Reverse Prefix of Word
Problem Description
Given a 0-indexed string word and a character ch, reverse the segment of word that starts at index 0 and ends at the index of the first occurrence of ch (inclusive). If the character ch does not exist in word, do nothing.
For example, if word = "abcdefd" and ch = "d", then you should reverse the segment that starts at 0 and ends at 3 (inclusive). The resulting string will be "dcbaefd".
Return the resulting string.
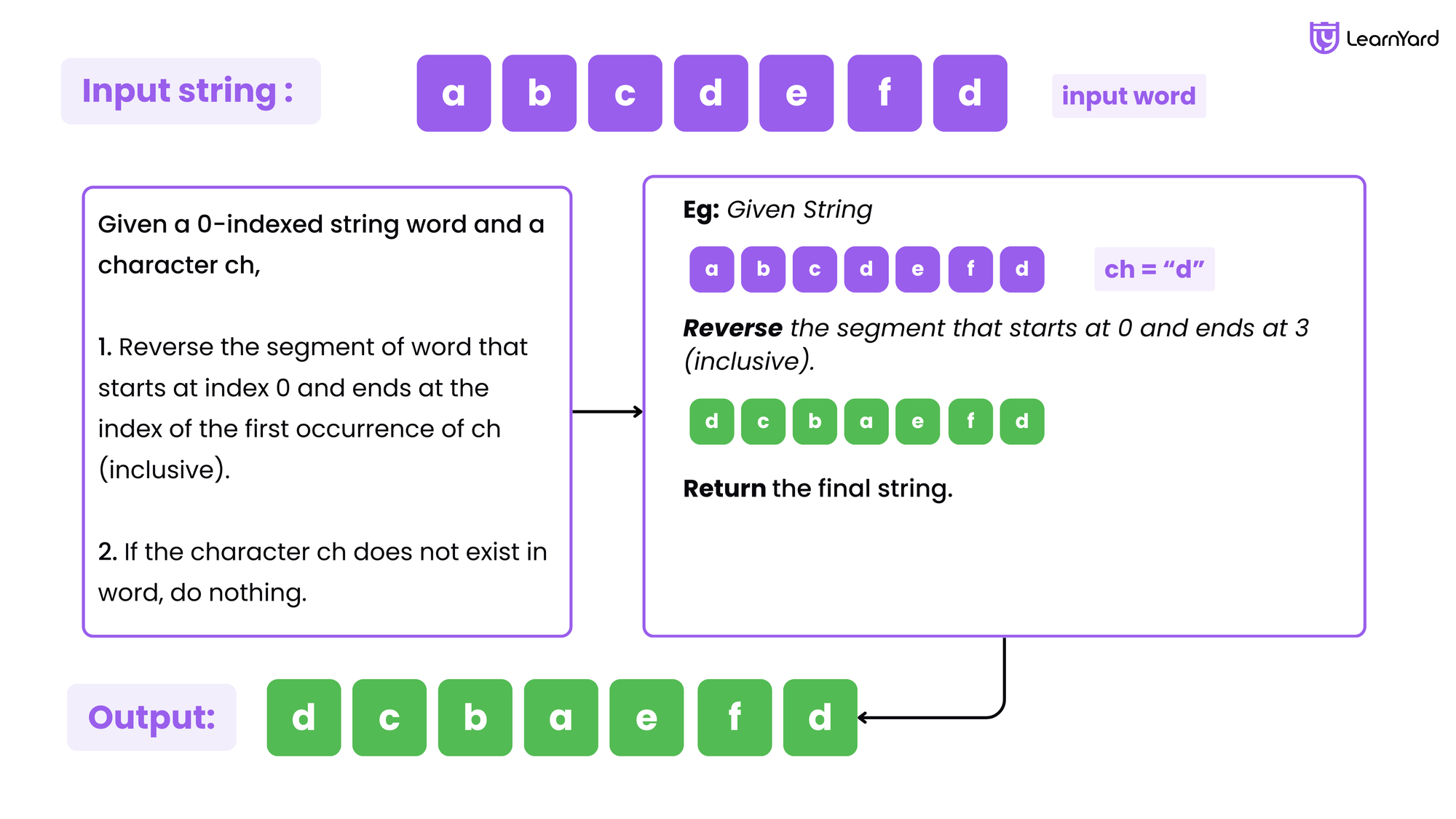
Example
Input: word = "abcdefd", ch = "d"
Output: "dcbaefd"
Explanation: The first occurrence of "d" is at index 3.
Reverse the part of word from 0 to 3 (inclusive), the resulting string is "dcbaefd".
Input: word = "xyxzxe", ch = "z"
Output: "zxyxxe"
Explanation: The first and only occurrence of "z" is at index 3.
Reverse the part of word from 0 to 3 (inclusive), the resulting string is "zxyxxe".
Constraints
- 1 <= word.length <= 250
- word consists of lowercase English letters.
- ch is a lowercase English letter.
Although this problem might seem straightforward, there are different ways to solve it, like forming a new string, or by using two pointers. Each approach has its own benefits and challenges in terms of how fast it works and how much memory it uses.
Brute Force Approach
Intuition
Think of the word as a sequence of characters arranged like beads on a string. Our task is to find the first bead (character) matching 'ch'. Once we find it, we take all the beads from the beginning of the string up to and including that bead, reverse their order, and then place them back at the start of the string. The rest of the string (everything after the bead) will remain untouched.
The first thing we need is the position of 'ch' in the word. Why? Because we can’t reverse the prefix without knowing where to stop. This is like looking for the position of a bead on the string before deciding which part to flip. We go through each character in the string from the start, comparing it to 'ch'. As soon as we find a match, we record the position (index). This index tells us how far to reverse the prefix. Once we find this position, we know the exact range of characters that need to be reversed. After reversing this part, we simply glue the rest of the string back as it was.
How Do We Reverse the Prefix?
Now that we know the index of 'ch', we can reverse the prefix. But what does that mean in simple terms?
Reversing means flipping the order of characters. Imagine the prefix as a row of cards: "abcde". When you reverse it, you flip the cards from back to front: Start with the last character ('e') and move toward the first ('a'). So, "abcde" becomes "edcba".
We achieve this by iterating backward through the prefix, from the character at the index of 'ch' back to the start, and appending each character to a new string.
Approach
Step 1: Initialize Variables
Initialize a variable index to -1. This will store the index of the first occurrence of the character ch. We will also initialize an empty string reversedPart, which will hold the reversed portion of the string, and a final string to store the result.
Step 2: Traverse the String to Find the First Occurrence of 'ch'
Loop through the input string word to find the first occurrence of the character ch.
- For each character, compare it with ch. If a match is found, set index to the current index and exit the loop.
- If ch is not found in the string, return the original string word as no reversal is needed.
Step 3: Construct the Reversed Prefix
Once we have the index of the first occurrence of ch, we need to reverse the portion of the string from index 0 to index (inclusive).
- Loop through the characters from index down to 0 and append each character to the reversedPart string.
Step 4: Append the Remaining Part of the String
After reversing the prefix, loop through the string from index + 1 to the end.
- Append the remaining characters to the reversedPart.
Step 5: Return the Result
Finally, return the reversedPart as the resulting string. This will contain the reversed prefix followed by the remaining part of the original string.
Dry Run
Input: word = "abcdefd", ch = "d"
Initialization:
- word = "abcdefd"
- ch = "d"
- index = -1 (to store the index of the first occurrence of 'd')
- reversedPart = "" (to store the reversed part of the string)
- Final string = "" (to store the final result after combining reversedPart and remaining part of the string)
Step 1: Find the First Occurrence of 'd'
We start iterating through the string "abcdefd" to find the first occurrence of 'd'.
Iteration 1 (i = 0):
- word[0] = 'a'
- 'a' is not equal to 'd', so we continue to the next iteration.
Iteration 2 (i = 1):
- word[1] = 'b'
- 'b' is not equal to 'd', so we continue to the next iteration.
Iteration 3 (i = 2):
- word[2] = 'c'
- 'c' is not equal to 'd', so we continue to the next iteration.
Iteration 4 (i = 3):
- word[3] = 'd'
- 'd' is equal to 'ch', so we set index = 3 and break the loop.
At this point, we have found the first occurrence of 'd' at index 3.
Step 2: Construct the Reversed Part
Now, we need to construct the reversed part of the string, which starts from index 0 and ends at index 3 (inclusive). We will reverse the portion of the string word[0..3].
Iteration 1 (i = 3):
- reversedPart += word[3] = 'd'
- reversedPart = "d"
Iteration 2 (i = 2):
- reversedPart += word[2] = 'c'
- reversedPart = "dc"
Iteration 3 (i = 1):
- reversedPart += word[1] = 'b'
- reversedPart = "dcb"
Iteration 4 (i = 0):
- reversedPart += word[0] = 'a'
- reversedPart = "dcba"
At this point, the reversed part is "dcba".
Step 3: Append the Remaining Part of the String
Now, we need to append the remaining part of the string, which starts from index 4 to the end of the string.
Iteration 1 (i = 4):
- Final string += word[4] = 'e'
- Final string = "e"
Iteration 2 (i = 5):
- Final string += word[5] = 'f'
- Final string = "ef"
Iteration 3 (i = 6):
- Final string += word[6] = 'd'
- Final string = "efd"
Step 4: Combine the Reversed Part and the Remaining Part
Finally, we combine the reversed part "dcba" and the remaining part "efd" to get the final result.
Final result = "dcba" + "efd" = "dcbaefd"
Final Output:
- "dcbaefd"
Code for All Languages
C++
class Solution {
public:
string reversePrefix(string word, char ch) {
// Find the index of the first occurrence of 'ch'
int index = -1;
for (int i = 0; i < word.length(); i++) {
if (word[i] == ch) {
index = i;
break;
}
}
// If 'ch' is not found, return the original string
if (index == -1) {
return word;
}
// Construct the reversed part
string reversedPart = "";
for (int i = index; i >= 0; i--) {
reversedPart += word[i];
}
// Append the remaining part of the string
for (int i = index + 1; i < word.length(); i++) {
reversedPart += word[i];
}
return reversedPart;
}
};Java
class Solution {
public String reversePrefix(String word, char ch) {
// Find the index of the first occurrence of 'ch'
int index = -1;
for (int i = 0; i < word.length(); i++) {
if (word.charAt(i) == ch) {
index = i;
break;
}
}
// If 'ch' is not found, return the original string
if (index == -1) {
return word;
}
// Construct the reversed part
StringBuilder reversedPart = new StringBuilder();
for (int i = index; i >= 0; i--) {
reversedPart.append(word.charAt(i));
}
// Append the remaining part of the string
for (int i = index + 1; i < word.length(); i++) {
reversedPart.append(word.charAt(i));
}
return reversedPart.toString();
}
}
Python
class Solution:
def reversePrefix(self, word: str, ch: str) -> str:
# Find the index of the first occurrence of 'ch'
index = -1
for i in range(len(word)):
if word[i] == ch:
index = i
break
# If 'ch' is not found, return the original string
if index == -1:
return word
# Build the result manually
result = ""
# Add reversed part from index to 0
for i in range(index, -1, -1):
result += word[i]
# Append the remaining part of the string from index + 1 to end
for i in range(index + 1, len(word)):
result += word[i]
return result
Javascript
var reversePrefix = function(word, ch) {
// Find the index of the first occurrence of 'ch'
let index = -1;
for (let i = 0; i < word.length; i++) {
if (word[i] === ch) {
index = i;
break;
}
}
// If 'ch' is not found, return the original string
if (index === -1) {
return word;
}
// Create an array to build the result manually
let result = "";
// Add reversed part from index to 0
for (let i = index; i >= 0; i--) {
result += word[i];
}
// Append the remaining part of the string from index + 1 to end
for (let i = index + 1; i < word.length; i++) {
result += word[i];
}
return result;
};
Time Complexity : O(n)
Finding the Index of ch : O(n)
We iterate through the string word to find the first occurrence of ch. In the worst case, we traverse the entire string, which contains n characters. Each comparison of a character takes O(1), so the total time complexity for this step is O(n).
Building the Reversed Part: O(k)
Once the index of ch is found, we loop from the found index backward to 0 to construct the reversed part of the string. If the index is k, this loop runs k+1 times, where k < n. Thus, the time complexity for this step is O(k).
Appending the Remaining Part: O(n-k-1)
After constructing the reversed part, we loop through the rest of the string starting from k+1 to the end. This loop runs for n-k-1 iterations, where n is the length of the string. Hence, the time complexity is O(n-k-1).
Final Time Complexity: O(n)
The operations for building the reversed and remaining parts are performed sequentially, so their time complexities add up: O(k) + O(n-k-1) = O(n). The dominant term in the overall time complexity is O(n), making the final time complexity O(n).
Space Complexity: O(n)
Auxiliary Space Complexity: O(n)
The auxiliary space refers to the extra space used by the algorithm aside from the input. In this case, we are using the "reversedPart" string to store the reversed prefix and the remaining part of the input string. Since the size of "reversedPart" can be up to the length of the input string, it takes O(n) space. Other variables such as "index" and "i" require constant space, O(1), but the primary contributor to the auxiliary space is "reversedPart".
Total Space Complexity: O(n)
The total space includes both the input (the string "word") and the auxiliary space.
- The input string "word" takes O(n) space, where n is the length of the string.
- The string "reversedPart" will also have a size proportional to the input string, so it takes O(n) space as well.
Thus, the total space complexity is O(n).
Previously, we discussed a brute force approach that involved creating a new string to store the reversed prefix, which required extra memory. Now, let’s optimize by reversing the prefix directly in place within the original string. This approach is more efficient, as it avoids additional memory usage and simplifies the solution while maintaining the same time complexity.
Optimal Approach
Intuition
Think of the brute force approach for a moment. There, we built the reversed prefix by going backward through the string and appending characters to a new string. But what if, instead of building a new string, we could simply swap the characters in the original string itself? To reverse something, like flipping the prefix "abcde" into "edcba", you don’t need to physically create a new string.
We can achieve the same result by swapping:
- Swap 'a' with 'e'
- Swap 'b' with 'd'
After a few swaps, the prefix will already be reversed, and the rest of the string remains untouched. This is the key insight behind the optimal solution.
First, we need to locate the character 'ch' in the string. This step is exactly the same as in the brute force approach. We loop through the string to find the first occurrence of 'ch'. If 'ch' is not found, there’s nothing to reverse, and we simply return the original string. Once we find 'ch', we know its position (index). This tells us where the prefix ends. Now, we can use the two-pointer technique to reverse the prefix efficiently.
To get the whole intuition behind the Two-Pointer Approach to reverse the string
You can refer to this articles' optimal approach -> Reverse String
Approach
Step 1: Initialize Variables
We will initialize two pointers, left and right.
- left will start from the beginning of the string (index 0).
- right will start from the index of the first occurrence of character ch.
Step 2: Traverse the String to Find the First Occurrence of 'ch'
We iterate through the string to find the first occurrence of the character ch.
- For each character, compare it with ch.
- If a match is found, we store the index as right and stop the search.
- If ch is not found, return the original string word as no reversal is needed.
Step 3: Reverse the Prefix Using Two Pointers
Once the index of the first occurrence of ch is found, we will reverse the portion of the string from index 0 to index (inclusive) in place.
- Initialize two pointers: left = 0 and right = index (the index where ch was found).
- Swap the characters at positions left and right.
- Increment left and decrement right until left is no longer less than right.
Step 4: Return the Result
After reversing the prefix in place, the string is modified directly. We simply return the modified string as the result, which now has the reversed prefix followed by the rest of the string unchanged.
Let us understand this with a video,
Dry Run
Input:
word = "abcdefd"
ch = "d"
Initialization:
word = "abcdefd"
ch = "d"
index = -1 (to store the index of the first occurrence of 'd')
left = 0 (to point to the start of the string)
right = 3 (to point to the index of the first occurrence of 'd')
Step 1: Find the First Occurrence of 'd'
We start iterating through the string "abcdefd" to find the first occurrence of 'd'.
Iteration 1 (i = 0):
word[0] = 'a'
'a' is not equal to 'd', so we continue to the next iteration.
Iteration 2 (i = 1):
word[1] = 'b'
'b' is not equal to 'd', so we continue to the next iteration.
Iteration 3 (i = 2):
word[2] = 'c'
'c' is not equal to 'd', so we continue to the next iteration.
Iteration 4 (i = 3):
word[3] = 'd'
'd' is equal to 'ch', so we set index = 3, and the loop ends.
At this point, we have found the first occurrence of 'd' at index 3. We set right = 3.
Step 2: Reverse the Prefix from Index 0 to Index 3 Using Two Pointers
Now, we reverse the part of the string from index 0 to index 3 in place using the two pointers left and right.
Iteration 1:
left = 0, right = 3
We swap word[left] ('a') with word[right] ('d').
word = "dbcfea"
Increment left to 1 and decrement right to 2.
Iteration 2:
left = 1, right = 2
We swap word[left] ('b') with word[right] ('c').
word = "dcbfea"
Increment left to 2 and decrement right to 1.
At this point, left is greater than right, so we stop reversing.
Step 3: Return the Result
Since we have modified the word in place, the result is directly obtained from the modified word.
Final result = "dcbaefd"
Final Output:
"dcbaefd"
Code for All Languages
C++
class Solution {
public:
string reversePrefix(string word, char ch) {
// Find the index of the first occurrence of 'ch'
int index = -1;
for (int i = 0; i < word.length(); i++) {
if (word[i] == ch) {
index = i;
break;
}
}
// If 'ch' is not found, return the original string
if (index == -1) {
return word;
}
// Use two pointers to reverse the prefix in-place
int left = 0, right = index;
while (left < right) {
swap(word[left], word[right]);
left++;
right--;
}
return word;
}
};Java
class Solution {
public String reversePrefix(String word, char ch) {
// Find the index of the first occurrence of 'ch'
int index = -1;
for (int i = 0; i < word.length(); i++) {
if (word.charAt(i) == ch) {
index = i;
break;
}
}
// If 'ch' is not found, return the original string
if (index == -1) {
return word;
}
// Use two pointers to reverse the prefix in-place
char[] wordArray = word.toCharArray(); // Convert string to char array for in-place modification
int left = 0, right = index;
while (left < right) {
char temp = wordArray[left];
wordArray[left] = wordArray[right];
wordArray[right] = temp;
left++;
right--;
}
return new String(wordArray); // Convert the char array back to string and return
}
}
Python
class Solution:
def reversePrefix(self, word: str, ch: str) -> str:
# Find the index of the first occurrence of 'ch'
index = -1
for i in range(len(word)):
if word[i] == ch:
index = i
break
# If 'ch' is not found, return the original string
if index == -1:
return word
# Convert the string to a list for in-place modification
word_list = list(word)
# Use two pointers to reverse the prefix in-place
left, right = 0, index
while left < right:
word_list[left], word_list[right] = word_list[right], word_list[left]
left += 1
right -= 1
# Convert the list back to a string and return
return ''.join(word_list)
Javascript
var reversePrefix = function(word, ch) {
// Find the index of the first occurrence of 'ch'
let index = -1;
for (let i = 0; i < word.length; i++) {
if (word[i] === ch) {
index = i;
break;
}
}
// If 'ch' is not found, return the original string
if (index === -1) {
return word;
}
// Convert the string to an array for in-place modification
let wordArray = word.split('');
// Use two pointers to reverse the prefix in-place
let left = 0, right = index;
while (left < right) {
let temp = wordArray[left];
wordArray[left] = wordArray[right];
wordArray[right] = temp;
left++;
right--;
}
// Convert the array back to a string and return
return wordArray.join('');
};
Time Complexity: O(n)
Finding the Index of ch: O(n)
We iterate through the string word to find the first occurrence of ch. In the worst case, we traverse the entire string, which contains n characters. Each comparison of a character takes O(1), so the total time complexity for this step is O(n).
Reversing the Prefix: O(k)
Once the index of ch is found, we reverse the substring from index 0 to index k using the two-pointer approach. This involves swapping characters, and the number of swaps is proportional to the index k. The time complexity for this step is O(k), where k is the position of the character ch in the string.
Final Time Complexity: O(n)
Since the length of the string is n, and the operations for finding the index and reversing the prefix each contribute to O(n) complexity in the worst case, the overall time complexity remains O(n). The dominant term is O(n), as k can be at most n. Hence, the total time complexity of the algorithm is O(n).
Space Complexity : O(1)
Auxiliary Space Complexity: O(1)
The auxiliary space refers to the extra space used by the algorithm aside from the input. In this case, we are only using a few integer variables: index, left, and right to keep track of positions. These variables take constant space, O(1). The string word is modified in place, so no additional storage is required for creating a new string or array. Therefore, the auxiliary space complexity is O(1).
Total Space Complexity: O(n)
The total space complexity includes both the input (the string word) and the auxiliary space. The input string word takes O(n) space, where n is the length of the string. Since we are not using any additional space proportional to the size of the input (apart from the few constant variables), the total space complexity is O(n).
Learning Tip
Now we have successfully tackled this problem, let's try these similar problems.
Given an input string s, reverse the order of the words.A word is defined as a sequence of non-space characters. The words in s will be separated by at least one space.
Return a string of the words in reverse order concatenated by a single space.
Note that s may contain leading or trailing spaces or multiple spaces between two words. The returned string should only have a single space separating the words. Do not include any extra spaces.
Given a string s, reverse only all the vowels in the string and return it.
The vowels are 'a', 'e', 'i', 'o', and 'u', and they can appear in both lower and upper cases, more than once.