Instagram System Design

Let’s understand some key features of Instagram.
Instagram is a popular social media app that allows users to share photos and videos from their lives. Some key things about Instagram:
- Users can post photos and videos to their Instagram feed that followers can view. Posts can be filtered and edited.
- Users have a profile page that shows all their posts as well as profile info like bio, website, etc.
- Users can follow other users to see their posts in their feed. Users can have followers and be followed.
- Users can like and comment on posts by others. Posts have view counts.
- Hashtags allow users to discover new people and posts of interest. Users can search hashtags.
- Instagram Direct allows users to send private messages with photos/videos.
- Instagram Stories allow sharing ephemeral photos/videos that disappear after 24 hours.
- In-app cameras allow easy posting of content instantly.
So in essence, Instagram is a platform to share visual media and engage with friends, family, brands, creators, or even strangers with similar interests.
In an interview setting, it’s best to focus on key Instagram features and simplify the overall design. Trying to cover every feature in depth would be difficult within a 45 minute time constraint. The interviewer wants to assess your system design capabilities. They don’t expect you to design every aspect of Instagram perfectly. Choose 2–3 core features to design and explain your approach. This allows you to highlight your skills effectively for the interviewer within the limited time.
The main points are:
- Focus on 2–3 key Instagram features for the design
- Simplify the overall design rather than trying to cover everything
- This makes it feasible to discuss in a 45 minute interview
- The interviewer wants to evaluate your system design skills. In-depth knowledge of every Instagram feature is not vital.
Let’s discuss about the scale and load of Instagram.
- 2 Billion daily active users
- 3.5 Billion user accounts.
- 100 Millions photos getting uploaded per day
- 50 Million videos getting uploaded per day, this number could be much higher after the introduction of reels.
- Some celebrities Cristiano Ronaldo, Lionel Messi, Dwayne Johnson and Virat kohli has enormous following on Instagram
- Cristiano Ronaldo has 610 Million followers
- Virat Kohli has 261 Million followers
Requirements
Functional Requirements
- Post photos and videos
- Add captions and locations to posts
- Follow, unfollow other users
- Like, comment on posts
- Generate feeds or timeline based on followers of user
Non-Functional Requirements
- High availability — minimal downtime
- Scalability to hundreds of millions of active users
- Low latency for all operations like feed loads
- Reliability and fault tolerance of backend.
- Durability of content, any successfully uploaded photo or video should not be lost.
- Eventual consistency on feeds, it is okay if a post is immediately not visible to followers.
- Media storage optimization and compression
- Network bandwidth optimization
- Caching for performance
Capacity estimation
- Assuming average size of an image to be 2 MB and video size to be 200 MB.
- Content (Image/video) storage requirement per day
- 100M photo per day × 2 MB average photo size × 3 replication factor.
- 100 * 10⁶ * 2 * 3 MB => 600 TB per day
- 50M video per day × 100 MB average video size × 3 replication factor
- 50*10⁶ * 100 * 3 MB => 15000 TB per day
- total storage requirement per day is 600 + 15000 TB ≈ 16 PB (petabyte)
- storage requirement for 10 years is 16 * 365 * 10 PB ≈ 59EB (exabyte) - No of writes per second.
- 100M photo and 50M video getting uploaded everyday mean 150M. Comments, likes and follows could be 100x of uploads.
- So 150M * 100 => 15 Billion write request per day.
- 1 Million request per day ≈ 12 request per second
- 15000 Million request per day ≈ 12*15000 => 180K request per second - No of reads per second.
- On social media reads are much higher than writes assuming 100x
- 180000 * 100 request per second => 18 Million request per second - No of machine required in cluster to handle such massive load.
- We can calculate this in 2 ways first by take average no of request per second for read and writes which is 180K and 18M req per second respectively.
- But in practice companies like Instagram prepare themselves for the worst case scenario which is what if every user to sending a request simultaneously.
- 2B requests during peak load.
- Assuming 1 machine can handle 10K requests per second and all the machines are having similar capacity, So to handle 2B requests we need 2*10⁹ / 10³ => 200K machines
High level design components.
Some of the components we need to build such systems are
- Blog Storage like AWS S3 to store photos and videos.
- CDN to deliver photos and videos faster.
- Database to store usersInfo, followersInfo, likes and comments for each posts.
- A cache to serve frequently used data with lower latency.
- Key value store to keep timelines or feeds for each user.
- Load balancer to distribute traffic among machines and databases.
Some of the major APIs of Instagram are as follows.
- Upload a photo or video, lets call it upload a media.
- Follow/unfollow request, A user wants to follow another user.
- Likes or reactions on a post
- Generate feeds for each user based on posts by people user follows.
All the apis can be REST endpoints.
Most of our data such as users, posts, photos/videos uploaded by users, and user follows are relational. We also require high durability for our data. Queries like fetching all followers or posts for a specific user can be easily executed in a SQL database. Therefore, SQL is a good choice as our primary database technology. However, we need to consider scalability, as SQL databases do not inherently provide out-of-the-box horizontal scaling.
To enable horizontal scalability, we can employ database sharding techniques to distribute data across multiple SQL instances. For example, we can shard based on the user_id to ensure all queries and data for a given user exist on a single shard. We can also explore NoSQL databases like Cassandra for their horizontal scaling capabilities. A hybrid SQL and NoSQL approach combining the relational model and scalability may serve Instagram’s needs best.
In reality, Instagram uses PostgresSQL as its primary relational database. However, to scale PostgresSQL to handle Instagram’s massive data volumes, which include billions of rows across core tables, Instagram built a custom sharding solution.
Possible PostgresSQL Schema for Instagram database
CREATE TABLE Users (
userId SERIAL PRIMARY KEY,
name VARCHAR(255),
email VARCHAR(255),
password VARCHAR(255),
profilePhotoUrl VARCHAR(255),
bio VARCHAR(255),
website VARCHAR(255)
);
CREATE TABLE Followers (
followerId INTEGER REFERENCES Users(userId),
followedById INTEGER REFERENCES Users(userId)
);
CREATE TABLE Media (
mediaId SERIAL PRIMARY KEY,
userId INTEGER REFERENCES Users(userId),
mediaType VARCHAR(255),
fileUrl VARCHAR(255),
thumbnailUrl VARCHAR(255),
timestamp TIMESTAMP,
location VARCHAR(255)
);
CREATE TABLE Posts (
postId SERIAL PRIMARY KEY,
userId INTEGER REFERENCES Users(userId),
caption VARCHAR(255)
);
CREATE TABLE PostMedia (
postId INTEGER REFERENCES Posts(postId),
mediaId INTEGER REFERENCES Media(mediaId)
);
CREATE TABLE Likes (
likeId SERIAL PRIMARY KEY,
userId INTEGER REFERENCES Users(userId),
postId INTEGER REFERENCES Posts(postId)
);
CREATE TABLE Comments (
commentId SERIAL PRIMARY KEY,
commentText VARCHAR(255),
userId INTEGER REFERENCES Users(userId),
postId INTEGER REFERENCES Posts(postId)
);In addition to its sharded PostgresSQL architecture, Instagram leverages NoSQL databases like Cassandra, Redis for certain use cases where flexibility and performance are critical.
For example, Cassandra is used to store time series data like metrics, aggregates, and analytics that can be appended independently. The innate scalability, flexibility, and write speed of Cassandra makes it a good fit for high velocity telemetry data.
Redis is used extensively for caching — it stores ephemeral data like feed items, stories, and other content that needs low latency access. By keeping hot content in memory, Redis reduces load on backend stores. Its support for data structures like sorted sets and lists simplifies certain types of application logic as well.
By combining the relational model of PostgresSQL with the speed and scaling capabilities of Cassandra and Redis, Instagram gets the best of both worlds. The hybrid data architecture allows each technology to be optimized for the use case it serves best, improving performance, scalability and reducing system complexity.
Instagram’s PostgresSQL ID generation and sharding strategy.
Instagram needs a unique identifier for entities like post, photo, video, user etc. The typical solution that works for a single database — just using a database’s natural auto-incrementing primary key feature — no longer works when data is being inserted into many databases at the same time.
What are some of requirements for the ID.
- ID should be long Integer rather than a string to geting better performance while indexing and it will be easier to manage as well.
- Sometime IDs needs to be time sortable or we need Causality between them or happend after relation between IDs. Apart from having unique identifiers for events, we’re also interested in finding the sequence of these events. Let’s consider an example where Peter and John are two Instagram users. Neha posts a comment (event A), and Jyoti replies to Neha’s comment (event B). Event B is dependent on event A and can’t happen before it. The events are not concurrent here.
- We need a simple solution to avoid adding additional complex service in our system.
- We need a solution which has lowest possible latency to generate new IDs
Instagram explored some existing solutions like UUID , Twitter’s Snowflake and Global counter using SQL database. But they did not like any of these solutions and created their own solution for this.
Instagrams solution for generating IDs.
Instagram leveraged sharding to generate IDs. They initially sharded their postgreSQL database in multiple (thousands of) logical shards and As load increases they map these virtual shards to physical shards. With this horizontal scaling becomes simpler.
In Postgres there is a features called Schemas (not to be confused with SQL schemas). In a DB instance we can have multiple Schemas and each Schema can have tables.
Each ‘logical’ shard is a Postgres schema in our their, and each sharded table (for example, likes, comments etc) exists inside each schema.
Here is how they used 64 bit to generate unique time sortable IDs.
- The moment they deployed this solution they started a timer with 1 milli second.
- They used 41 bit to time of creation of entity (post, likes etc) and because we reset the time, 41 bits can give IDs for next 41 years.
- 13 bits to represent logical shards, So we have 2¹³ => 8192 logical shards
- 10 bits to represent auto-increment IDs in PostgresSQL, but 10 bits can only hold 2¹⁰ => 1024 IDs. SO we take modulo 1024 of auto incremented ID i.e (autoId) % 1024
Let’s understand this with an example.
Suppose we need to generate a new ID for a post now.
Reader can also perform this exercise.
Current time (while writing this article) in Millisecond is 1698425355026Suppose this sharding feature was launched on 20th Nov 2015 then 20th Nov 2015 as millisecond is 1447957800000.Difference = 250467555026Difference in binary (41 bits ) “00011101001010001000001111001011011010010”We can either randomly choose a shard or based on other factor like userID (userID % 8192) out of 8192 shards let assume it 21562156 in binary “0100001101100”In shard no 2156 we insert a new entry in post table and get the auto Increment ID suppose auto Increment ID is 75877686auto ID is 75877686 % 1024 => 310310 in binary “0100110110”Let combine all these 3 ids to create a unique 64 bit id250467555026 << (64 -41) | 2156 << (64 - 41 - 13) | 310 => 2101074135833751862orWe can simply concatenate all the binary strings00011101001010001000001111001011011010010010000110110001001101102101074135833751862 is our unique 64 bit ID for the post and this is the ID that we store in PostgreSQL as postId.
While fetching the post for a given ID we can extract ShardID first which is basically a Schema in postgresSQl Schema then we run following query
SELECT * from db3.schema2156.posts where postID = 2101074135833751862;
For many use cases where system needed to fetch simple key value, Instagram uses Redis to improve performance.
Redis is an in-memory high performant key value store, it provides powerful aggregate types like sorted sets and lists. It has a configurable persistence model, where it background saves at a specified interval, and can be run in a master-slave setup.
Suppose we need to find userID for a mediaID. We can store this in redis mediaID as key and userID as value. Redis is also used to store user feeds where key is userID and value is a sorted list of feeds for that user.
Instagram uses Redis hashes which can reduce the data size which needs to stored in redis. Instagram was able to achive approx 77% reduction in cache size using redis hashes.
Generating Timelines: Two Approaches
There are two methods to generate timelines for users:
Pull-Based Solution: Understanding User Interests
In the pull-based solution, we first identify the users a specific user follows. We then collect recent posts from these followed users, utilizing a custom ranking and sorting strategy. This process results in a curated list of posts tailored to the user’s preferences. This personalized timeline is generated on-demand and can be served to the user in a paginated manner.
Pros
- Better user experience as user gets all the recent posts.
- We needs to perform this operation onDemand i.e only when user want to see the timeline.
Cons
- Higher latency as we are generating when user request it if someone follows a lot of people then generating timeline for user can be time taking. Also Instagram is a read heavy system higher latency mean bad user experience.
Push-Based Solution: Real-Time Content Updates
In the push-based approach, we maintain a dynamic timeline list for each user. When a user publishes a new post, we instantly update the timelines of all users following that person. This real-time update ensures that users receive the latest content as soon as it is available. By directly adding new posts to users’ timelines, we guarantee that the timeline is always up-to-date for every user.
Pros
- Lower latency as timeline is readily available for each user.
Cons
- A celebrity like Ronaldo publish a post who has 610 Million followers so as soon as he publish a post that post needs to updated in 610 Million timelines which can put huge load on server and Imagine if Ronaldo publish 100 posts in short span of time.
Hybrid solution.
We can use both solutions to generate timeline whenever a user publish a post with few followers (we can decide on threshold value let say few thousand) then we can push his post into timelines of his followers Else we do not push into timelines of followers.
While generating timeline for a specific users we can split the users that he follows into 2 categories normal users and celebrity users ( let say who has more then 5k followers). Then we use pull based solution to fetch all the recent post of celebrities and then we can combine this with his existing list of posts which was generated by pushing recent post of normal user he follows.
How do we maintain counts and likes on celebrity post in realtime?
Instead of fetching count by running queries on database we can maintain a counter for attributes like viewCount, likesCount etc.
High level design
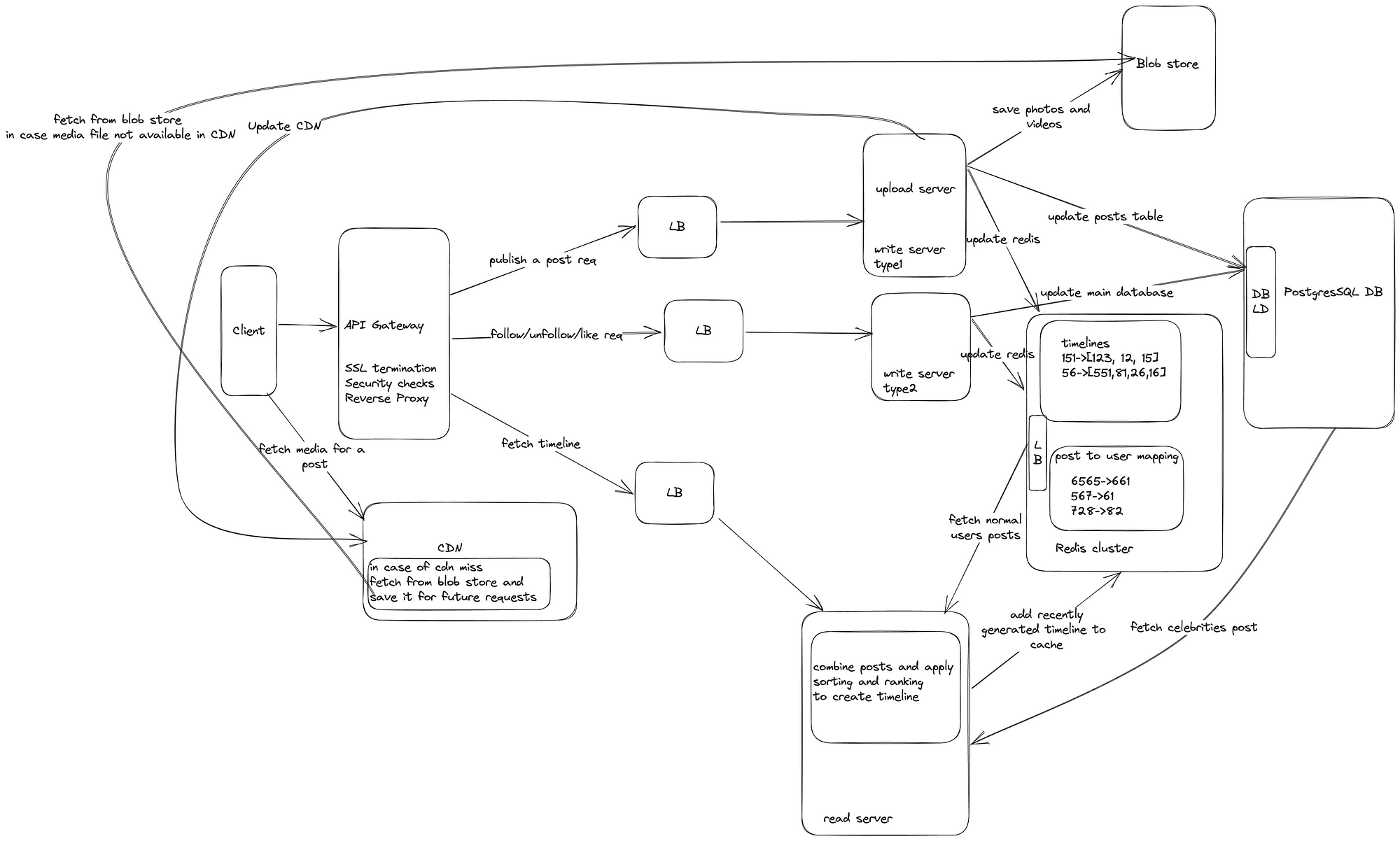
Thank you for taking the time to read. Feel free to connect with me on LinkedIn if you require any assistance! I’m more than happy to help with your interview preparation or provide guidance for your career.