the first character of the group we want to process. As long as the character under the pointer is the same as the next one, we know they belong to the same group, so we can count them. Once we find a different character, we stop counting and know the group is complete.
For example, If the list is ['a','a','b','b','b','c'], we start with the pointer at the first 'a'. We count how many times 'a' appears (2 times), then move the pointer to the first 'b'. Now we do the same for 'b' (3 times) and then for 'c' (1 time). By moving the pointer step by step and counting, we know the current character and its count for each group in the list.
This is why the pointer is essential; it tells us where the group starts and helps us move to the next group once we're done.
We need a way to store two related values: the character and its count. In C++, the best way to represent such a relationship is by using a pair.
- A pair allows us to group the character and its count as a single unit.
- To store all the groups, we can use a vector of pairs (vector<pair<char, int>>). Each pair in the vector will represent one group in the compressed string.
How Does the Vector of Pairs Help?
Each group in the string is represented as a pair of the character and its count. For example:
- The string ['a', 'a', 'b', 'b', 'b', 'c'] would compress to vector<pair<char, int>> = {{'a', 2}, {'b', 3}, {'c', 1}}.
This intermediate representation makes the compression process much simpler as you can focus on accurately counting groups without worrying about updating the original string immediately and also it keeps all the compressed information organized and ready for the final step.
Once we have the compressed version stored in the vector of pairs, we can use it to update the original string. Here’s how:
- Use a second pointer to track the position in the original string (chars) where updates need to be made.
- For each pair in the vector:
- Write the character to the current position in chars.
- Write the count (as digits) to the subsequent positions in chars.
- Increment the pointer after every update to ensure the next group’s data is placed in the correct position.
Example: For the compressed data vector<pair<char, int>> = {{'a', 2}, {'b', 3}, {'c', 1}}:
- Start with the pointer at index 0.
- Write 'a' and 2 → chars = ['a', '2', ...].
- Write 'b' and 3 → chars = ['a', '2', 'b', '3', ...].
- Write 'c' and 1 → chars = ['a', '2', 'b', '3', 'c', '1'].
The pointer ensures that every update is placed in the correct position in chars.
Finally, what we need to return is the new length of the array. An observation here which is fascinating is that the final position of the second pointer (“writer”) will eventually end on the length of the array that needs to be returned. Now let’s understand this deeply.
How does the second pointer represent the length of the new array after the entire string has been processed?
In an array, the first element is at index 0, the second element is at index 1, and so on. If an array has n elements, the last element will always be at index n - 1. For example, in an array with 5 elements like [a, b, c, d, e], the indexes are 0, 1, 2, 3, 4. The position immediately after the last element is at index n. This index doesn’t hold any data, but it tells us that the array has n elements. For instance, in [a, b, c, d, e], the last index is 4, and the next position (5) represents the length of the array, as there are 5 elements total.
It works because the position of the pointer naturally aligns with the number of elements. If the pointer has moved to index 5, it means we’ve written 5 elements (0 to 4), so the length is 5. This is a fundamental relationship between indexes and lengths in arrays: the position after the last index always equals the total number of elements.
As we update the array with compressed data, the second pointer moves forward with each character or number we write. By the time we finish writing, the pointer is sitting at the position just past the last written element. This position tells us exactly how many elements were written, which is the length of the compressed array.
This is why returning the position of the writer pointer after processing is equivalent to returning the length of the compressed string, it’s counting how far we’ve written, and that distance is the length of the new array.
Let us understand with a video,
Dry-run
Input: chars = ['a', 'b', 'c', 'c'].
Output: 4 (chars = [‘a,’b’,’c’,’2’])
Explanation: count of ‘a’ is 1, count of ‘b’ is 1 so they will be as it is. Count of ‘c’ is 2 so we need to write 2 after ‘c’
Initial Setup:
- n = 4 (size of chars)
- itr = 0 (iterator to traverse the chars array)
- compressedString = [] (to temporarily store the compressed groups)
Step 1: First While Loop1st iteration (Character: 'a')
- Initialization:
- grpSize = 1 (group size starts with 1, as each character is a group at the start).
- Inner While Loop:
- Condition: itr + grpSize < n (0 + 1 < 4) and chars[itr + grpSize] == chars[itr] ('b' ≠ 'a').
- No consecutive characters, so the loop doesn't execute.
- Store Group:
- Add the group {'a', 1} to compressedString: compressedString = [{'a', 1}].
- Update Iterator:
- itr += grpSize → itr = 1 (move to the next character).
2nd iteration (Character: 'b')
- Initialization:
- grpSize = 1.
- Inner While Loop:
- Condition: itr + grpSize < n (1 + 1 < 4) and chars[itr + grpSize] == chars[itr] ('c' ≠ 'b').
- No consecutive characters, so the loop doesn't execute.
- Store Group:
- Add the group {'b', 1} to compressedString: compressedString = [{'a', 1}, {'b', 1}].
- Update Iterator:
- itr += grpSize → itr = 2 (move to the next character).
3rd iteration (Character: 'c')
- Initialization:
- grpSize = 1.
- Inner While Loop:
- Condition: itr + grpSize < n (2 + 1 < 4) and chars[itr + grpSize] == chars[itr] ('c' == 'c').
- Increment grpSize: grpSize = 2.
- Store Group:
- Add the group {'c', 2} to compressedString: compressedString = [{'a', 1}, {'b', 1}, {'c', 2}].
- Update Iterator:
- itr += grpSize → itr = 4 (exit the loop as itr >= n).
Compressed Groups After First Loop: compressedString = [{'a', 1}, {'b', 1}, {'c', 2}]
Step 2: Second Loop (Updating chars) Initialization:
- idx = 0 (pointer to write the compressed characters into chars).
1st Group (Character: 'a', Count: 1)
- Write 'a' at chars[idx]: chars = ['a', 'b', 'c', 'c'], idx = 1.
- Count is 1, so no digits are added.
2nd Group (Character: 'b', Count: 1)
- Write 'b' at chars[idx]: chars = ['a', 'b', 'c', 'c'], idx = 2.
- Count is 1, so no digits are added.
3rd Group (Character: 'c', Count: 2)
- Write 'c' at chars[idx]: chars = ['a', 'b', 'c', 'c'], idx = 3.
- Count is greater than 1, so convert 2 to string ("2") and write each digit:
- Write '2' at chars[idx]: chars = ['a', 'b', 'c', '2'], idx = 4.
Final Output:
- Compressed chars = ['a', 'b', 'c', '2'].
- idx = 4 (length of the compressed string).
Return Value: 4 (length of the compressed string).
Steps to write code
Step 1: Initialize Variables
- Create a variable n to store the size of the chars array.
- Create an iterator itr to traverse the array.
- Declare a vector<pair<char, int>> compressedString to store the compressed groups (character + count).
Step 2: Traverse the Array
- Use a while loop to iterate through the array (itr < n).
- Initialize grpSize to 1 (representing the current character itself).
- Use a nested while loop to check for consecutive characters:
- Increment grpSize while the next character is the same as the current one (chars[itr + grpSize] == chars[itr]).
- After the nested loop ends, you have the count of the current group.
Step 3: Store Compressed Data
- Push the current character and its count as a pair into compressedString.
- Move the itr pointer forward by the size of the current group (grpSize).
Step 4: Write Compressed Data Back to chars
- Initialize an idx pointer to keep track of where to write in chars.
- Use a for loop to iterate through each pair in compressedString:
- Write the character (group.first) to chars[idx] and increment idx.
- If the count (group.second) is greater than 1:
- Convert the count to a string using to_string().
- Write each digit of the count into chars and increment idx.
Step 5: Return the Length of the Compressed Array
- The value of idx now represents the length of the compressed array.
- Return idx as the result.
Brute Force in All Languages
C++
class Solution {
public:
int compress(vector<char>& chars) {
// Get the size of the input array
int n = chars.size();
// Pointer to traverse the input array
int itr = 0;
// Data structure to store compressed information (character, count)
vector<pair<char, int>> compressedString;
// Iterate over the array to create compressed groups
while (itr < n) {
// Initialize the size of the current group to 1
int grpSize = 1;
// Expand the group for consecutive identical characters
while (itr + grpSize < n && chars[itr + grpSize] == chars[itr]) {
grpSize++;
}
// Store the character and its count in the compressed string
compressedString.push_back({chars[itr], grpSize});
// Move the iterator to the next unique character
itr += grpSize;
}
// Index to modify the original array with compressed format
int idx = 0;
// Write compressed data back into the original array
for (auto group : compressedString) {
// Write the character
chars[idx++] = group.first;
// Write the count if greater than 1
if (group.second > 1) {
for (char c : to_string(group.second)) {
chars[idx++] = c;
}
}
}
// Return the new length of the compressed array
return idx;
}
};Java
class Solution {
public int compress(char[] chars) {
int n = chars.length;
int itr = 0;
// List<int[]> to store compressed information (character as int, count)
List<int[]> compressedString = new ArrayList<>();
// Iterate over the array to create compressed groups
while (itr < n) {
int grpSize = 1;
// Expand the group for consecutive identical characters
while (itr + grpSize < n && chars[itr + grpSize] == chars[itr]) {
grpSize++;
}
// Store the character and its count in the compressed string
compressedString.add(new int[]{chars[itr], grpSize});
// Move the iterator to the next unique character
itr += grpSize;
}
// Index to modify the original array with compressed format
int idx = 0;
// Write compressed data back into the original array
for (int[] group : compressedString) {
// Write the character
chars[idx++] = (char) group[0];
// Write the count if greater than 1
if (group[1] > 1) {
for (char c : String.valueOf(group[1]).toCharArray()) {
chars[idx++] = c;
}
}
}
// Return the new length of the compressed array
return idx;
}
}Python
class Solution:
def compress(self, chars: List[str]) -> int:
# Get the size of the input array
n = len(chars)
# Pointer to traverse the input array
itr = 0
# Data structure to store compressed information (character, count)
compressed_string = []
# Iterate over the array to create compressed groups
while itr < n:
# Initialize the size of the current group to 1
grp_size = 1
# Expand the group for consecutive identical characters
while itr + grp_size < n and chars[itr + grp_size] == chars[itr]:
grp_size += 1
# Store the character and its count in the compressed string
compressed_string.append((chars[itr], grp_size))
# Move the iterator to the next unique character
itr += grp_size
# Index to modify the original array with compressed format
idx = 0
# Write compressed data back into the original array
for group in compressed_string:
# Write the character
chars[idx] = group[0]
idx += 1
# Write the count if greater than 1
if group[1] > 1:
for c in str(group[1]):
chars[idx] = c
idx += 1
# Return the new length of the compressed array
return idxJavascript
/**
* @param {character[]} chars
* @return {number}
*/
var compress = function(chars) {
let n = chars.length;
let itr = 0;
// Array to store compressed information
let compressedString = [];
// Create compressed groups
while (itr < n) {
let grpSize = 1;
// Expand the group for consecutive identical characters
while (itr + grpSize < n && chars[itr + grpSize] === chars[itr]) {
grpSize++;
}
// Store the character and its count in the compressed string
compressedString.push([chars[itr], grpSize]);
// Move to the next unique character
itr += grpSize;
}
// Write compressed data back into the original array
let idx = 0;
for (let group of compressedString) {
chars[idx++] = group[0]; // Write character
if (group[1] > 1) {
for (let c of String(group[1])) {
chars[idx++] = c; // Write count
}
}
}
// Return the new length of the compressed array
return idx;
};Time Complexity: O(n)
We need to analyze the two main parts of the code:
- Building the compressedString vector
- Modifying the chars array using the compressedString
Part 1: Building the compressedString
This part corresponds to the while loop in the code:
- The outer loop (while (itr < n)) iterates over all characters in the array. Each iteration processes one group of characters.
- The inner loop (while (itr + grpSize < n && chars[itr + grpSize] == chars[itr])) counts consecutive characters within a group.
- For each group of size grpSize, the inner loop runs grpSize times to count all characters in that group.
- After counting, the pointer itr is incremented by grpSize, skipping all the characters in the group.
Thus, the total number of iterations of the inner loop across all groups is equal to nnn (the length of the input). This is because each character is processed exactly once, either by the outer loop or the inner loop.
Time Complexity for Part 1: O(n)
Part 2: Modifying the chars Array
This part corresponds to the for loop:
- The for loop iterates over all groups stored in compressedString.
- For each group:
- Writing the character (chars[idx++] = group.first) takes O(1).
- Writing the count (group.second) depends on the number of digits in the count.
Digits in a Count:
- If the count is grpSize, the number of digits is approximately O(log10(grpSize)). In the worst case, grpSize can be as large as n (when all characters are identical), so writing the digits takes O(log10(n)) in the worst case.
- Summing over all groups, the total number of digits written is at most n (because every character in the array contributes to the total count, either as a single character or part of a number).
Thus, writing all the compressed information back to chars takes O(n) in total.
Time Complexity for Part 2: O(n)
Overall Time Complexity
The code processes each character of the input array exactly twice:
- Once while building the compressedString.
- Once while modifying the chars array.
Thus, the total time complexity is: O(n)+O(n)=O(n)
Space Complexity: O(n)
Auxiliary Space Complexity
It refers to the additional memory allocated by the program apart from the input and output.
compressedString Vector
- This vector stores pairs of characters and their counts.
- Each element in the vector is a pair<char, int>.
- If the input string has g groups of consecutive characters, the vector will have g elements.
- For example:
- Input: chars = ['a', 'a', 'b', 'b', 'c'] → g=3: compressedString = [('a', 2), ('b', 2), ('c', 1)].
- Worst-case: If all characters are distinct, g=n.
- Memory used by one pair:
- char: 1 byte.
- int: 4 bytes (in most systems).
- Total memory for one pair = 1+4=5 bytes.
- In the worst case, g=n, so the memory used by compressedString is: O(g)=O(n×5)=O(n)
Other Variables
- n: Stores the size of the input array → O(1).
- itr and grpSize: Integer variables for iterating and counting → O(1).
- idx: Integer variable for updating the chars array → O(1).
- Temporary storage for the for loop (auto group) → O(1).
Intermediate Storage for to_string
- In the second for loop, the count of a group is converted to a string using to_string.
- The length of this string is proportional to the number of digits in the count.
- For a group size grpSize, the memory required is O(log10(grpSize)).
- Summing across all groups, the intermediate storage for all counts combined is: O(∑log10(grpSize))≤O(n) (since each character contributes to the total count).
The dominant contributor is the compressedString vector. Hence:
Auxiliary Space Complexity=O(n)
Total Space Complexity
Total space complexity includes both auxiliary space and the memory used by the input array:
- Input Array: The input is an array of size n, requiring O(n) space.
Final Space Complexity = O(n) (input array) + O(n) (auxiliary space) = O(n).
The brute force approach will work correctly and pass all the test cases for this problem. However, it does not meet all the requirements outlined in the problem, particularly the need to minimize space usage. This solution uses extra auxiliary space, which isn't ideal.
The purpose of discussing this brute-force solution is to help you think creatively and understand how different data structures can be leveraged in competitive programming contests and online assessments. Now, let's shift our focus to optimizing the solution by reducing the space complexity to use constant space.
Optimal Approach
Intuition
Let’s start with the brute force approach. In that approach, we used extra space (another data structure) to store the compressed version of the string. Now, instead of using extra space, we’ll focus on directly modifying the given chars array to save space. This means we’ll update the characters and their counts right in the original array as we process them.
Here’s the idea: Just like before, we’ll need two-pointers. One pointer will act like a "reader" that looks at the string to figure out the current character and how many times it appears in a row. The second pointer will act like a "writer" which updates the chars array with the compressed information (the character and its count) at the correct position.
For example, when the "reader" processes a group of characters (like 'a', 'a'), it figures out that 'a' appears twice. The "writer" then updates the array by placing 'a' first and then its count ('2') right after it. After writing this, the "writer" moves to the next position, ready to handle the next group of characters. This way, everything is done directly in the original array, and we don’t need to use extra space.
For example, if the list is ['a', 'a', 'b', 'b', 'b', 'c']:
- The reader processes 'a' and finds it repeats 2 times.
- The writer updates the list to ['a', '2', ...].
- Then, the reader processes 'b' and finds it repeats 3 times.
- The writer updates the list to ['a', '2', 'b', '3', ...].
- Finally, the reader processes 'c' and finds it repeats 1 time.
- The writer updates the list to ['a', '2', 'b', '3', 'c'].
In the end, we return the second pointer. This pointer will stop right after the last valid position in the array, which gives us the length of the compressed array.
Let us understand this with a video ,
Video Explaination for Optimal Approach
Dry-run
Input: chars = ['a', 'b', 'c', 'c'].
Output: 4 (chars = [‘a,’b’,’c’,’2’])
Explanation: count of ‘a’ is 1, count of ‘b’ is 1 so they will be as it is. Count of ‘c’ is 2 so we need to write 2 after ‘c’
Initialization:
- n = 4 (size of chars).
- itr = 0 (iterator pointer for processing characters (reader)).
- idx = 0 (pointer for writing compressed data back into chars (writer)).
We use a variable grpSize to calculate group size which is initialized to 1 in the outer loop.
Step 1: First iteration
- Current character at itr = 0: chars[itr] = 'a'
- We write 'a' to chars[idx], so chars[0] = 'a'.
- Now, chars = ['a', 'b', 'c', 'c'].
- Increment idx to 1.
- Calculate grpSize:
- Initialize grpSize = 1 because the current character 'a' is counted once.
- Check the next character at itr + 1 = 1: chars[1] = 'b'.
- Since 'b' is different from 'a', we stop the group count.
- grpSize = 1.
- Since grpSize = 1, no number is appended to the character.
- Move itr to the next character:
- Update itr += grpSize = 0 + 1 = 1.
Step 2: Second iteration
- Current character at itr = 1: chars[itr] = 'b'
- We write 'b' to chars[idx], so chars[1] = 'b'.
- Now, chars = ['a', 'b', 'c', 'c'].
- Increment idx to 2.
- Calculate grpSize:
- Initialize grpSize = 1 because the current character 'b' is counted once.
- Check the next character at itr + 1 = 2: chars[2] = 'c'.
- Since 'c' is different from 'b', we stop the group count.
- grpSize = 1.
- Since grpSize = 1, no number is appended to the character.
- Move itr to the next character:
- Update itr += grpSize = 1 + 1 = 2.
Step 3: Third iteration
- Current character at itr = 2: chars[itr] = 'c'
- We write 'c' to chars[idx], so chars[2] = 'c'.
- Now, chars = ['a', 'b', 'c', 'c'].
- Increment idx to 3.
- Calculate grpSize:
- Initialize grpSize = 1 because the current character 'c' is counted once.
- Check the next character at itr + 1 = 3: chars[3] = 'c'.
- Since 'c' is the same as 'c', we increment grpSize to 2.
- Since grpSize = 2, we append the group size to chars:
- Convert grpSize = 2 to string: "2".
- We write '2' to chars[3].
- Now, chars = ['a', 'b', 'c', '2'].
- Increment idx to 4.
- Move itr to the next character:
- Update itr += grpSize = 2 + 2 = 4.
Step 4: End of the loop
- itr = 4, which is equal to the length of chars (n = 4), so we exit the loop.
Final Result:
- The compressed chars = ['a', 'b', 'c', '2'].
- The length of the compressed string is 4 (since idx = 4).
Steps to write code
Step 1: Initialization:
- n stores the length of the input string.
- itr is the iterator for traversing through the list of characters.
- idx refers to the index for updating the list with the compressed result.
Step 2: Outer While Loop (while (itr < n)):
- This loop ensures that every character in the list is processed until the iterator itr reaches the end of the string.
Step 3: Process Each Group:
- For each character, the first character of the group is stored at chars[idx], and idx is incremented.
- grpSize = 1 is initialized to track the number of consecutive occurrences of the current character.
Step 4: Inner While Loop:
- This loop counts the number of consecutive occurrences of the current character by comparing each successive character with the current one.
Step 5: Handle a case where the group size becomes greater than 1
- If there are multiple occurrences (i.e., grpSize > 1), the group size is converted to a string and the digits are appended to the result in chars.
Step 6: Move to the Next Group:
- Once the group is processed, move itr forward by grpSize to skip over the current group.
Step 7: Return the New Length:
- After processing all groups, idx will hold the length of the compressed string, which is returned.
Optimal Approach in All Languages
C++
class Solution {
public:
int compress(vector<char>& chars) {
// n represents the current size of chars
int n = chars.size();
// itr is the iterator for traversing chars
int itr = 0;
// idx is the index used to update the chars array
int idx = 0;
// Iterate over the array until itr is less than n
while (itr < n) {
// Store the current character at position itr to idx and increment idx
chars[idx++] = chars[itr];
// Initialize the group size for the current character
int grpSize = 1;
// Increment group size for consecutive identical characters
while (itr + grpSize < n && chars[itr + grpSize] == chars[itr]) {
grpSize++;
}
// If the group size is greater than 1, convert it to a string and append to chars
if (grpSize > 1) {
for (char c : to_string(grpSize)) {
chars[idx++] = c;
}
}
// Move to the next character group
itr += grpSize;
}
// Return the new length of the array
return idx;
}
};Java
class Solution {
public int compress(char[] chars) {
// n represents the current size of chars
int n = chars.length;
// itr is the iterator for traversing chars
int itr = 0;
// idx is the index used to update the chars array
int idx = 0;
// Iterate over the array until itr is less than n
while (itr < n) {
// Store the current character at position itr to idx and increment idx
chars[idx++] = chars[itr];
// Initialize the group size for the current character
int grpSize = 1;
// Increment group size for consecutive identical characters
while (itr + grpSize < n && chars[itr + grpSize] == chars[itr]) {
grpSize++;
}
// If the group size is greater than 1, convert it to a string and append to chars
if (grpSize > 1) {
for (char c : String.valueOf(grpSize).toCharArray()) {
chars[idx++] = c;
}
}
// Move to the next character group
itr += grpSize;
}
// Return the new length of the array
return idx;
}
}Python
class Solution:
def compress(self, chars: List[str]) -> int:
# Get the size of the array
n = len(chars)
# itr is the pointer for traversing the array
itr = 0
# idx is the index used to update the array
idx = 0
# Traverse the array while itr is less than n
while itr < n:
# Store the current character at position itr in idx and increment idx
chars[idx] = chars[itr]
idx += 1
# Initialize the group size for the current character
grp_size = 1
# Increment group size for consecutive identical characters
while itr + grp_size < n and chars[itr + grp_size] == chars[itr]:
grp_size += 1
# If the group size is greater than 1, convert it to a string and append to chars
if grp_size > 1:
for c in str(grp_size):
chars[idx] = c
idx += 1
# Move to the next character group
itr += grp_size
# Return the new length of the array
return idxJavascript
/**
* @param {character[]} chars
* @return {number}
*/
var compress = function(chars) {
// Get the size of the array
let n = chars.length;
// itr is the pointer for traversing the array
let itr = 0;
// idx is the index used to update the array
let idx = 0;
// Traverse the array while itr is less than n
while (itr < n) {
// Store the current character at position itr in idx and increment idx
chars[idx++] = chars[itr];
// Initialize the group size for the current character
let grpSize = 1;
// Increment group size for consecutive identical characters
while (itr + grpSize < n && chars[itr + grpSize] === chars[itr]) {
grpSize++;
}
// If the group size is greater than 1, convert it to a string and append to chars
if (grpSize > 1) {
for (let c of String(grpSize)) {
chars[idx++] = c;
}
}
// Move to the next character group
itr += grpSize;
}
// Return the new length of the array
return idx;
};Time Complexity: O(n)
Key Points:
- x is the number of characters where the current character is different from the previous one (i.e., the first occurrence of each distinct character or group).
- y is the number of characters where the current character is the same as the previous one (i.e., repeated characters after the first occurrence).
Outer Loop:
- The outer loop runs once for every distinct group of characters.
- For each distinct group (where the first character of the group is different from the previous one), we process the character and move the pointer itr to the first occurrence of the next distinct character.
- The number of iterations of the outer loop is O(x), where x is the number of distinct groups.
Inner Loop:
- The inner loop counts the number of consecutive occurrences of the current character in a group.
- The number of iterations of the inner loop depends on how many characters repeat consecutively. If a character repeats multiple times, the inner loop will run that many times to account for the repetition.
- The total number of repeated characters across all groups is O(y).
How We Combine Them:
- The outer loop iterates over O(x) distinct groups (first occurrence of each character in the group).
- The inner loop processes the O(y) repeated characters.
Thus, the total number of operations is O(x + y), where:
- x is the number of distinct groups (the first occurrences of characters).
- y is the total number of repeated occurrences (the consecutive characters after the first).
Since x + y = n (where n is the total length of the string), the overall time complexity simplifies to:
O(x+y)=O(n)
Space Complexity: O(log(n))
Auxiliary Space Complexity:
- Integer Variables: The algorithm uses a few integer variables (n, itr, idx, grpSize) to track the current state, such as the size of the input array, the position of the two pointers, and the group size of consecutive characters.
- These integer variables use O(1) space because they store only single integer values and do not depend on the size of the input array.
- Temporary Space for Group Size: In the case where the group size (grpSize) is greater than 1, the algorithm converts the group size into a string using to_string(grpSize) and writes the digits back into the chars array.
- The maximum size for grpSize is determined by how many times a single character can repeat consecutively. In the worst case, the number of digits needed to represent the group size is O(log n), where n is the length of the input array. So, the space used here is O(log n) for storing the digits of grpSize during each iteration.
- However, since this is not an additional data structure and the string representation of grpSize is immediately written back into the input array, this is a temporary space requirement. Thus, it does not add extra space complexity outside of the input array.
- Overall Auxiliary Space: The auxiliary space is primarily determined by the few integer variables and the temporary string used to represent the group size. The overall auxiliary space complexity is O(log n), which is the space used to store the string representation of grpSize.
Total Space Complexity:
- Input Array: The input array (chars) is part of the input, and its space complexity is O(n), where n is the number of characters in the array.
- Auxiliary Space: As we discussed, the auxiliary space complexity is O(log n) due to the temporary string for grpSize.
Thus, the total space complexity is:
O(n) (input array) + O(logn) (auxiliary space) = O(n)
Similar Problems
Now we have successfully tackled this problem, let's try these similar problems:-
The count-and-say sequence is a sequence of digit strings defined by the recursive formula:
- countAndSay(1) = "1"
- countAndSay(n) is the run-length encoding of countAndSay(n - 1).
Run-length encoding (RLE) is a string compression method that works by replacing consecutive identical characters (repeated 2 or more times) with the concatenation of the character and the number marking the count of the characters (length of the run). For example, to compress the string "3322251" we replace "33" with "23", replace "222" with "32", replace "5" with "15" and replace "1" with "11". Thus the compressed string becomes "23321511".
Given a positive integer n, return the nᵗʰ element of the count-and-say sequence.
Given a string word, compress it using the following algorithm:
- Begin with an empty string comp. While word is not empty, use the following operation:
- Remove a maximum length prefix of word made of a single character c repeating at most 9 times.
- Append the length of the prefix followed by c to comp.
Return the string comp.