Design Pastebin

What is pastebin?
Pastebin is a website where you can paste and save text online for a set period of time.
To use Pastebin, you go to the website and paste your text into a box. Then you can choose how long you want the text to be available — from months to years.
Pastebin will save your text and generate a unique URL for it. You can share this URL with others so they can view your text. After the set time expires, the URL will no longer work and your text will be deleted from Pastebin.
The main purposes of Pastebin are to store text temporarily and share it easily with others. It allows you to share text online without needing to have your own website or server.
Let’s say our website is paste.mywebsite.com
Ask clarifying questions
Ask open-ended questions to gain a deeper understanding of the problem. These types of questions also support developing both functional and non-functional requirements for our system.
Some common questions regarding pastebin
- Is there any limit on the size of text?
Yes, Let assume user can paste up to 1MB of text - How granular the expiry can we?
User only has 3 options month, year or forever - Do we also have title for our paste?
Yes - Do we need to provide option of choosing custom ID?
Yes, that’s a useful feature - Do we have premium users as well?
Yes, we can have different tiers of users with different usage limit. - Are we having an access layer through user can share paste with specific set of user or make it private, or only authenticated users can access paste links?
It’s a good to have, but to limit the scope we can skip this feature - Can a user use pastebin without login
Yes, we can refer them as guest users - What scale we are expecting?
Expecting 10M links getting generated everyday.
Readers please add more clarifying question in comment section.
Coming up with requirements for this system.
After we understood the problem we should be coming up with system’s requirement and confirms with interviewer if we are making right assumptions.
Here are some requirements of pastebin
Functional requirements
- Users can paste and save text.
- Users get a unique URL to share the pasted text
- There has to be a default expiry of may be 1 month and user having an option to override this.
- Expired links should not be accessible by any user.
- Logged in users can see history of paste links generated by them.
- Premium users can create more paste links compared to guest users.
Non functional requirements
- Availability: Our system needs to be highly available otherwise users won’t be able access pastes. We cannot afford downtime.
- Lower Latency: For better user experience reads should have minimal latency, Even for write requests we should try to achive lower latency.
- Non predictable IDs: IDs we used to create short URLs should not be predictable.
- Scalability: Our system should to horizontally scalable to handle increase in traffic. Reads and writes can be scaled independently.
- Rate limiting: Rate limiting to avoid system abuse by guest users and also handles quota for premium users.
Resource estimation
We need to provide an approximate estimation of hardware required to handle the expected scale.
Approximation Tips
No of seconds in a day 24*60*60 = 86400
1M req per day => 10⁶/86400 ≈ 12 req per second
Load Assumptions:
- 10M write req per day
- On average each user generating 10 links per day so we assume 1M daily active users (DAU)
- Assuming reads are 10 time more than writes, So we are getting 100M reads per day
- Assuming peak traffic is 10X of average traffic
1M req / day ≈ 12 req/sec
10M req/day ≈ 120 req/sec
peak 10X of average ≈ 1200 req/sec - Write are 1200 req/sec and read is 12000 req/sec during peak hour.
Storage estimation:
- Up to 1 MB of text is allowed. But very few users will paste 1MB Data
50% of pastes are <5kB (2kB average)
30% of pastes are 5–25kB (15kB average)
20% of pastes are 25–100kB (60kB average)
So average 20KB is a good assumption - Other fields like title, created_at, userInfo is negligible compared to text data.
- We will storing actual text data to a blob storage like AWS S3 and will add S3 link to the object instead of text data. Here we can optimize by using some threshold let say if data is less than 1 KB then we can add data directly to our object else store data in Blog storage and add link to our object. With this strategy we can assume that object size would be up to 1KB
- Total storage requirement for 10 years.
10M Objects of 1KB per day
10⁶ * 1KB data per day ≈ 1*10³ MB per day ≈ 1GB per day
10 year => 10*365 GB 3650 GB ≈ 3.6TB
replication factor of 3 to avoid data loss 3.6*3 => 11 TB of data in our database. - Blob storage requirement
Assuming 80% of request has text more than 1KB
80% of 10M is 8*10⁵
8*10⁵ * 20 KB data per day ≈ 16 * 10⁶ KB ≈ 16 GB data per day
10 year estimation => 10*365*16 GB ≈ 58400 GB ≈ 58.4 TB ≈ 60 TB
Blog storage like S3 uses replication factor of 3 they store data in 3 locations to avoid data loss
Total storage would be 3*60 TB ≈ 180 TB - Cache Estimation
We can assume that 20% of URLs contributes to 80% of the traffic.
We have 100M read req/day
20% of 100M is 20*10⁶ objects
Size of object is 1KB then we need cache of size 20*10⁶ * 1 KB => 20 GB
Bandwidth estimation:
- During peak hours expect write req / sec is 1200
1200 req/sec average object size is 20KB
1200 * 20 KB => 24000 KB ≈ 24 MBPs is the incoming data. - Similarly because reads are 10 times more than write request, The total outgoing data would be 240 MBPs
High Level Design
Prior to delving into the design phase, it’s essential to explore various database options along with their advantages and disadvantages. When contemplating the choice of a database, it is imperative to analyze our data as well as the access patterns, including query, read, and write patterns.
For a pastebin application, the primary data comprises pastes, which adhere to the following structure:
"pasteId": {
"title": "",
"text": "",
"createdAt": "",
"createdBy": "",
"expiry": ""
}
It’s noteworthy that the text field in the above structure can accommodate content of up to 1MB.
Query Pattern:
- Two main operations:
Find paste by ID
Delete all expired pastes (requires a less-than query)
Read/Write Pattern:
- Peak load: 1200 req/sec
- Read operations: 10 times the rate of write operations
- Read rate: 12000 req/sec - Low latency for read
Let’s explore few databases
- MongoDB: A popular NoSQL document database that stores data in flexible JSON-like documents. It scales well and has features like indexing and query optimizations that would be useful for searching/retrieving pastes quickly.
- PostgreSQL: A relational open source database that uses SQL for defining and manipulating data. It offers reliability, scalability, and data integrity. The JSONB datatype can be used for storing document style pastes Flexibly.
- DynamoDB: A fully managed NoSQL database offered by AWS. It provides solid state drives for low latency and high throughput performance. Backups and scaling are handled automatically as traffic changes.
- Elasticsearch: Often used as a search engine database, but also capable of document style storage. Can index paste contents for quick and advanced search queries across all user pastes on a site.
As you see we have many good options available for pastebin database.
Here is my choice of database
- Using a key value store like DynamoDB as main storage.
- Using Blob storage like AWS S3 for storing text greater then 10KB
- Using redis along with subscribing to expired events (https://redis.io/docs/manual/keyspace-notifications/). This is to delete all the expired pastes.
Other storage systems
- CDN to improve response time
- Bloom filter to check if a paste possibly exists or not.
High level design
Read flow
- Client Request for Paste:
— A user initiates a request to access a specific paste on the Pastebin system. - CDN Check:
— The client checks its local cache or the CDN cache to determine if the requested paste is already available. - Cache Hit (Paste Available in CDN):
— If the requested paste is found in the CDN cache and is considered fresh based on caching rules, the CDN directly serves the paste to the user. This is a cache hit. - Cache Miss (Paste Not Available in CDN):
— If the paste is not available in the CDN cache or is considered stale, the CDN forwards the request to the Pastebin’s origin server to fetch the latest version of the paste. This is a cache miss. - Pastebin Origin Server Processing:
— The Pastebin’s origin server processes the request, check if paste available using bloom filter, retrieves the requested paste, and sends it back to the CDN. - CDN Update:
— The CDN caches the newly fetched paste and serves it to the user. The CDN may also update its cache based on caching rules, including setting a new Time-to-Live (TTL) for the paste. - User Receives Paste:
— The user receives the requested paste, whether it’s directly from the CDN cache or after the CDN fetched it from the Pastebin origin server. - Subsequent Requests:
— For subsequent requests for the same paste within the TTL period, the CDN checks its cache first. If the paste is still considered fresh, it serves it directly to the user (cache hit). If the paste is stale, it may fetch a new copy from the Pastebin origin server (cache miss) and update its cache.
Write flow
- Client Request to Create Paste:
— A user initiates a request to create a new paste on the Pastebin system. - API Gateway Check Rate Limiter:
— The request passes through the API Gateway, which checks against a rate limiter to ensure that the client is not making requests too frequently. - API Gateway Forwards Request to Write Load Balancer:
— If the request passes the rate limiting check, the API Gateway forwards the request to the Write Load Balancer, distributing incoming write requests across multiple Write servers. - Write Server Checks Key Availability:
— The Write Load Balancer directs the request to a Write server. The Write server checks if there are available keys for creating new pastes. If keys are exhausted, it requests a new set of keys from the Key Generation Service. - Write Server Writes Data to Key-Value Store:
— The Write server uses a key-value store (e.g., database) to store the paste metadata. If the paste data is less than or equal to 10KB, the data is directly stored as the value associated with the key. - Large Paste Data Handling:
— If the paste data is more than 10KB, the Write server writes the data to an Object Store and stores a reference to the Object Store in the key-value store. - Update Bloom filter
— After successfully storing the paste metadata, the Write server updates a Bloom filter with the unique identifier (e.g., hash) associated with the paste. This step enhances the efficiency of membership tests for checking whether a particular paste exists in the system. - Write Server Writes Key to Redis with Expiration:
— The Write server writes the key to a Redis database with an expiration time. This allows the system to automatically delete the paste metadata after a specified period. - Paste Deletion Service Subscribed to Redis Expiration Event:
— A Paste Deletion Service is subscribed to Redis key expiration events. It monitors for key expiration events to initiate the deletion of paste metadata and associated data. - Write Server Returns Key as Response to Client:
— The Write server, upon successful storage of the paste metadata, returns the key associated with the created paste as a response to the client. The client can use this key to retrieve or delete the paste in the future.
This write flow ensures that new pastes are securely created, and the associated metadata is efficiently stored, whether within the key-value store or in an object store for larger data. The integration of Redis for key expiration events allows for automatic cleanup of expired paste metadata.
Bloom filter:A Bloom filter is a space-efficient probabilistic data structure, which store set of keys and query to check if key is present returns either “possibly in set” or “definitely not in set”.
High level design diagram
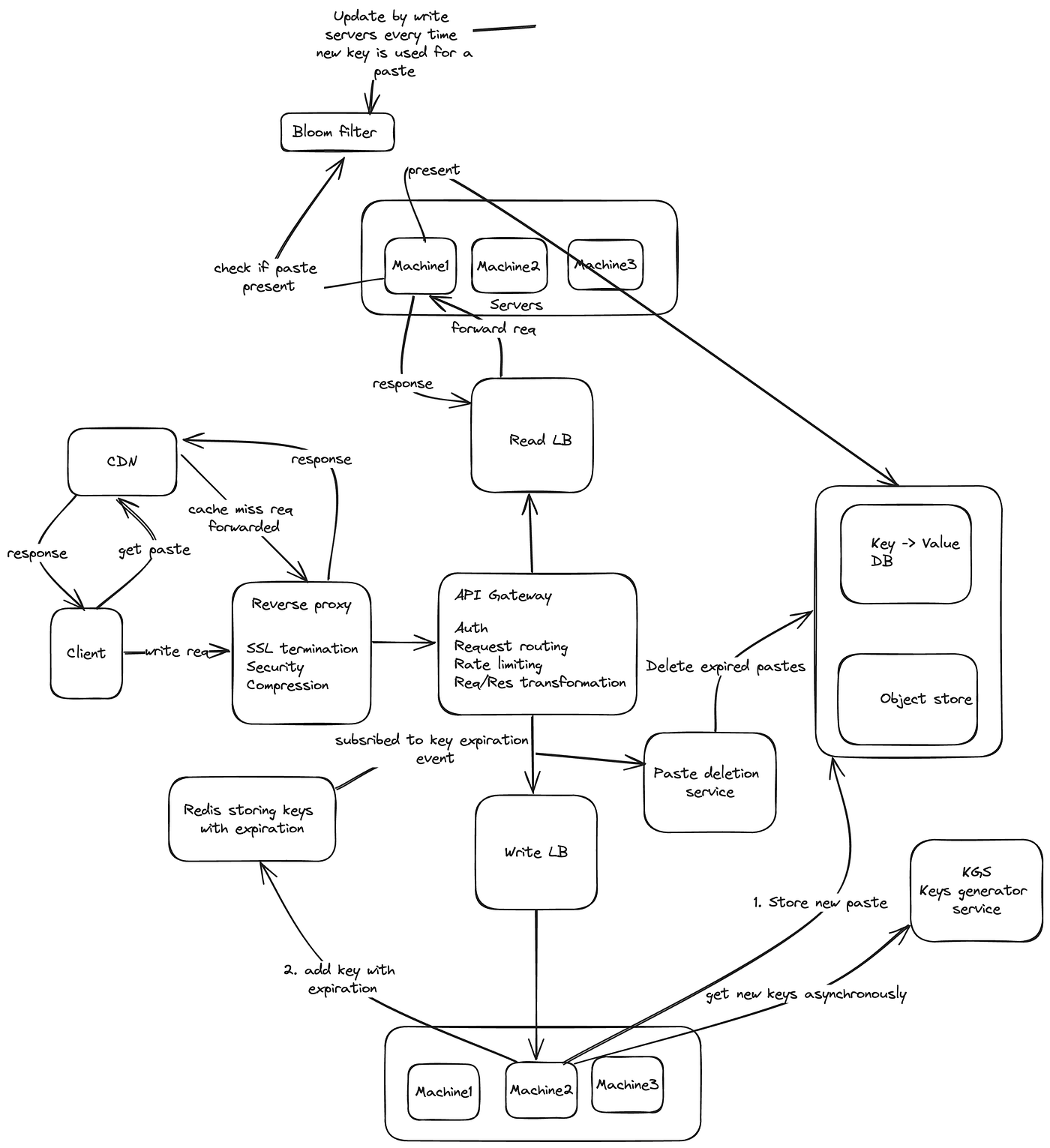
Important Note:
This represents one potential solution. An alternative approach involves architecting a Pastebin system with an SQL database, a common design choice found in various online Pastebin implementations. Handling the removal of expired pastes can be accomplished through mechanisms like a cron job. While it’s true that many databases internally leverage Bloom filters for query optimization, there is merit in treating it as a distinct component within the system. This segregation enhances clarity in system comprehension.It’s crucial to acknowledge that this design isn’t a definitive solution for a Pastebin system; it comes with its set of advantages and drawbacks. The essence of system design interviews lies in presenting diverse approaches, demonstrating a comprehensive understanding of each solution’s strengths and weaknesses. The objective isn’t to propose a flawless design but to showcase the ability to analyze multiple design choices and articulate the rationale behind them.
Deep dive
After engaging in a high-level design discussion, interviewers commonly direct the conversation towards a more in-depth exploration of specific system components. Within the scope of this particular problem, numerous elements spark interest, including rate limiting, key generation, and the removal of expired pastes. For the purpose of our focused investigation, we will delve into the intricacies of the Key Generation Service.
The Key Generation Service plays a pivotal role in the functionality of the Pastebin system. It is tasked with ensuring a continuous supply of unique keys for new paste creations. Leveraging this service involves managing key exhaustion scenarios, where the service dynamically requests and integrates a fresh set of keys when the existing pool is depleted. An effective Key Generation Service contributes not only to the seamless creation of pastes but also to the overall resilience and scalability of the system.
Let’s look at some of the attribute we needed in our keys
- Compact PasteId Length: Maintain a concise PasteId length, ideally ranging from 8 to 12 characters, ensuring the creation of short URLs for ease of sharing.
— Enhanced Usability: The compact PasteId facilitates user-friendly sharing, contributing to the system’s overall usability. - Integer Mapping for Query Performance: Correlate the PasteId to an integer to improve query performance. Integer-based indexes excel in speed compared to their string-based counterparts, optimizing data retrieval efficiency.
— Optimized Query Speed: Integer mapping enhances query performance, resulting in faster and more efficient data retrieval operations. - Randomization Property: Implement a randomization property in the key generation strategy to enhance security. Avoiding predictable sequences, such as 1, 2, 3, ensures robust protection against unauthorized access attempts.
— Security Reinforcement: The incorporation of a randomization property strengthens the system’s security by discouraging predictable key assignment, mitigating potential security risks. - Rapid Key Generation and Distribution: Prioritize the speed of key generation and distribution across all write servers. A fast and efficient key generation process is vital to ensuring seamless operations and responsiveness within the Pastebin system, accommodating high traffic scenarios and user demands.
A possible approach for key generation service
Range Generation Service Explained:
- Long Integer Capacity: The use of a long integer in our key generation approach allows for a vast range of values, up to ²⁶⁴. This extensive range ensures that a substantial number of keys can be generated, potentially lasting for an extended period, even with a high rate of key consumption, such as 10 million keys per day.
No of years to exhaust all the keys
Number of Years=Total keys / Keys Per Day×Days Per YearTotal Keys
Number of Years=2⁶⁴ / 10⁷×365264 ≈ 5,059,541,324 years
- Lightweight, Highly Available Service: To manage key distribution efficiently, a lightweight and highly available service is implemented. This service is responsible for maintaining a record of the point up to which keys have been distributed, ensuring resilience and availability.
- Key Distribution Request: When a write server requires a new set of keys, it makes a request to the highly available key generation service. This service, being lightweight, is capable of promptly responding to such requests.
- Range Distribution:The key generation service, upon receiving a request, sends a designated range of keys to the requesting write server. This range is determined based on the current distribution point, and it is transmitted to the write server to be locally maintained.
- Local Key Management: The write server keeps track of the distributed key range locally. As the write server nears the exhaustion of keys within its range, it proactively requests a new set of keys from the key generation service.
- Random Key Selection: Write servers have the flexibility to autonomously select any key from the locally maintained range. This random selection adds an element of unpredictability to the key assignment process, contributing to system security and integrity.
By employing this range-based key generation strategy, the system ensures longevity in key availability, maintains high availability and responsiveness, and facilitates scalable key distribution across multiple write servers.
In summary, the Pastebin system design intricately balances key components to ensure user-friendly functionality and efficiency. Leveraging an SQL or NO-SQL database, thoughtful key generation, and additional security measures like a Bloom filter, the system stands robust. The inclusion of a Content Delivery Network enhances global content delivery, demonstrating adaptability and foresight. As we navigate the intricacies of large data handling, rate limiting, and content expiration, the Pastebin system exemplifies a versatile and effective solution, embodying the essence of modern web application design.
Food for thoughts:
- Implementing premium user features: Strategies for catering to premium users, including exclusive benefits or advanced functionalities, to enhance user experience and generate revenue.
- Enabling custom URLs: Exploring options to allow users to personalize their paste URLs, such as paste.com/rohit-notes1, providing a more tailored and user-friendly experience.
- Pastebin as a service: Delving into the possibilities of offering Pastebin services tailored for corporate use, addressing unique needs such as enhanced security, collaboration features, and centralized management.
Thank you for taking the time to read my article. I’m delighted that you stayed engaged until the end.